The latest DeepSeek-R1 update is making waves across social media with everyone eager to try the new DeepSeek-R1-0528 version available for both the 8 billion parameter distilled model and the full 671 billion parameter model. Its performance is now rivalling top models like O3 and Gemini 2.5 Pro. Explore our latest blog below to start using the updated version.
FYI: Our earlier blog (check it out here) is now automatically running on the newest version.
The latest version of DeepSeek-R1 i.e. DeepSeek-R1-0528 brings minor upgrades to both the 8B distilled and 671B full models with significant improvements on reasoning and inference. The upgraded DeepSeek-R1 model delivers notable improvements in tackling complex reasoning tasks. In the AIME 2025 test, its accuracy has risen from 70% in the earlier version to 87.5%—a clear sign of progress. This improvement is largely due to deeper reasoning: while the previous model used around 12K tokens per question, the new version processes an average of 23 K tokens, allowing for more thorough analysis.
But that's not all, the new version also offers a lower hallucination rate, enhanced function calling capabilities and a more refined experience for vibe coding.
How to Use DeepSeek-R1-0528?Now, let's walk through the step-by-step process of deploying DeepSeek-R1-0528 on Hyperstack.
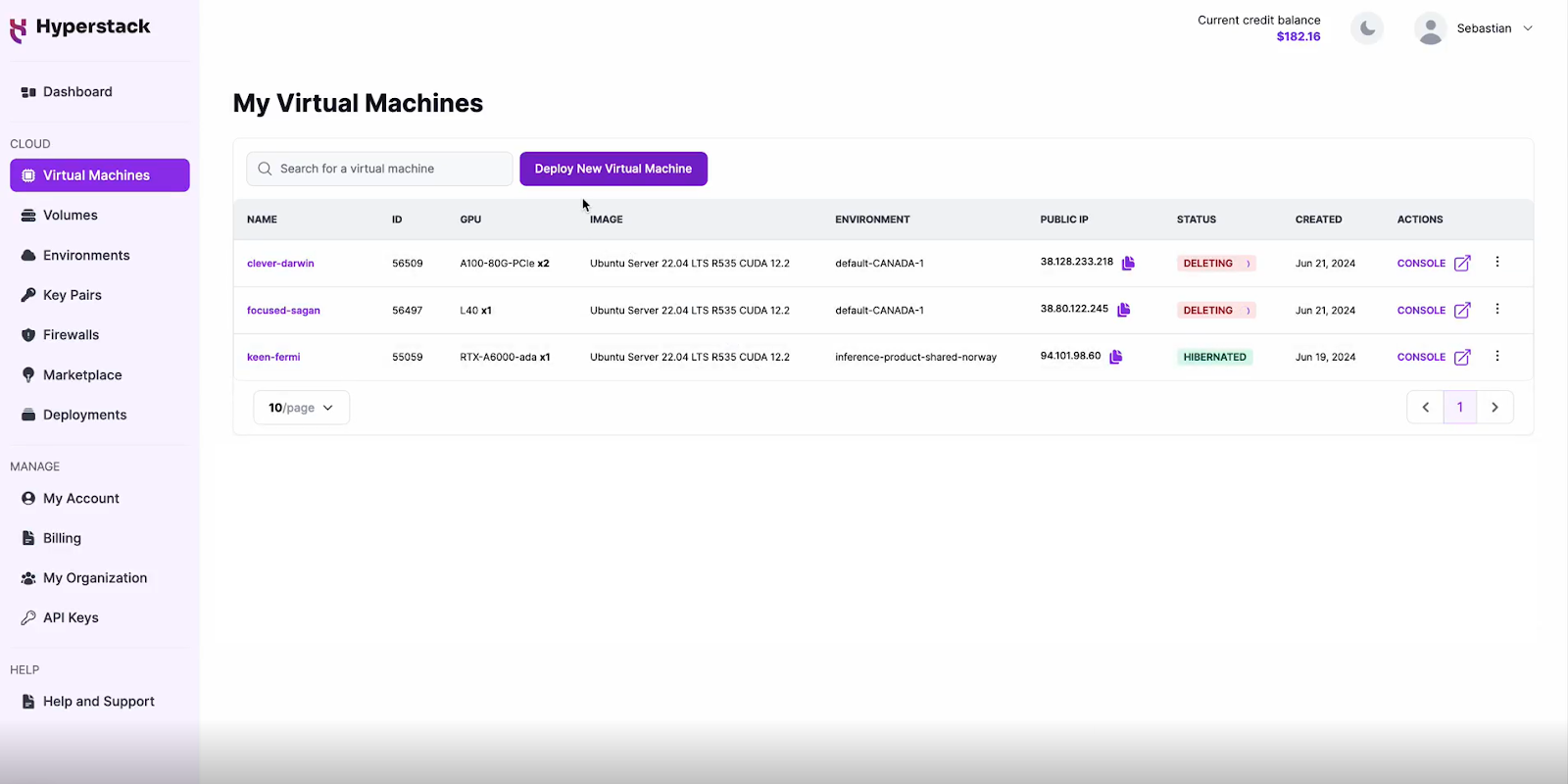
Initiate Deployment
Select Hardware Configuration
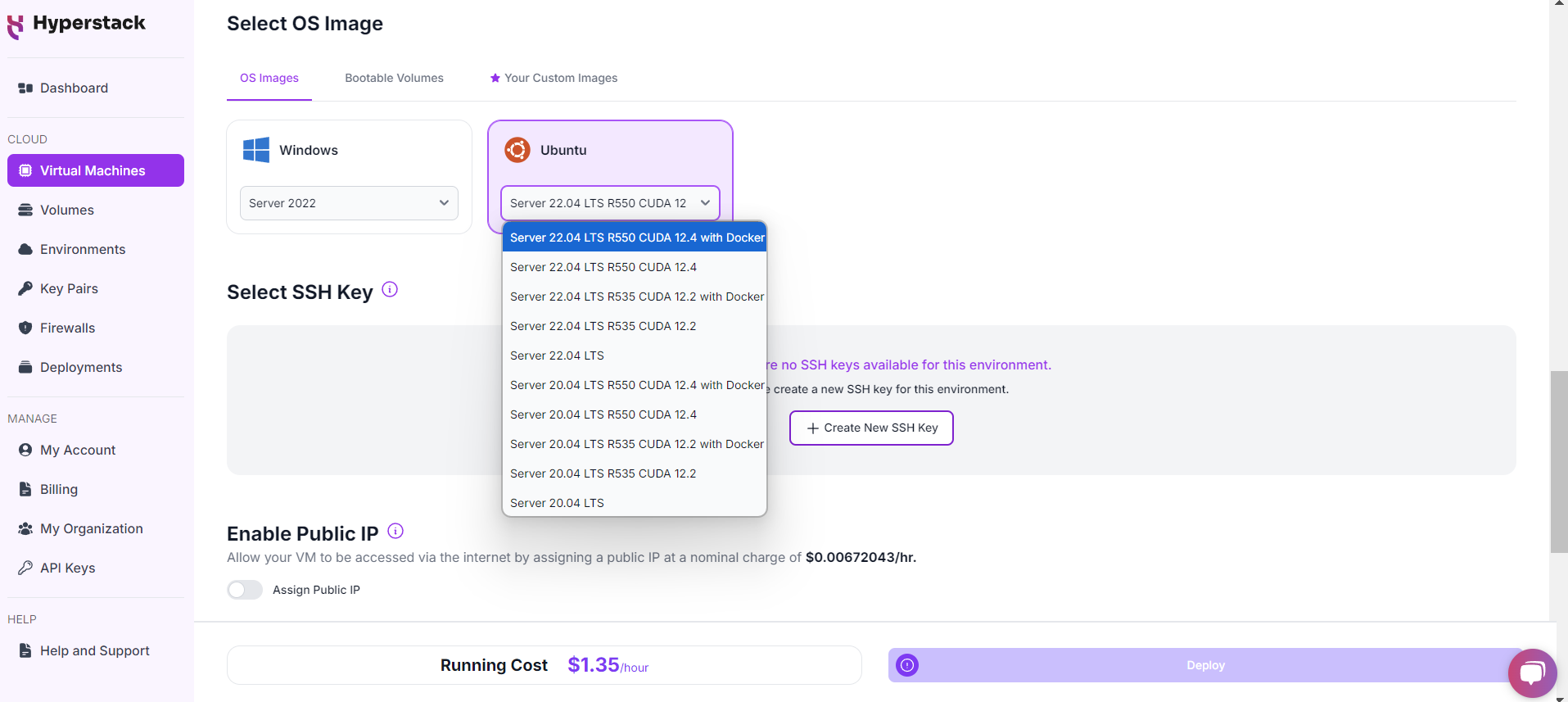
Choose the Operating System
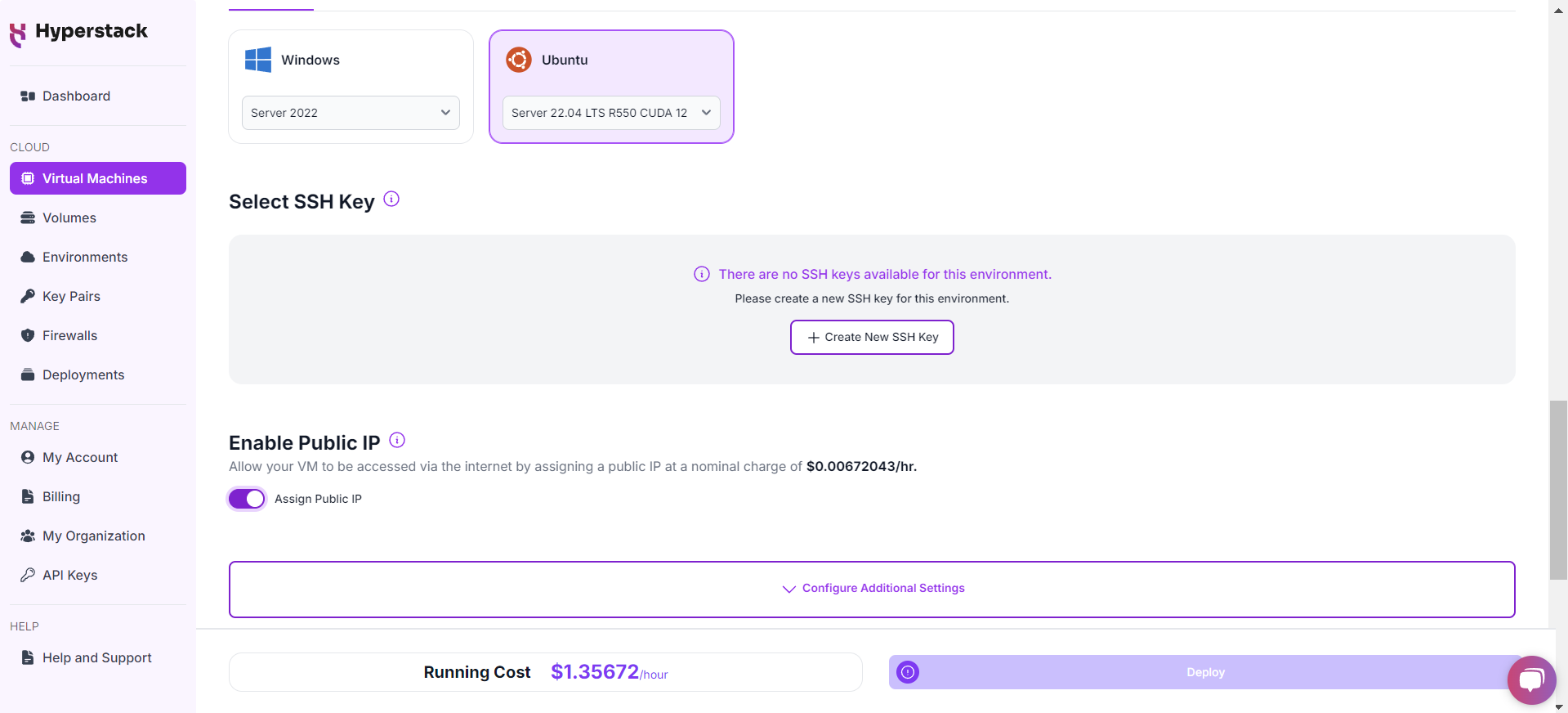
Select a keypair
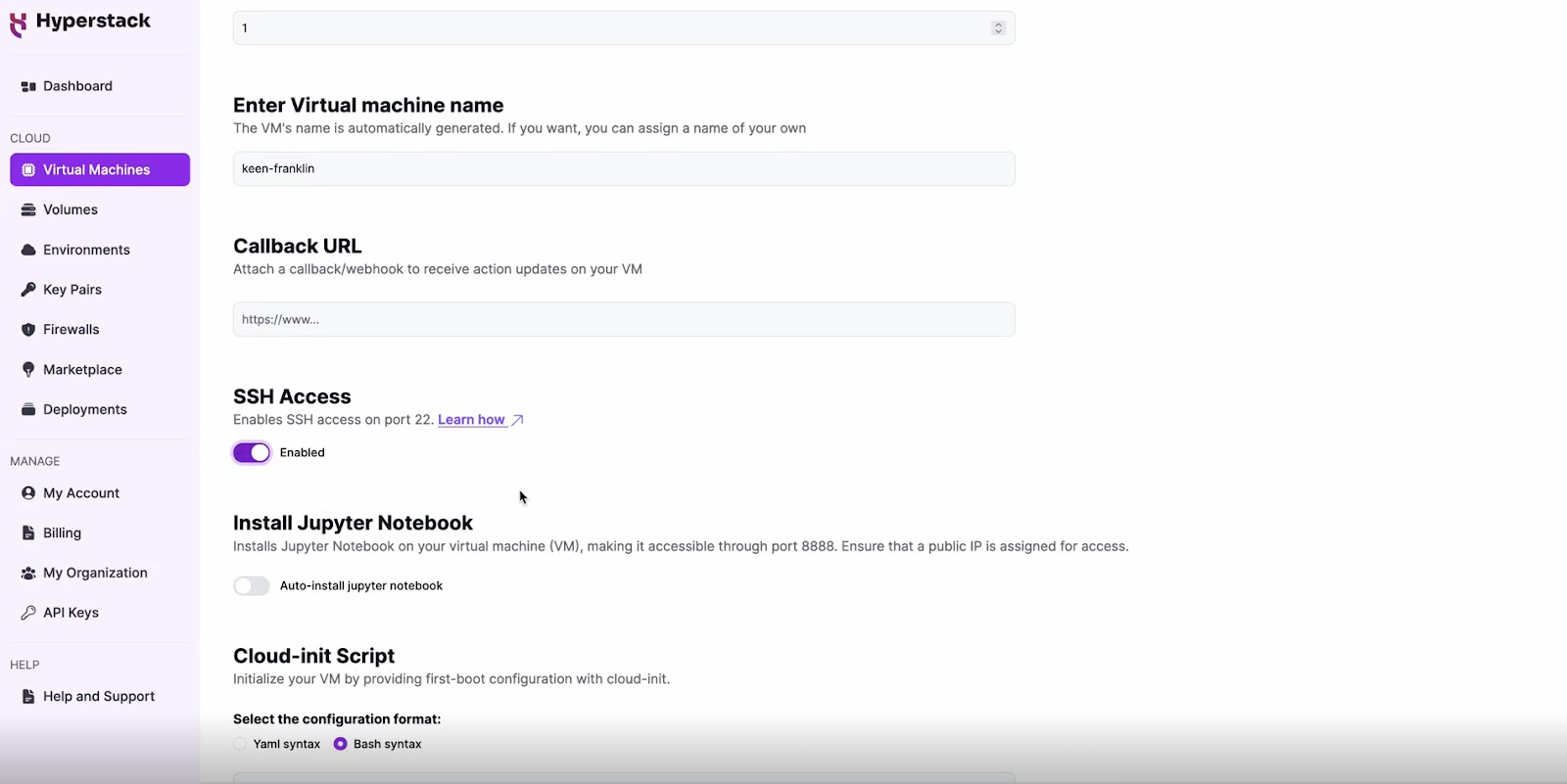
Network Configuration
Enable SSH Access
Review and Deploy
Once the initialisation is complete, you can access your VM:
Locate SSH Details
Connect via SSH
docker run -d \
-p "3000:8080" \
--gpus=all \
-v /ephemeral/ollama:/root/.ollama \
-v open-webui:/app/backend/data \
--name "open-webui" \
--restart always \
"ghcr.io/open-webui/open-webui:ollama"
3. Execute the following command to start downloading DeepSeek-R1-0528 to your machine.
