What is Qwen3-4B?
Qwen3-4B is part of the latest generation of Qwen large language models, designed to push the boundaries of reasoning, dialogue, and multilingual support. It is a causal language model with 4 billion parameters, making it compact yet powerful for a wide range of tasks. Built on both pre-training and post-training, Qwen3-4B delivers strong performance in logical reasoning, mathematics, coding, and natural conversation, while also excelling in instruction following, role-playing and multi-turn dialogues.
Features of Qwen3-4B
Here are the key features of Qwen3-4B:
- Dual Reasoning Modes: Switches between deep thinking mode for maths, coding, and reasoning, and fast mode for casual conversations, ensuring both speed and accuracy.
- Stronger Problem-Solving: Delivers more accurate results in logic, mathematics, and code generation compared to earlier Qwen models, making it reliable for technical tasks.
- Human-Like Conversations: Excels at instruction following, creative writing, role-play, and multi-turn dialogue, creating smooth and engaging interactions.
- Advanced Agent Capabilities: Integrates with external tools across different modes, allowing it to handle complex workflows and act as a smart assistant.
- Multilingual Support: Covers 100+ languages and dialects with robust translation and instruction-following, making it useful for global communication.
How to Deploy Qwen3-4B
Now, let's walk through the step-by-step process of deploying Qwen3-4B on Hyperstack.
Step 1: Accessing Hyperstack
- Go to the Hyperstack website and log in to your account.
- If you're new to Hyperstack, you'll need to create an account and set up your billing information. Check our documentation to get started with Hyperstack.
- Once logged in, you'll be greeted by the Hyperstack dashboard, which provides an overview of your resources and deployments.
Step 2: Deploying a New Virtual Machine
Initiate Deployment
- Look for the "Deploy New Virtual Machine" button on the dashboard.
- Click it to start the deployment process.
Select Hardware Configuration
- In the hardware options, choose the "1xH100 PCIe" flavour.
Choose the Operating System
- Select the "Ubuntu Server 24.04 LTS R570 CUDA 12.8 with Docker".
Select a keypair
- Select one of the key pairs in your account. Don't have a keypair yet? See our Getting Started tutorial for creating one.
Network Configuration
- Ensure you assign a Public IP to your Virtual machine.
- This allows you to access your VM from the internet, which is crucial for remote management and API access.
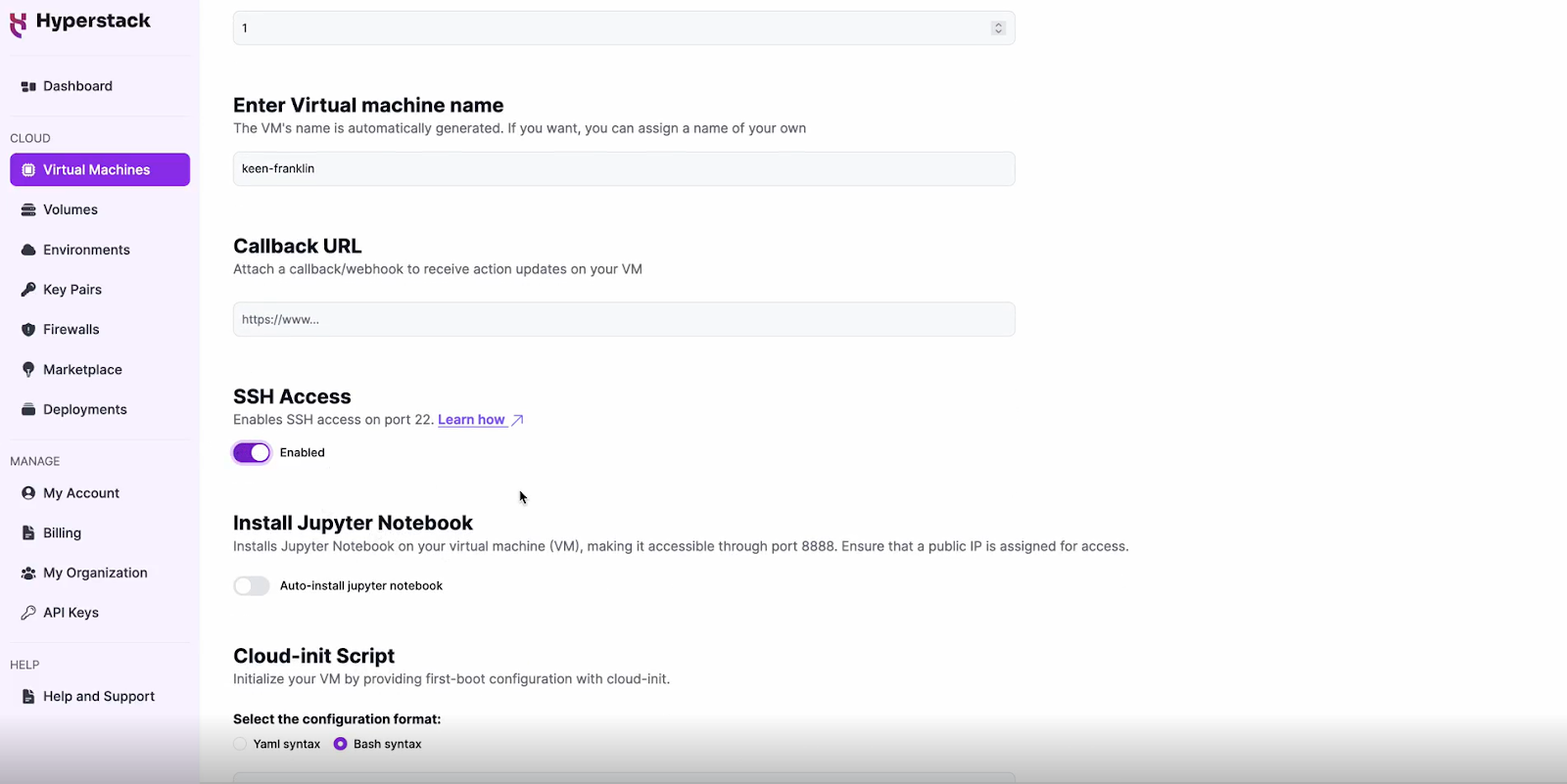
Enable SSH Access
- Make sure to enable an SSH connection.
