

TABLE OF CONTENTS
NVIDIA A100 GPUs On-Demand
Key Takeaways
-
GPT-oss 120B is a 116-billion-parameter open-source LLM designed for efficient deployment and advanced reasoning.
-
The model uses a Mixture of Experts architecture to balance performance with computational efficiency.
-
It can run on a single GPU, but 4–8 GPUs optimise speed and handle larger workloads.
-
Supports an extended 131K token context window for processing long-form inputs in one pass.
-
Deployment on Hyperstack involves selecting the appropriate GPU, OS, keypair, and network configuration for seamless operation.
What is gpt-oss 120B?
gpt-oss 120B is a powerful open-source large language model containing approximately 116 billion parameters. The model matches the performance of OpenAI’s o3-mini and o4-mini on many benchmarks, making it an ideal choice for advanced AI applications. The best part about the model is its flexibility in deployment. You can run it on a single GPU, though four or eight GPUs deliver optimal performance.
Key Features of gpt-oss 120B
The key features of gpt-oss-120b model include:
-
116B Parameter MoE Design: The model uses a Mixture of Experts architecture with 5.1B active parameters per token that ensures efficiency without compromising capability.
-
Small Server Deployment: Runs on a single GPU without the need for quantisation, making it highly accessible.
-
Extended Context Window: The model also supports a 131K context length, so it can process and understand significantly larger inputs in one go.
If you’re planning to try the latest gpt-oss 120B model, you’re in the right place. Check out our guide below to get started.
Steps to Deploy gpt-oss 120B
Now, let's walk through the step-by-step process of deploying gpt-oss 120B on Hyperstack.
Step 1: Accessing Hyperstack
- Go to the Hyperstack website and log in to your account.
- If you're new to Hyperstack, you'll need to create an account and set up your billing information. Check our documentation to get started with Hyperstack.
- Once logged in, you'll be greeted by the Hyperstack dashboard, which provides an overview of your resources and deployments.
Step 2: Deploying a New Virtual Machine