docker exec -it "open-webui" ollama pull deepseek-r1:671b
The above script will download and host the int4 quantised version of DeepSeek-R1 to ensure it fits on a single machine. See this model card for more information.
Open your VM's firewall settings.
Allow port 3000 for your IP address (or leave it open to all IPs, though this is less secure and not recommended). For instructions, see here.
Visit http://[public-ip]:3000 in your browser. For example: http://198.145.126.7:3000
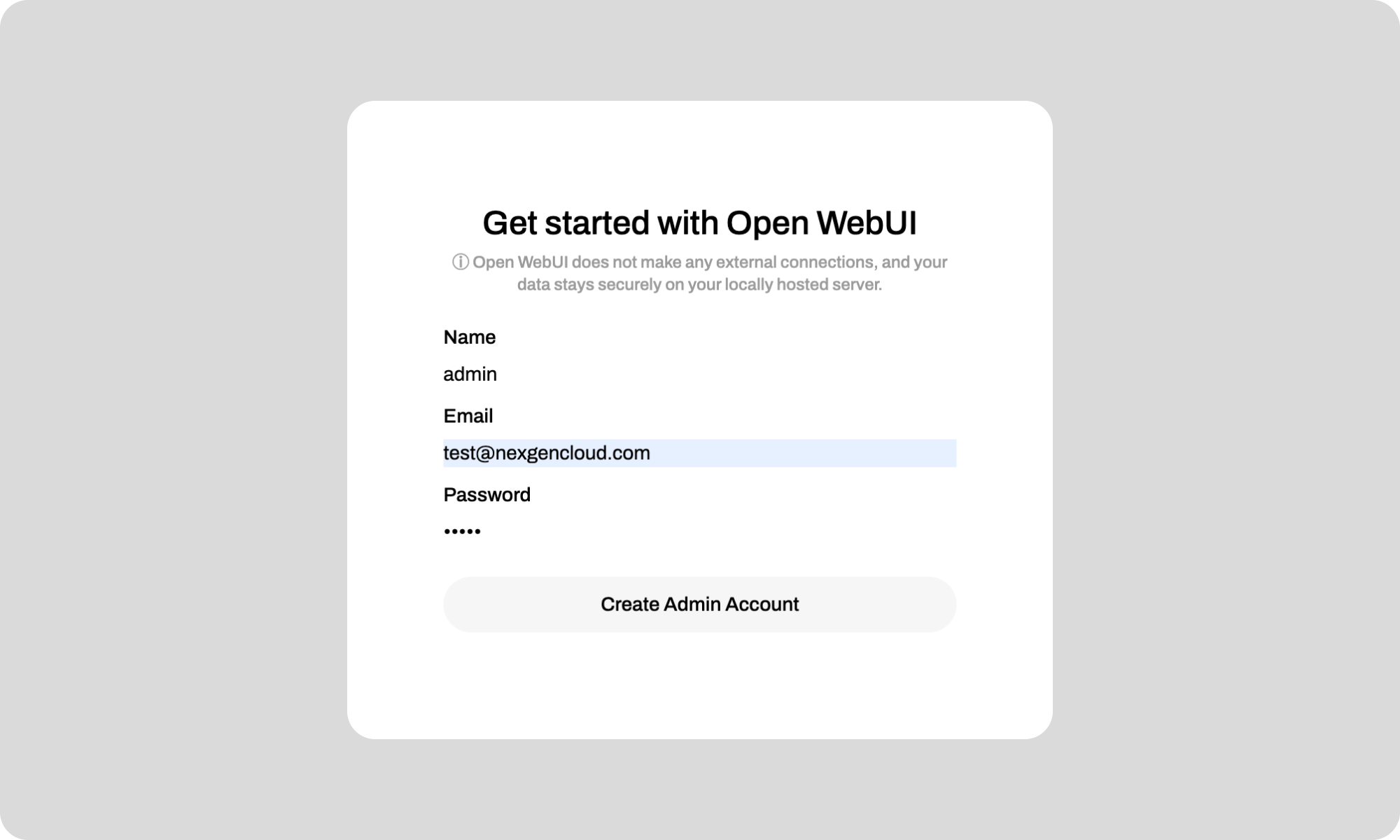
Set up an admin account for OpenWebUI and save your username and password for future logins. See the attached screenshot.
