gpt-oss 120B is a powerful open-source large language model containing approximately 116 billion parameters. The model matches the performance of OpenAI’s o3-mini and o4-mini on many benchmarks, making it an ideal choice for advanced AI applications. The best part about the model is its flexibility in deployment. You can run it on a single GPU, though four or eight GPUs deliver optimal performance.
The key features of gpt-oss-120b model include:
116B Parameter MoE Design: The model uses a Mixture of Experts architecture with 5.1B active parameters per token that ensures efficiency without compromising capability.
Small Server Deployment: Runs on a single GPU without the need for quantisation, making it highly accessible.
Extended Context Window: The model also supports a 131K context length, so it can process and understand significantly larger inputs in one go.
If you’re planning to try the latest gpt-oss 120B model, you’re in the right place. Check out our guide below to get started.
Now, let's walk through the step-by-step process of deploying gpt-oss 120B on Hyperstack.
Initiate Deployment
Select Hardware Configuration
For gpt-oss 120B GPU requirements, go to the hardware options and choose either from below:
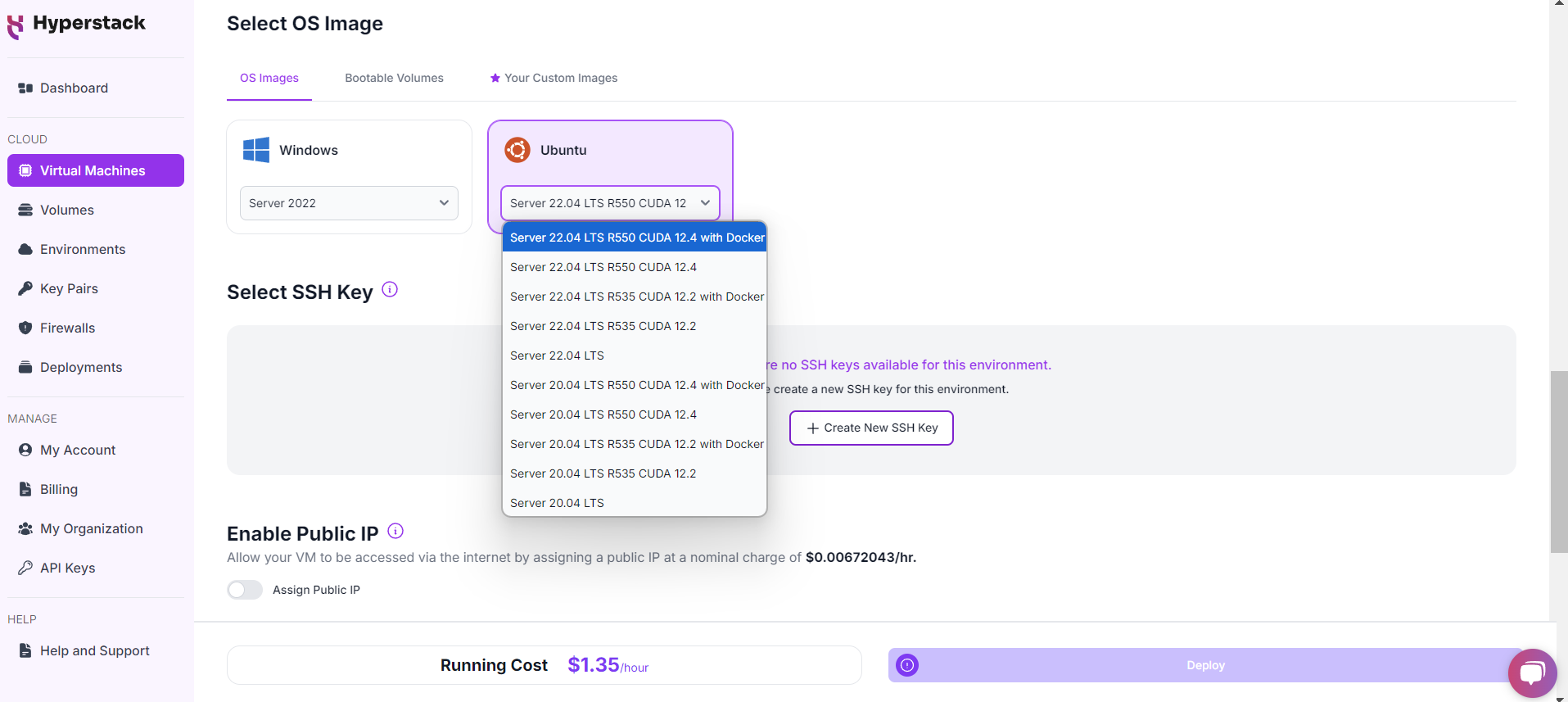
Choose the Operating System
Select a keypair
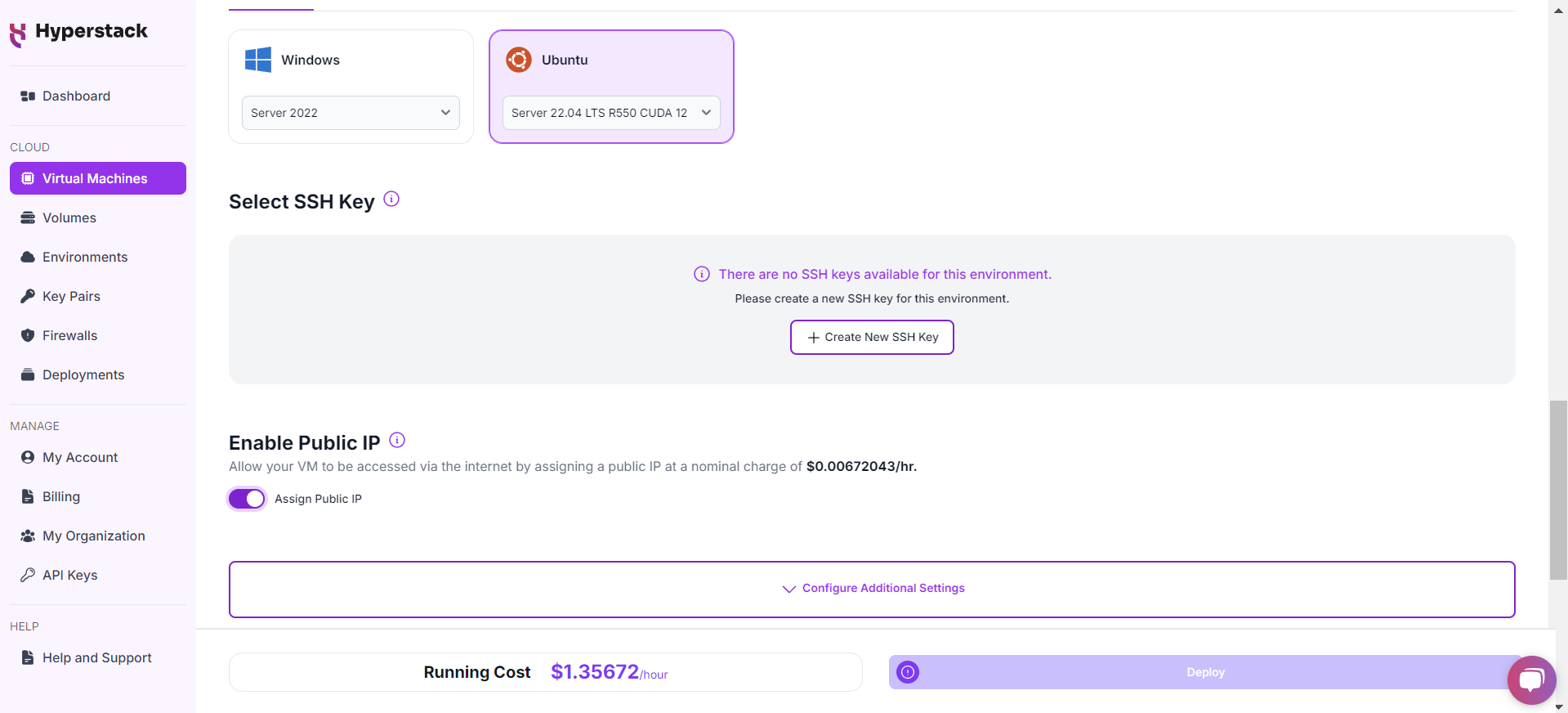
Network Configuration
Enable SSH Access
Once the initialisation is complete, you can access your VM:
Locate SSH Details
Connect via SSH
# 1) Create a docker network
docker network create gpt-oss-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network gpt-oss-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1 -e HF_HOME=/hug vllm/vllm-openai:gptoss --model openai/gpt-oss-120b --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size 1 --gpu-memory-utilization=0.95
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network gpt-oss-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:mainThe above script will download and host gpt-oss 120B. See the model card here: https://huggingface.co/openai/gpt-oss 120B for more information.