Initiate Deployment
- Look for the "Deploy New Virtual Machine" button on the dashboard.
- Click it to start the deployment process.
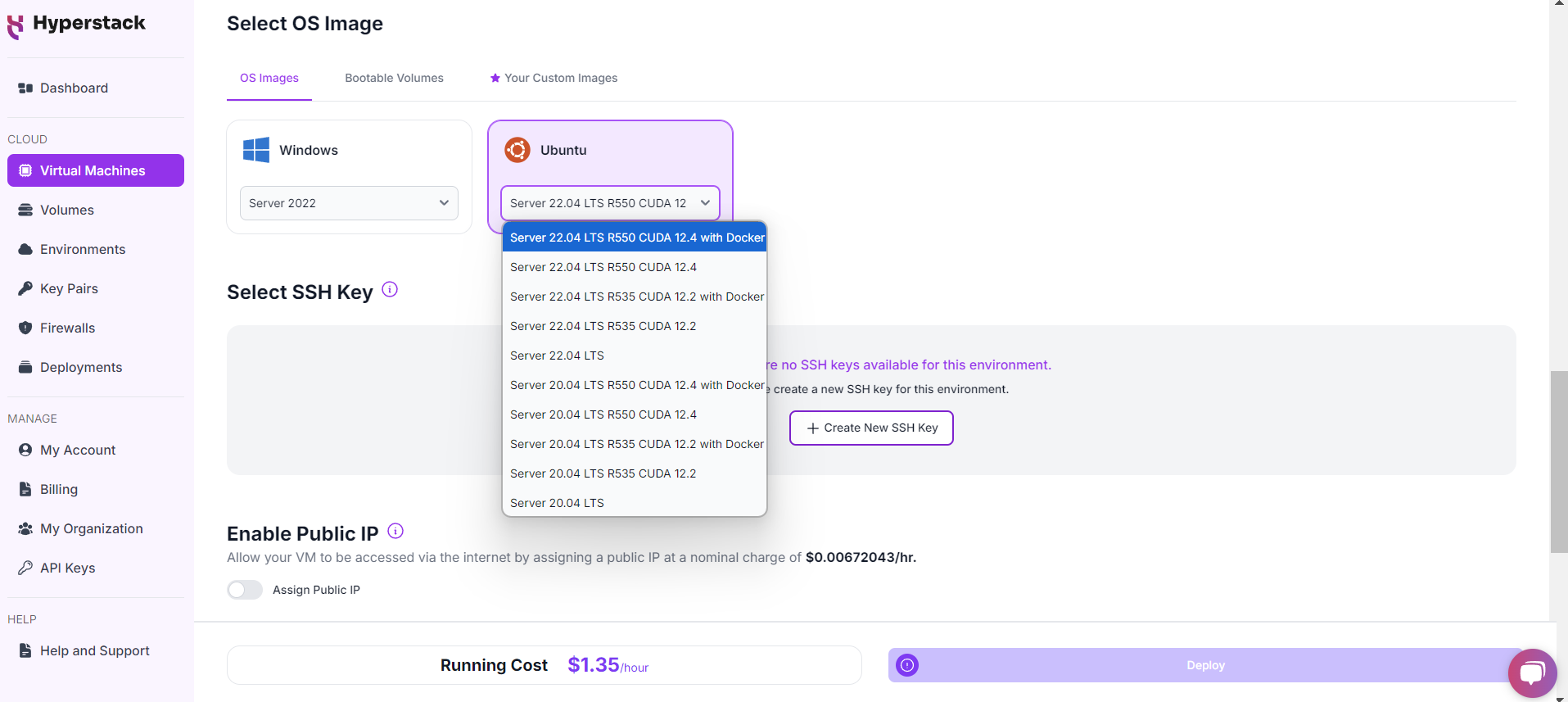
Select Hardware Configuration
For gpt-oss 120B GPU requirements, go to the hardware options and choose either from below:
- 1, 2, 4 or 8 xNVIDIA H100 PCIe (select no. of GPUs)
- 8 xNVIDIA H100 PCIe NVLink
- 8 xNVIDIA H100 SXM
- 2, 4, 8 xNVIDIA L40 (select no. of GPUs)
Choose the Operating System
- Select the "Ubuntu Server 24.04 LTS R570 CUDA 12.8 with Docker".
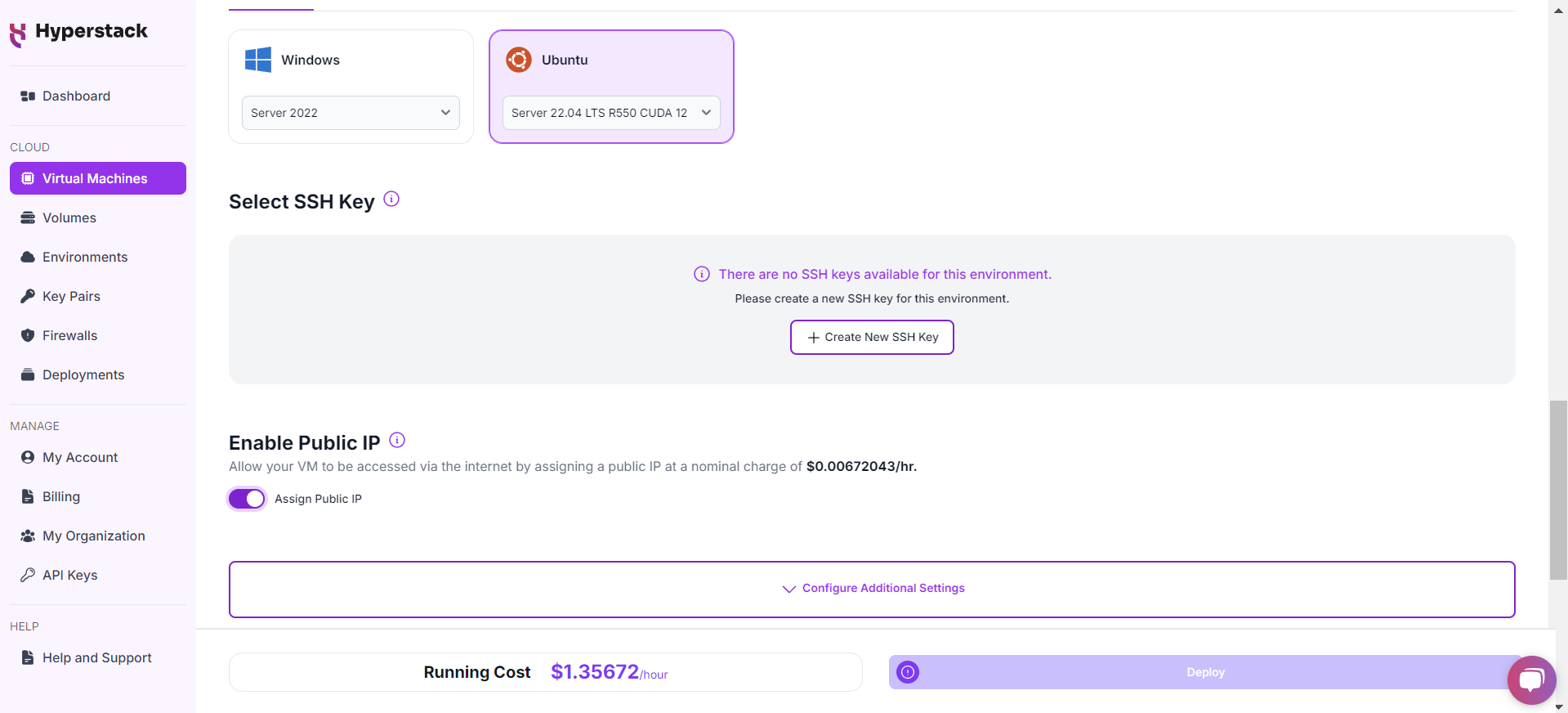
Select a keypair
- Select one of the keypairs in your account. Don't have a keypair yet? See our Getting Started tutorial for creating one.
Network Configuration
- Ensure you assign a Public IP to your Virtual machine [See the attached screenshot].
- This allows you to access your VM from the internet, which is crucial for remote management and API access.
Enable SSH Access
- Make sure to enable an SSH connection.
- You'll need this to securely connect and manage your VM.
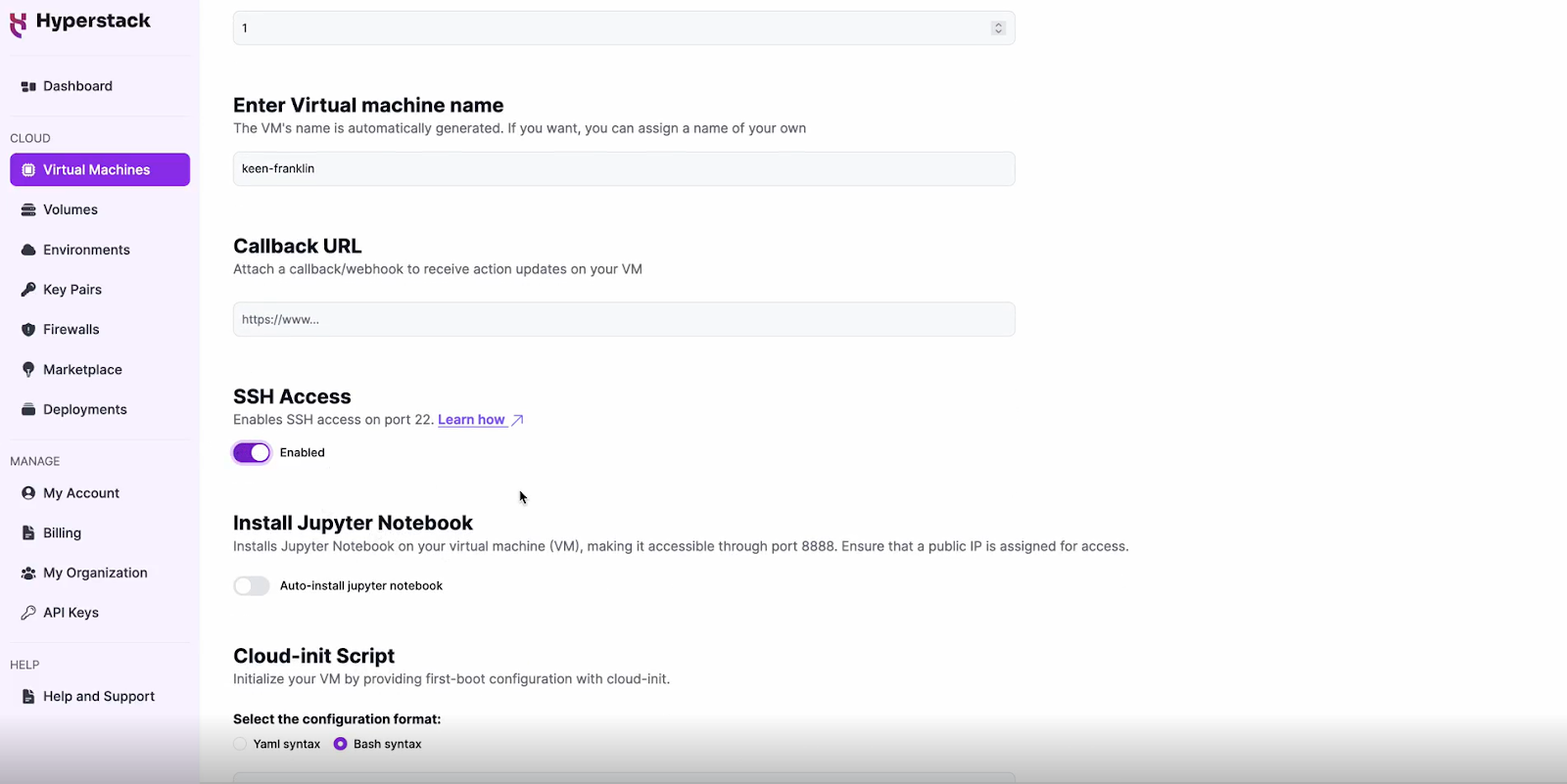
- Double-check all your settings.
- Click the "Deploy" button to launch your virtual machine.
Step 3: Accessing Your VM
Once the initialisation is complete, you can access your VM:
Locate SSH Details
- In the Hyperstack dashboard, find your VM's details.
- Look for the public IP address, which you will need to connect to your VM with SSH.
Connect via SSH
- Open a terminal on your local machine.
- Use the command ssh -i [path_to_ssh_key] [os_username]@[vm_ip_address] (e.g: ssh -i /users/username/downloads/keypair_hyperstack ubuntu@0.0.0.0.0)
- Replace username and ip_address with the details provided by Hyperstack.
Step 4: Setting up gpt-oss 120B with Open WebUI
- To set up gpt-oss 120B, SSH into your machine. If you are having trouble connecting with SSH, watch our recent platform tour video (at 4:08) for a demo. Once connected, use the script below to set up gpt-oss 120B with OpenWebUI.
- Different hardware configurations require edits to the execution script in order to function. Execute the command below that matches your hardware configuration to launch open-webui on port 3000.