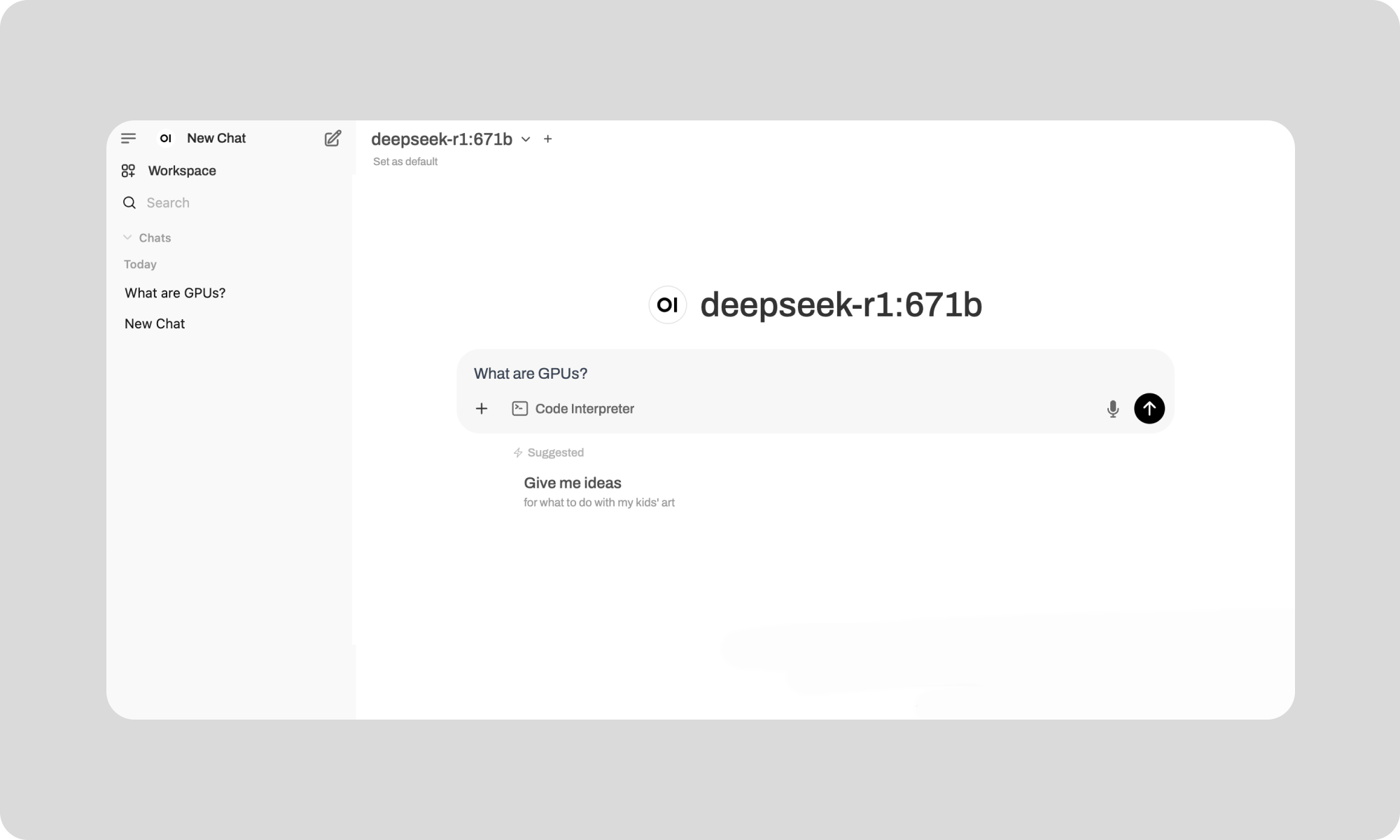
And voila, you can start talking to your self-hosted DeepSeek-R1-0528! See an example below.
