

TABLE OF CONTENTS
NVIDIA H100 SXM On-Demand
Welcome back to our SR-IOV series! In our previous post, we promised to provide the technical aspects of this technology. Today, we will offer a comprehensive look at Remote Direct Memory Access (RDMA) and its implementations along with some benchmark results. Let’s get started!
Remote Direct Memory Access (RDMA)
To recall, RDMA is a technology that allows networked computers to transfer data directly between their main memories bypassing the processor, cache and operating system. This helps in improved throughput and performance. This technology is quite similar to Direct Memory Access (DMA) but applied across networked systems. RDMA is particularly beneficial for networking and storage applications because it offers faster data transfer rates and lower latency, crucial factors to lead in the AI domain.
Types of RDMA: InfiniBand and RoCE
RDMA can be implemented using two primary technologies:
- InfiniBand (IB): InfiniBand is a network specifically designed for RDMA. It's known for its extremely high throughput and very low latency. This makes it ideal for environments that require fast and efficient data transfer such as high-performance computing (HPC) clusters and for training LLMs.
- RDMA over Converged Ethernet (RoCE): RoCE is a network protocol that enables RDMA over Ethernet networks. It allows data to be transferred directly from one machine to another. This significantly reducing the CPU's workload. RoCE is divided into two versions: RoCEv1 and RoCEv2. Each version is equipped with distinct features and capabilities.
Key Features of RoCE
The key features of RDMA over Converged Ethernet (RoCE) are as mentioned:
- Kernel Bypass: In this feature, the RoCE uses specialised Network Interface Cards (NICs) with RDMA capabilities to access server memory directly, bypassing the CPU and operating system.
- Workload Offloading: By offloading data movement tasks to RDMA-enabled NICs, RoCE frees up CPU resources for core computational tasks.
- Data Streamlining: RoCE employs protocols like the User Datagram Protocol (UDP) which prioritise speed over error correction. This is particularly beneficial for high-throughput applications like AI where real-time data exchange is crucial.
Comparing InfiniBand, RoCE and TCP/IP
|
Feature |
InfiniBand |
RoCE |
TCP/IP |
|
Scalability |
☑️ |
||
|
Performance |
☑️ |
☑️ |
|
|
Stability |
☑️ |
||
|
Cost |
☑️ |
☑️ |
|
|
Management |
☑️ |
☑️ |
The comparison table above uses checkmarks or ticks to indicate which technology is superior for each feature. Based on this, let's break down the comparison:
Scalability: InfiniBand > RoCE
InfiniBand is designed for high scalability, particularly in large data center environments. It can support thousands of nodes with low latency and high bandwidth. RoCE, while scalable, may face some limitations in very large deployments compared to InfiniBand.
Performance: InfiniBand and RoCE > TCP/IP
Both InfiniBand and RoCE use Remote Direct Memory Access (RDMA) technology, which allows for direct data transfer between the memory of different computers without involving the operating system. This results in lower latency and higher throughput compared to TCP/IP, which has more overhead due to protocol processing.
Stability: InfiniBand > TCP/IP and RoCE
InfiniBand is known for its high stability and reliability, particularly in demanding environments like high-performance computing clusters. It has built-in error correction and flow control mechanisms. TCP/IP is also stable but may not match InfiniBand in high-stress scenarios. RoCE, being a newer technology, may face some stability challenges in certain implementations.
Cost: RoCE and TCP/IP > InfiniBand
InfiniBand typically requires specialised hardware, which can be more expensive than standard Ethernet equipment used for RoCE and TCP/IP. RoCE leverages existing Ethernet infrastructure, making it more cost-effective. TCP/IP runs on standard networking equipment, usually making it the most affordable option.
Management: TCP/IP > RoCE > InfiniBand
TCP/IP is the most widely used networking protocol, with extensive tools and expertise available for management. RoCE, being based on Ethernet, benefits from some familiar management tools but may require additional expertise for RDMA configuration. InfiniBand often requires specialised knowledge and tools for management, making it potentially more complex to administer.