8 xNVIDIA H100 PCIe, 8 xNVIDIA H100 PCIe NVLink or 8 xNVIDIA H100 SXM
# 1) Create a docker network
docker network create gpt-oss-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network gpt-oss-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e HF_HOME=/hug vllm/vllm-openai:gptoss --model openai/gpt-oss-120b --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size 8 --gpu-memory-utilization=0.95
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network gpt-oss-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:main
# 1) Create a docker network
docker network create gpt-oss-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network gpt-oss-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e HF_HOME=/hug vllm/vllm-openai:gptoss --model openai/gpt-oss-120b --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size 4 --gpu-memory-utilization=0.90
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network gpt-oss-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:main
# 1) Create a docker network
docker network create gpt-oss-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network gpt-oss-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e HF_HOME=/hug vllm/vllm-openai:gptoss --model openai/gpt-oss-120b --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size 2 --gpu-memory-utilization=0.90
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network gpt-oss-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:main
# 1) Create a docker network
docker network create gpt-oss-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network gpt-oss-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e HF_HOME=/hug vllm/vllm-openai:gptoss --model openai/gpt-oss-120b --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size 1 --gpu-memory-utilization=0.90
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network gpt-oss-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:main8 xNVIDIA L40
# 1) Create a docker network
docker network create gpt-oss-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network gpt-oss-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1 -e HF_HOME=/hug vllm/vllm-openai:gptoss --model openai/gpt-oss-120b --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size 8 --gpu-memory-utilization=0.90
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network gpt-oss-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:main
4 xNVIDIA L40
# 1) Create a docker network
docker network create gpt-oss-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network gpt-oss-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1 -e HF_HOME=/hug vllm/vllm-openai:gptoss --model openai/gpt-oss-120b --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size 4 --gpu-memory-utilization=0.90
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network gpt-oss-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:main
2 xNVIDIA L40
# 1) Create a docker network
docker network create gpt-oss-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network gpt-oss-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1 -e HF_HOME=/hug vllm/vllm-openai:gptoss --model openai/gpt-oss-120b --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size 2 --gpu-memory-utilization=0.90