Please note: for longer conversations, Ollama might run into errors. To fix these, refer below for instructions on increasing the context size. For more info on the issue see here.
The model is initially set with a context size of 2048, which may be insufficient for longer input prompts or output text. To increase the context size, follow the steps below.
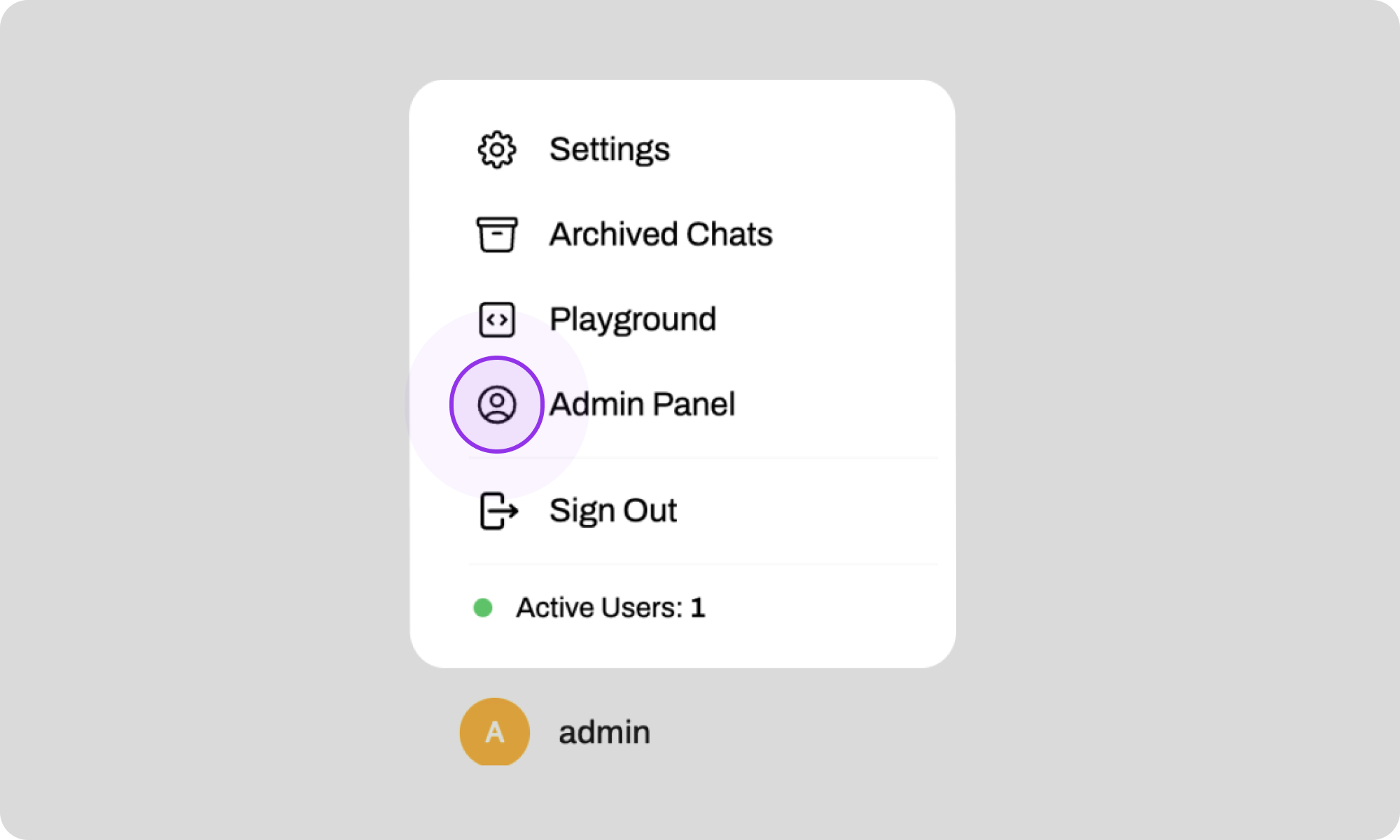
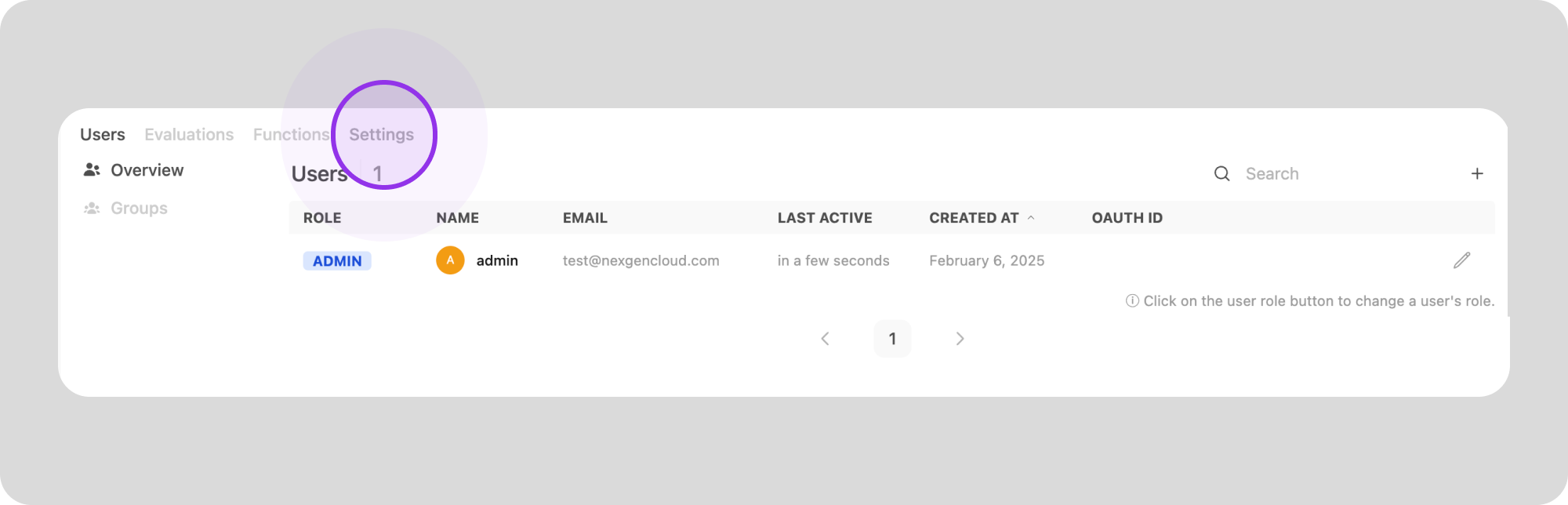
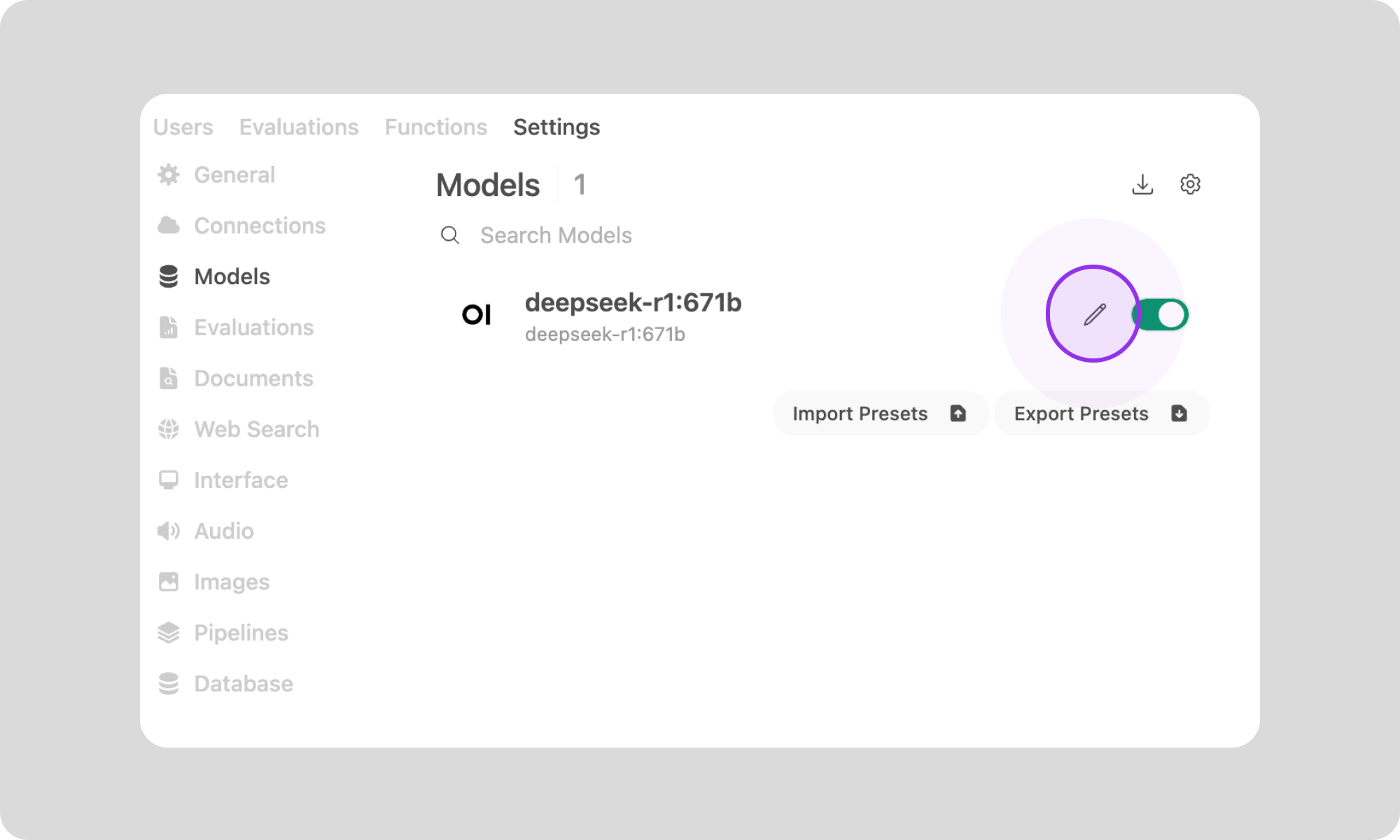
