gpt-oss-20b is OpenAI’s newly released open‑weight language model family. This release marks the first open‑weight model from OpenAI since GPT‑2 in 2019.
The model contains approximately 20 billion parameters and uses a mixture‑of‑experts (MoE) architecture. This design allows it to activate only a portion of its parameters for each token, delivering strong performance while keeping compute requirements manageably.
The best part about the gpt-oss-20b is that it can be deployed on hardware with 16 GB of GPU memory. You can easily run the gpt-oss-20b on the NVIDIA H100 GPU.
Here are the key features of gpt-oss-20b mode:
Efficient Mixture‑of‑Experts Architecture
gpt-oss-20b uses a 21B‑parameter Transformer with a mixture‑of‑experts (MoE) design, activating only 3.6B parameters per token. This allows the model to deliver high reasoning performance while staying lightweight enough for consumer GPUs with ~16 GB VRAM.
Large 128k Context Window
It supports up to 128,000 tokens of context, making it suitable for long‑document understanding, multi‑step reasoning and agentic workflows without frequent truncation or context loss.
Strong Reasoning and Tool Use
gpt-oss-20b matches or exceeds OpenAI o3‑mini on benchmarks like AIME (competition mathematics), MMLU and HealthBench. It also shows strong chain‑of‑thought reasoning, few‑shot function calling and tool usage such as Python execution or web search.
Optimised for Local and Edge Deployment
Designed for on‑device inference, GPT‑OSS‑20B can run on edge devices, local servers or consumer GPUs for cost‑effective private deployments and rapid iteration without heavy cloud infrastructure.
Open‑Weight, Fully Customisable
The model is released under the Apache 2.0 license, so anyone can fine‑tune, modify and deploy gpt-oss-20b freely. It also exposes full chain‑of‑thought outputs and supports structured outputs for integration into agentic and production workflows.
If you’re planning to try the latest gpt-oss-20b model, you’re in the right place. Check out our guide below to get started.
Now, let's walk through the step-by-step process of deploying gpt-oss-20b on Hyperstack.
Initiate Deployment
Select Hardware Configuration
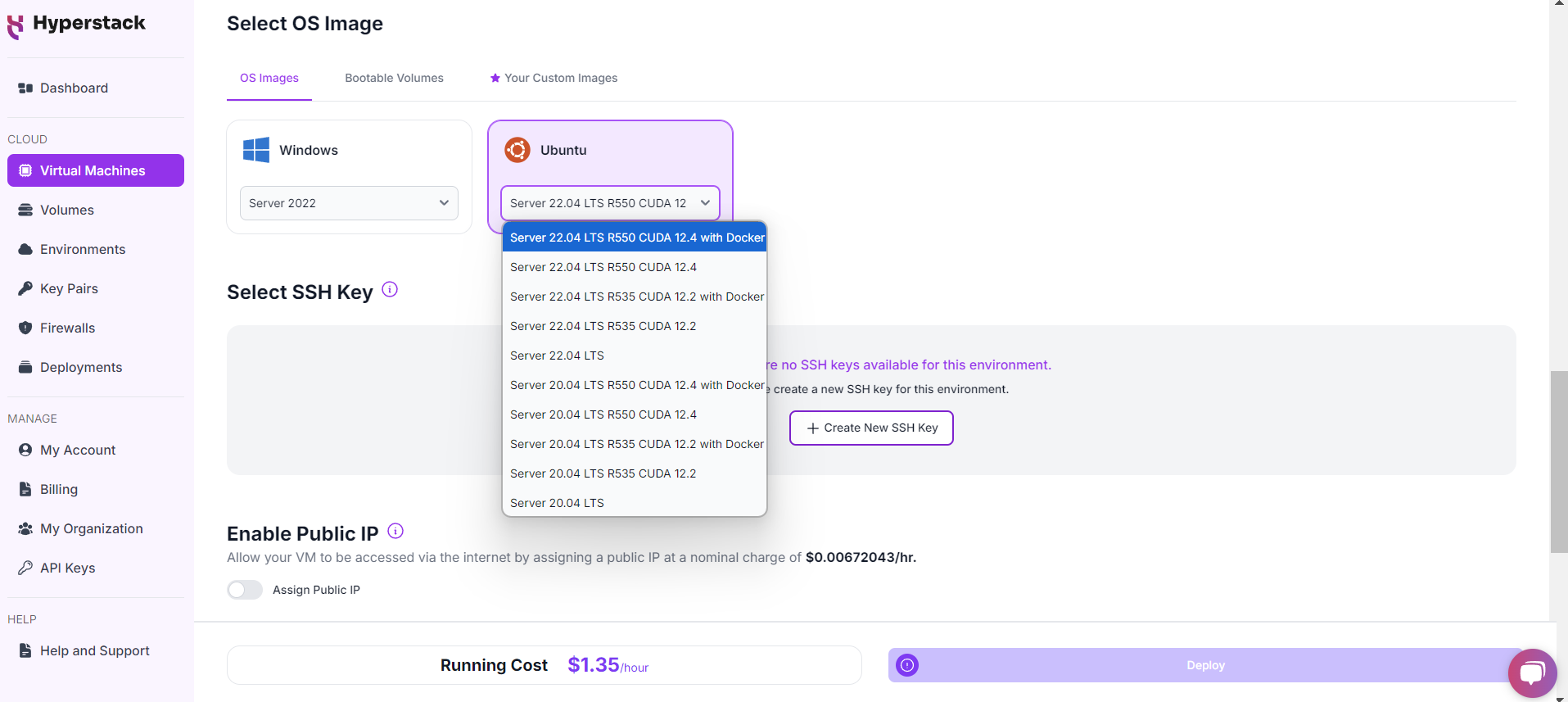
Choose the Operating System
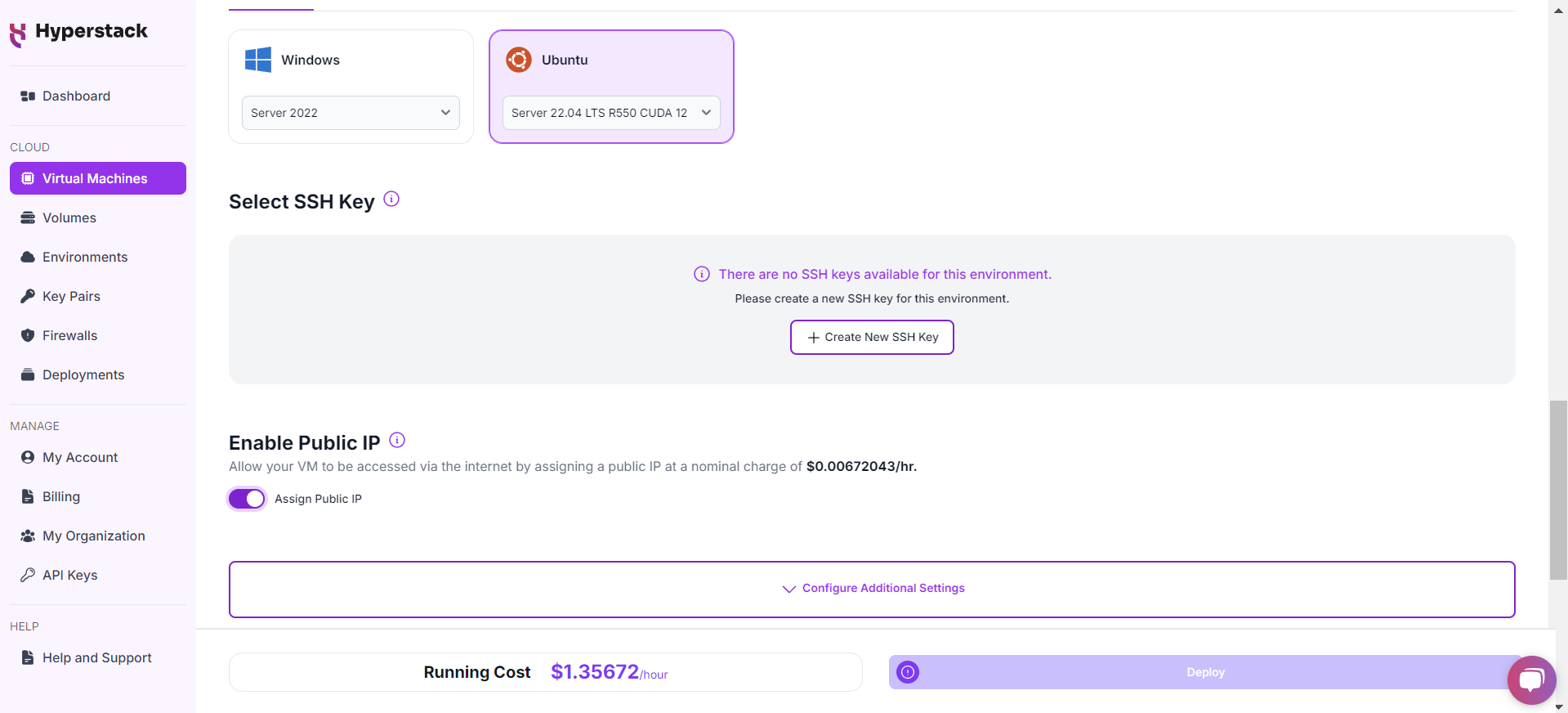
Select a keypair
Network Configuration
