DeepSeek-R1 is making waves as a powerful open-source AI model with 671B parameters in logical reasoning and problem-solving. However, deploying it could be discouraging due to its hefty 400GB+ VRAM requirement for the int4 model. Well, not anymore!
The team at Unsloth has achieved an impressive 80% reduction in model size, bringing it down to just 131GB from the original 720GB using dynamic quantisation techniques. By selectively quantising certain layers without compromising performance, they’ve made running DeepSeek-R1 on a budget (See their work here).
In our latest tutorial, we provide a detailed step-by-step guide to host DeepSeek-R1 on a budget with Hyperstack.
Now, let's walk through the step-by-step process of deploying DeepSeek-R1 1.58 Bit on Hyperstack.
Initiate Deployment
Select Hardware Configuration
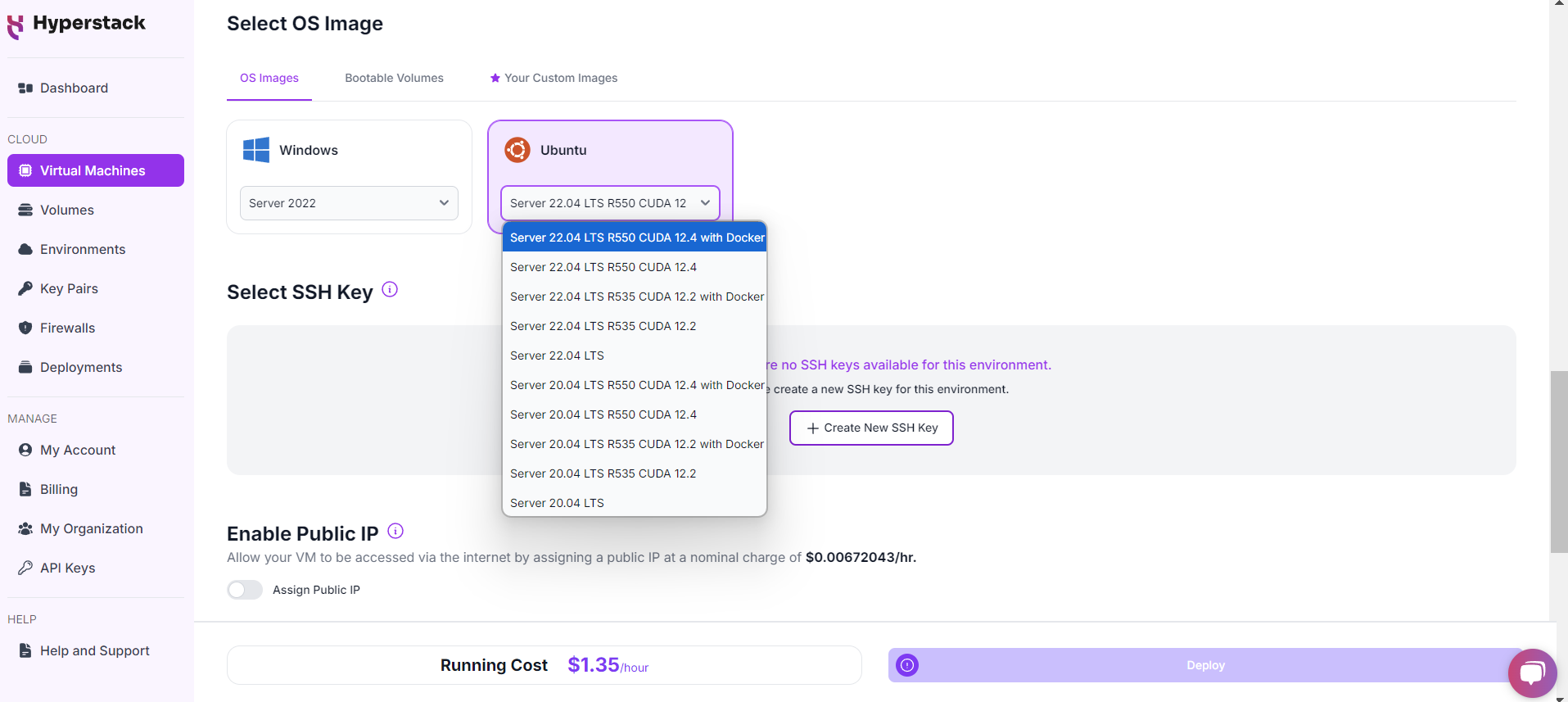
Choose the Operating System
Select a keypair
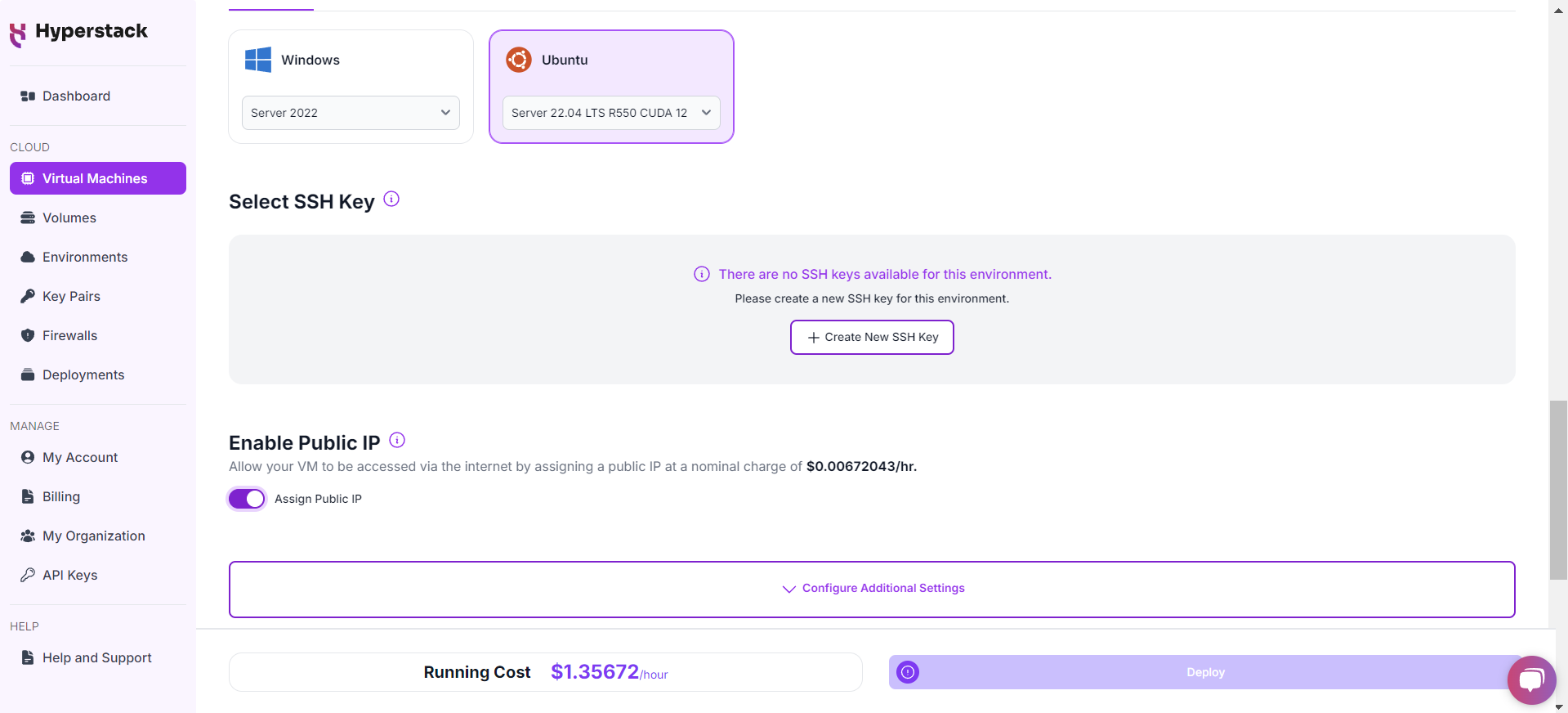
Network Configuration
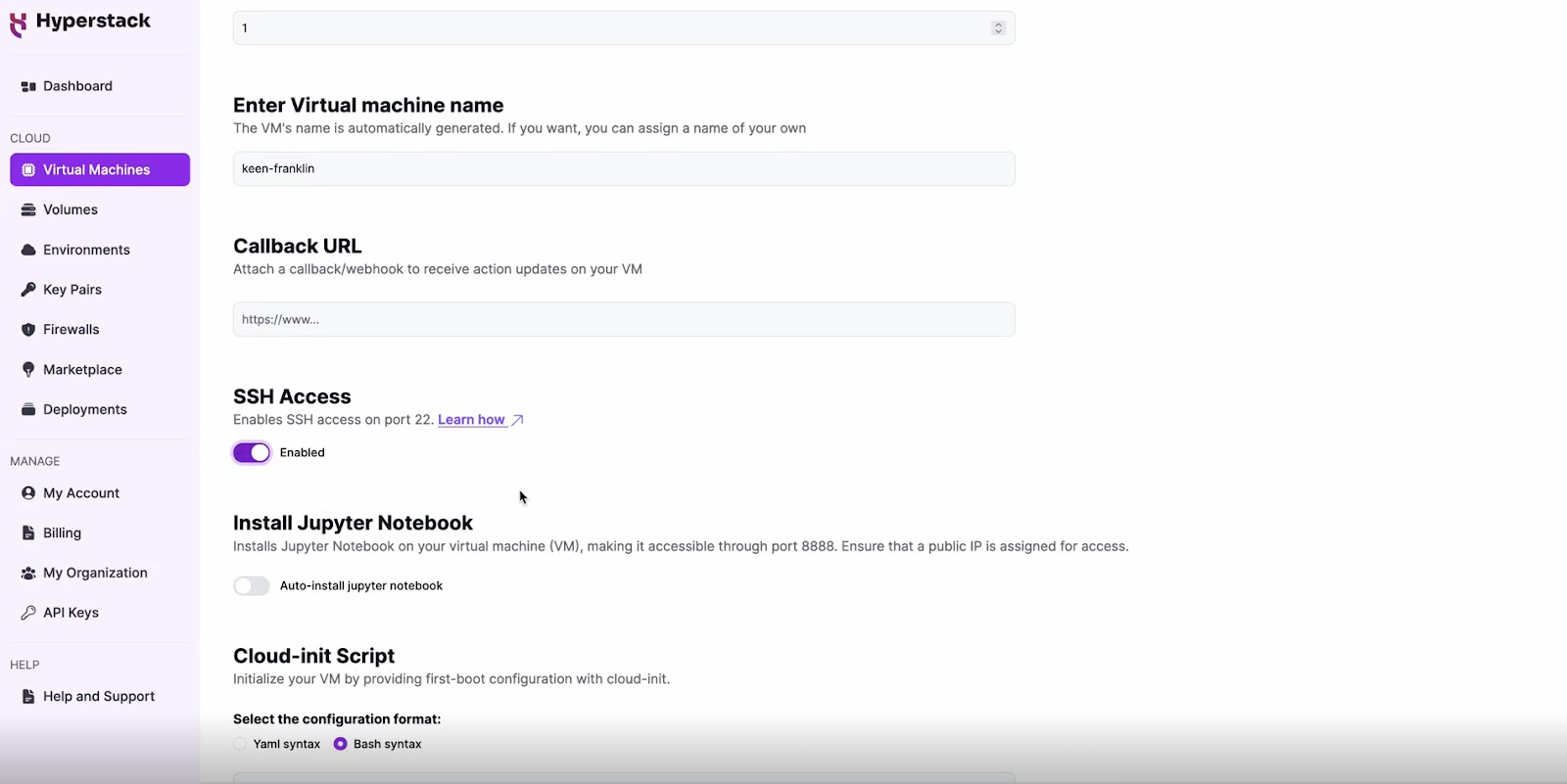
Enable SSH Access
Review and Deploy
Once the initialisation is complete, you can access your VM:
Locate SSH Details
Connect via SSH
Follow the below steps to set up DeepSeek-R1 1.58-bit with Open WebUI:
Connect to your server via SSH.