3. Click on 'Models' in the left sidebar. This will take you to an overview of all the models available on your machine.
4. Click on the Pencil icon right of 'DeepSeek-R1-0528'.
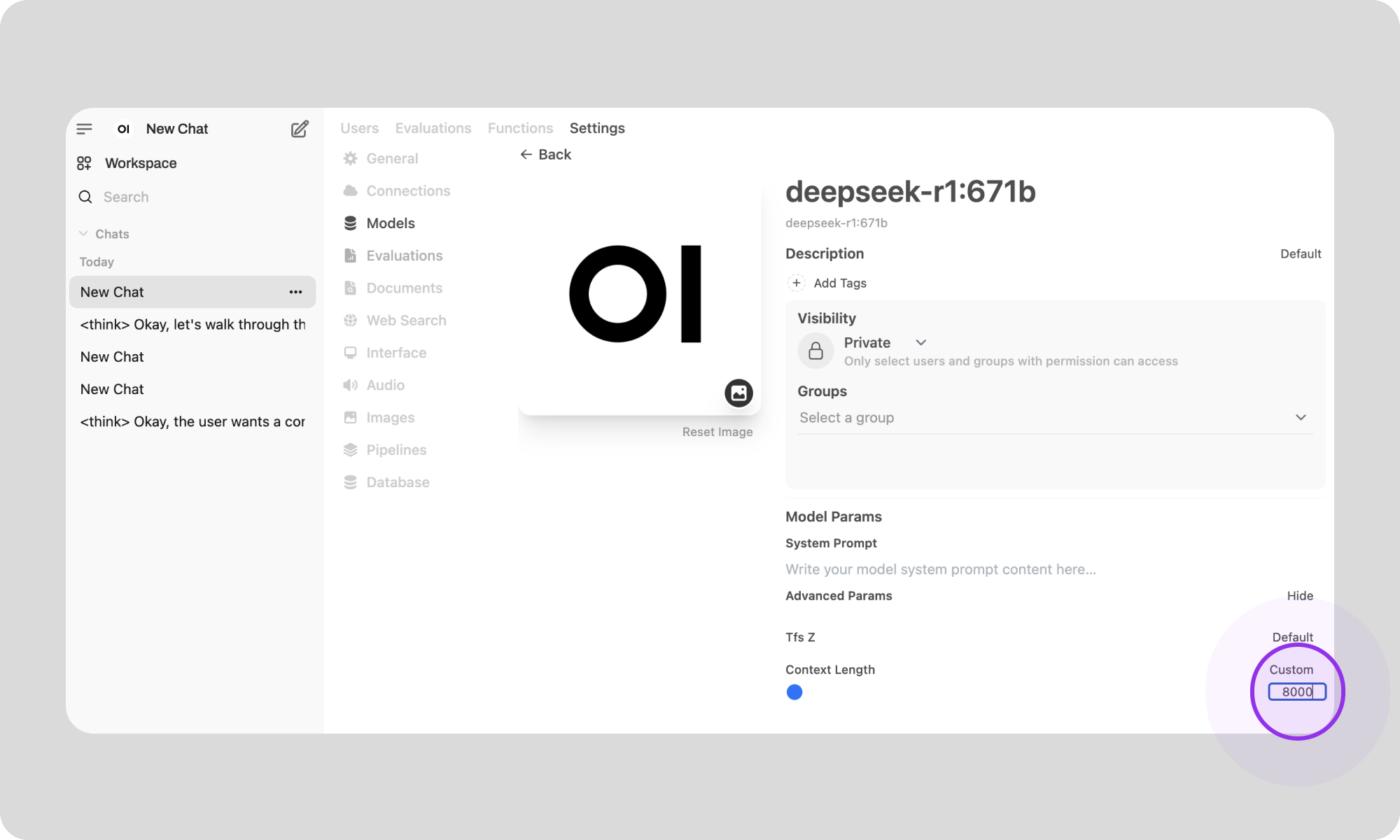
6. Click on 'Advanced params' to find the context length.7. You can now increase the 'Context Length' (e.g. 8192).
Congratulations, now you have DeepSeek-R1-0528 running with a longer context size. This will allow you to have longer conversations and/or talk about more complex subjects.
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying DeepSeek-R1-0528:
DeepSeek-R1-0528 is a 671B parameter open-source Mixture-of-Experts language model designed for high-performance logical reasoning and problem-solving.
The key features of DeepSeek-R1-0528 include:
You can use the "Hibernate" option on Hyperstack to pause your VM and reduce costs when not in use.
Yes, you can adjust the context size via the Open WebUI admin panel for longer input and output sequences.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}