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network gpt-oss-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:main
The above script will download and host gpt-oss 120B. See the model card here: https://huggingface.co/openai/gpt-oss 120B for more information.
Please Note: Because the model is large, downloading and hosting can take a few minutes. You should refresh the OpenWebUI page periodically until it shows the model as loaded.
Interacting with gpt-oss 120B
-
Open your VM's firewall settings.
-
Allow port 3000 for your IP address (or leave it open to all IPs, though this is less secure and not recommended). For instructions, see here.
-
Visit http://[public-ip]:3000 in your browser. For example: http://198.145.126.7:3000
-
Set up an admin account for OpenWebUI and save your username and password for future logins. See the attached screenshot.

And voila, you can start talking to your self-hosted gpt-oss 120B! See an example below.

Running gpt-oss-120b on AI Studio
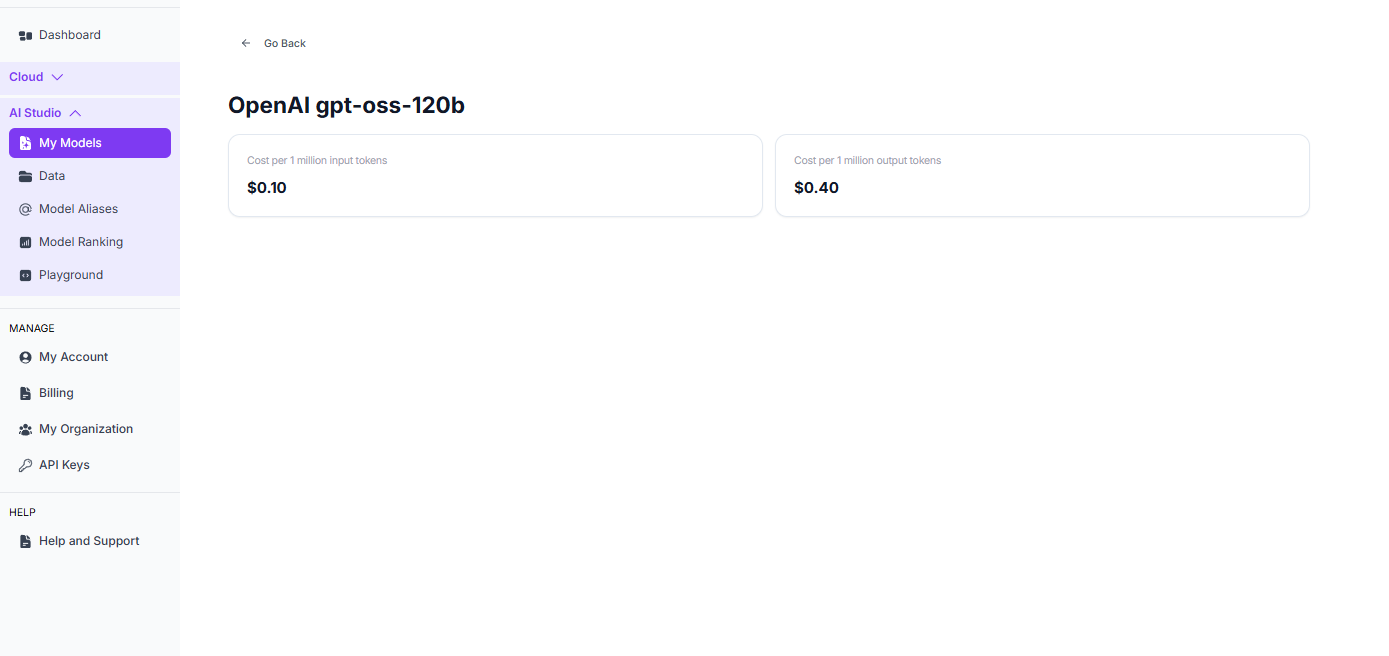
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
- In the Hyperstack dashboard, locate your Virtual machine.
- Look for a "Hibernate" option.
- Click to hibernate the VM, which will stop billing for compute resources while preserving your setup.
Why Deploy gpt-oss 120B on Hyperstack?
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying gpt-oss 120B:
- Availability: Hyperstack provides access to the latest and most powerful GPUs such as the NVIDIA H100 on-demand, specifically designed to handle large language models.
- Ease of Deployment: With pre-configured environments and one-click deployments, setting up complex AI models becomes significantly simpler on our platform.
- Scalability: You can easily scale your resources up or down based on your computational needs.
- Cost-Effectiveness: You pay only for the resources you use with our cost-effective cloud GPU pricing.
- Integration Capabilities: Hyperstack provides easy integration with popular AI frameworks and tools.
FAQs
What is gpt-oss 120B?
gpt-oss 120B is an open-source large language model with approximately 116 billion parameters, delivering benchmark results comparable to OpenAI’s o3-mini and o4-mini.
What are the key features of gpt-oss 120B?
gpt-oss 120B uses a 116B parameter Mixture of Experts design, runs on as few as 2 GPUs without quantisation and supports a 131K context window.
What architecture does gpt-oss 120B use?
The model is built on a Mixture of Experts (MoE) architecture with 5.1B active parameters per token for efficient, high-performance inference.
What is the context length of gpt-oss 120B?
gpt-oss 120B supports a 131K token context window, allowing it to handle very large inputs or extended conversations in one go.
Which GPUs are recommended for running gpt-oss 120B?
For gpt-oss 120B GPU requirements, go to the hardware options and choose either from below:
Can gpt-oss 120B run without quantisation?
Yes, it is optimised for small server deployment and can run on as little as 2 GPUs without the need for quantisation.
How does gpt-oss 120B perform compared to commercial models?
gpt-oss 120B performs on par with OpenAI’s o3-mini and o4-mini across multiple benchmarks while being open-source and more deployable.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