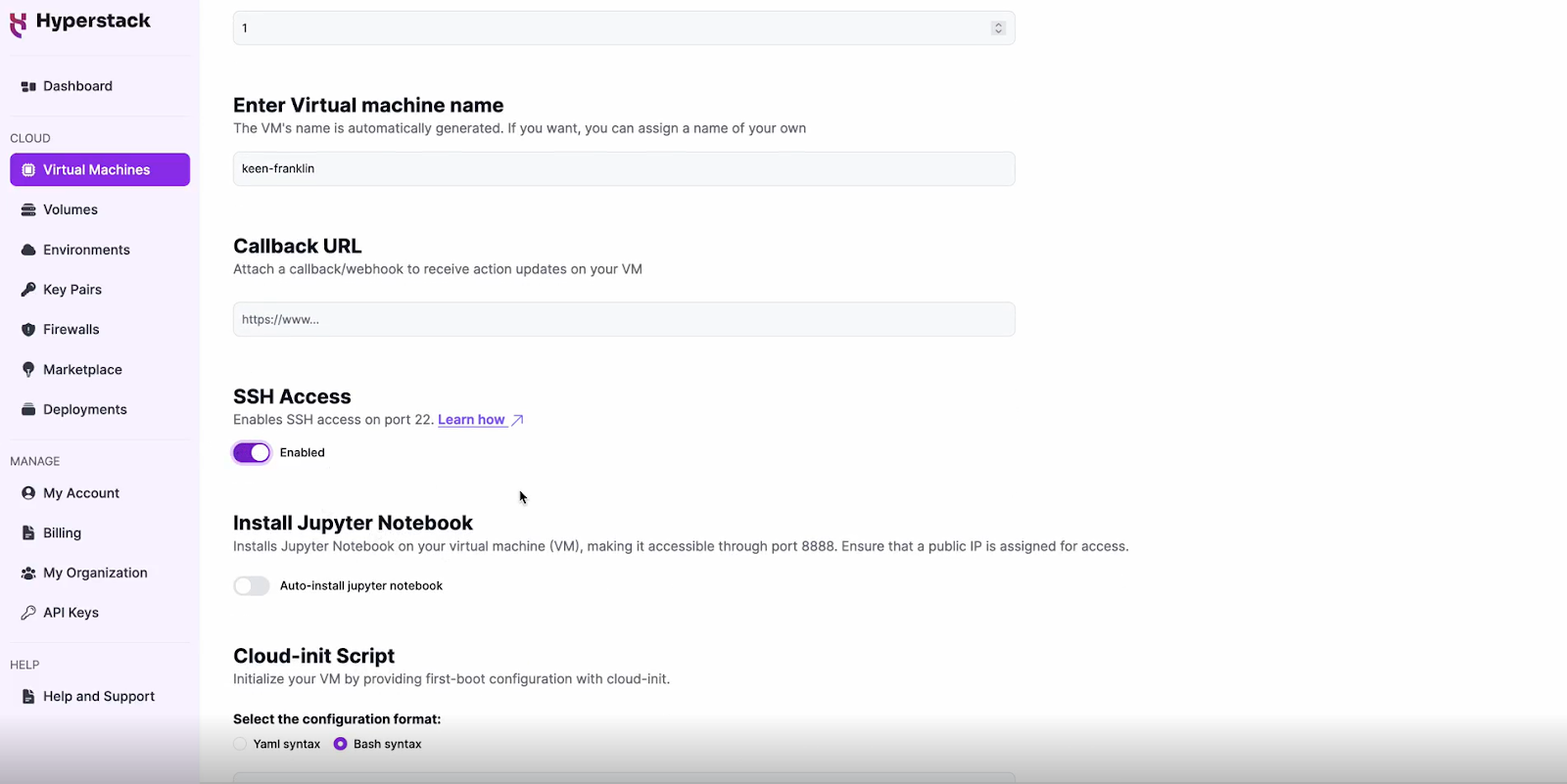
Enable SSH Access
Once the initialisation is complete, you can access your VM:
Locate SSH Details
Connect via SSH
# Create a docker network docker network create ollama-net # Start ollama runtime sudo docker run -d --gpus=all --network ollama-net -p 11434:11434 -v /home/ubuntu/ollama:/root/.ollama --name ollama --restart always ollama/ollama:latest # Pull the model sudo docker exec -it ollama ollama pull gpt-oss:20b # Start open-webui with this runtime sudo docker run -d --network ollama-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OLLAMA_BASE_URL=http://ollama:11434 ghcr.io/open-webui/open-webui:main
The above script will download and host gpt-oss-20b. See the model card here: https://huggingface.co/openai/gpt-oss-20b for more information.
Open your VM's firewall settings.
Allow port 3000 for your IP address (or leave it open to all IPs, though this is less secure and not recommended). For instructions, see here.
Visit http://[public-ip]:3000 in your browser. For example: http://198.145.126.7:3000
Set up an admin account for OpenWebUI and save your username and password for future logins. See the attached screenshot.
And voila, you can start talking to your self-hosted gpt-oss-20b! See an example below.
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying gpt-oss-20b:
gpt-oss-20b is OpenAI’s 21B‑parameter open‑weight language model offering strong reasoning, local deployment and full customisation under Apache 2.0.
It supports up to 128,000 tokens, ideal for long‑document analysis, multi‑step reasoning and agentic workflows requiring extended memory.
gpt-oss-20b is smaller, lighter, and edge‑friendly, while GPT‑OSS‑120B offers higher performance for enterprise‑level reasoning and large‑scale deployments.
Yes, it supports configurable chain‑of‑thought reasoning with low, medium, and high effort modes for faster or deeper analysis.
Absolutely, GPT‑OSS‑20B excels at few‑shot function calling, tool use like Python execution, and structured output for automation workflows.
It’s released under Apache 2.0, allowing commercial use, modification, redistribution, and fine‑tuning without vendor lock‑in.
It’s perfect for local AI applications, long‑document reasoning, coding tasks, private inference, and cost‑effective on‑device deployments.
{kind=link}
{kind=link}
{kind=link}
{kind=link}