docker run -d \
-p "3000:8080" \
--gpus=all \
-v /ephemeral/ollama:/root/.ollama \
-v open-webui:/app/backend/data \
--name "open-webui" \
--restart always \
"ghcr.io/open-webui/open-webui:ollama"
# Install Git LFS
sudo apt-get install -y git-lfs
# Download Nix for easy installation of llama-cpp (non-interactively)
echo "Installing Nix..."
sh <(curl -L https://nixos.org/nix/install)
# Add Nix to the PATH.
source ~/.nix-profile/etc/profile.d/nix.sh
# Install llama-cpp.
echo "Installing llama-cpp via nix..."
nix profile install nixpkgs#llama-cpp --extra-experimental-features nix-command --extra-experimental-features flake
# Download huggingface model.
echo "Downloading the DeepSeek model..."
cd /ephemeral/
sudo chown -R ubuntu:ubuntu /ephemeral/
git lfs install
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/unsloth/DeepSeek-R1-GGUF
cd DeepSeek-R1-GGUF
git lfs fetch --include="DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-*.gguf"
git lfs checkout "DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf"
git lfs checkout "DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf"
git lfs checkout "DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf"
# Merge model file parts.
cd DeepSeek-R1-UD-IQ1_S
echo "Merging model parts..."
llama-gguf-split --merge DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf DeepSeek-R1-UD-IQ1_S-merged.gguf
# Move the files to the directory that our OpenWebUI container can access
mkdir -p /ephemeral/ollama/local_models
mv DeepSeek-R1-UD-IQ1_S-merged.gguf /ephemeral/ollama/local_models/DeepSeek-R1-UD-IQ1_S-merged.gguf
# Write the Modelfile with model configuration.
cat < /ephemeral/ollama/local_models/Modelfile
FROM /root/.ollama/local_models/DeepSeek-R1-UD-IQ1_S-merged.gguf
PARAMETER num_ctx 4096
EOF
echo "Creating model DeepSeek-R1-GGUF-IQ1_S inside the Docker container..."
docker exec -it open-webui ollama create DeepSeek-R1-GGUF-IQ1_S -f /root/.ollama/local_models/ModelfilePlease note: For long conversations, Ollama may show errors. Fix this by increasing the context size (num_ctx 4096) above to a higher value. For more info on the issue see here.
To start interacting with your DeepSeek-R1 1.58-Bit, follow the below steps:
Access Your VM Firewall Settings
Enable traffic on port 3000 for your specific IP address. (You can leave this open to all IPs for broader access, but this is less secure and not recommended.) For instructions on changing firewall settings, see here.
In your browser, go to http://[public-ip]:3000. For example: http://128.2.1.1:3000
Set up an admin account for OpenWebUI. Be sure to save your username and password.
5. You’re all set to interact with your self-hosted DeepSeek model.
Disclaimer: Please note that this is a highly quantised version of DeepSeek and output may be unstable.
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying DeepSeek-R1 1.58-Bit:
DeepSeek-R1 is a 671B parameter, open-source Mixture-of-Experts language model designed for superior logical reasoning, mathematical problem-solving and structured thinking tasks, offering high performance in complex inference and decision-making scenarios.
DeepSeek-R1 offers advanced reasoning abilities, reinforcement learning-based training, and open-source accessibility under the MIT license. It includes distilled model variants from 1.5B to 70B parameters.
DeepSeek-R1 is a quantised version of the original DeepSeek-R1 671-billion parameter model.
Sign up at https://console.hyperstack.cloud to get started with Hyperstack.
For hosting DeepSeek-R1 1.58-bit on Hyperstack, you can opt for the NVIDIA L40 GPU. Our NVIDIA L40 GPU is available for $ 1.00 per Hour.
Explore our tutorials on Deploying and Using Llama 3.2 and Llama 3.1
on Hyperstack.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}