- You'll need this to securely connect and manage your VM.
Review and Deploy
- Double-check all your settings.
- Click the "Deploy" button to launch your virtual machine.
Step 3: Accessing Your VM
Once the initialisation is complete, you can access your VM:
Locate SSH Details
- In the Hyperstack dashboard, find your VM's details.
- Look for the public IP address, which you will need to connect to your VM with SSH.
Connect via SSH
- Open a terminal on your local machine.
- Use the command ssh -i [path_to_ssh_key] [os_username]@[vm_ip_address] (e.g: ssh -i /users/username/downloads/keypair_hyperstack ubuntu@0.0.0.0.0)
- Replace username and ip_address with the details provided by Hyperstack.
Interacting with Qwen3-4B
To access and experiment with Meta's latest model, SSH into your machine after completing the setup. If you are having trouble connecting with SSH, watch our recent platform tour video (at 4:08) for a demo. Once connected, use this API call on your machine to start using the Qwen3-4B:
# 1) Create a docker network
docker network create ollama-net
# 2) Start ollama
sudo docker run -d --gpus=all --network ollama-net -p 11434:11434 -v /home/ubuntu/ollama:/root/.ollama --name ollama --restart always ollama/ollama:latest
# 3) Pull the model
sudo docker exec -it ollama ollama pull qwen3:4b
# 4) Start Open WebUI (points to ollama's API)
sudo docker run -d --network ollama-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OLLAMA_BASE_URL=http://ollama:11434 ghcr.io/open-webui/open-webui:main
If the API is not working after ~10 minutes, please refer to our 'Troubleshooting Qwen3-4B" section below.
Troubleshooting Qwen3-4B
If you are having any issues, you might need to restart your machine before calling the API:
-
Run sudo reboot inside your VM
-
Wait 5-10 minutes for the VM to reboot
-
SSH into your VM
-
Wait ~3 minutes for the LLM API to boot up
-
Run the above API call again
If you are still having issues, try:
-
Run docker ps and find the container_id of your API container
-
Run docker logs [container_id] to see the logs of your container
-
Use the logs to debug any issues
Step 5: Hibernating Your VM
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
- In the Hyperstack dashboard, locate your Virtual machine.
- Look for a "Hibernate" option.
- Click to hibernate the VM, which will stop billing for compute resources while preserving your setup.
To continue your work without repeating the setup process:
- Return to the Hyperstack dashboard and find your hibernated VM.
- Select the "Resume" or "Start" option.
- Wait a few moments for the VM to become active.
- Reconnect via SSH using the same credentials as before.
Why Deploy on Hyperstack?
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying Qwen3-4B:
- Availability: Hyperstack provides access to the latest and most powerful GPUs such as the NVIDIA A100 and the NVIDIA H100 SXM on-demand, specifically designed to handle large language models.
- Ease of Deployment: With pre-configured environments and one-click deployments, setting up complex AI models becomes significantly simpler on our platform.
- Scalability: You can easily scale your resources up or down based on your computational needs.
- Cost-Effectiveness: You pay only for the resources you use with our cost-effective cloud GPU pricing.
- Integration Capabilities: Hyperstack provides easy integration with popular AI frameworks and tools.
New to Hyperstack? Sign up on Hyperstack Today to Get Started.
FAQs
What is Qwen3-4B?
Qwen3-4B is a 4-billion parameter causal language model from the Qwen3 series, designed for reasoning, coding, creative writing, multilingual support, and tool integration.
How is Qwen3-4B different from earlier Qwen models?
It introduces dual reasoning modes, offering both deep logical thinking and fast conversational responses, while also showing stronger performance in maths, coding, and multi-turn dialogue compared to Qwen2.5 and QwQ.
What kind of tasks can I use Qwen3-4B for?
You can use it for coding assistance, problem-solving in maths and logic, creative writing, role-play, multilingual translation and integrating with external tools for task execution.
Does Qwen3-4B support multilingual use?
Yes, it supports over 100 languages and dialects, making it effective for cross-language communication and translation.
Which GPU should I use to run Qwen3-4B?
You can use the NVIDIA H100 PCIe GPU to run the Qwen3-4B model on Hyperstack.
{kind=link}
{kind=link}