Please Note: Because the model is large, downloading and hosting can take a few minutes. You should refresh the OpenWebUI page periodically until it shows the model as loaded.
When running gpt-oss 120B on H100 GPUs, make sure to remove the parameter:
--tensor-parallel-size value based on the number of GPUs in your setup:--tensor-parallel-size 1--tensor-parallel-size 2--tensor-parallel-size 4Following these steps ensures optimal performance and prevents configuration conflicts during deployment.
Open your VM's firewall settings.
Allow port 3000 for your IP address (or leave it open to all IPs, though this is less secure and not recommended). For instructions, see here.
Visit http://[public-ip]:3000 in your browser. For example: http://198.145.126.7:3000
Set up an admin account for OpenWebUI and save your username and password for future logins. See the attached screenshot.
And voila, you can start talking to your self-hosted gpt-oss 120B! See an example below.
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying gpt-oss 12B:
gpt-oss 120B is an open-source large language model with approximately 116 billion parameters, delivering benchmark results comparable to OpenAI’s o3-mini and o4-mini.
gpt-oss 120B uses a 116B parameter Mixture of Experts design, runs on as few as 2 GPUs without quantisation and supports a 131K context window.
The model is built on a Mixture of Experts (MoE) architecture with 5.1B active parameters per token for efficient, high-performance inference.
gpt-oss 120B supports a 131K token context window, allowing it to handle very large inputs or extended conversations in one go.
For gpt-oss 120B GPU requirements, go to the hardware options and choose either from below:
Yes, it is optimised for small server deployment and can run on as little as 2 GPUs without the need for quantisation.
gpt-oss 120B performs on par with OpenAI’s o3-mini and o4-mini across multiple benchmarks while being open-source and more deployable.
{kind=link}
{kind=link}
{kind=link}
{kind=link}