Comparing RoCE Versions
Now we will compare the RoCE versions:
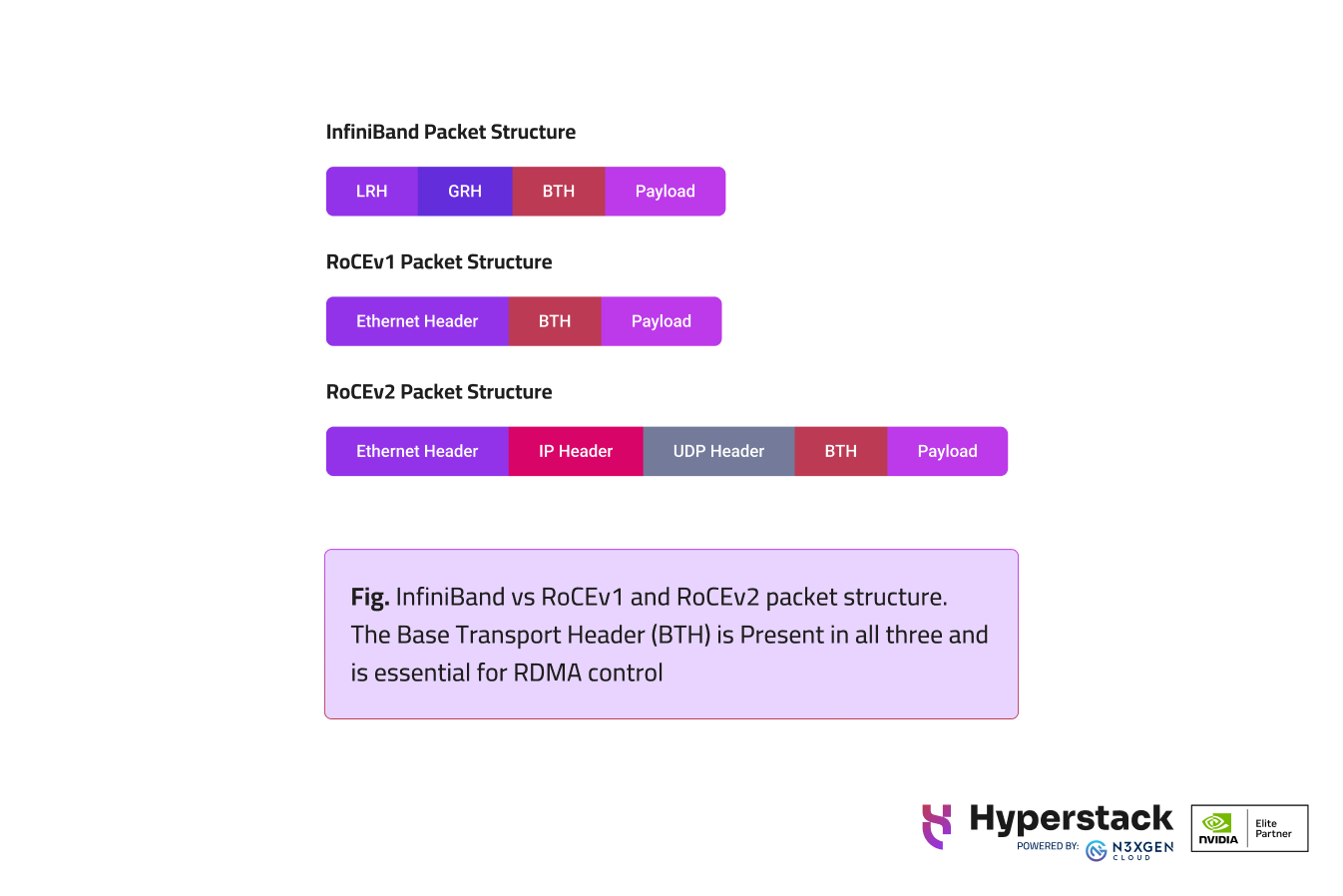
RoCEv1
- Encapsulation: RDMA over Ethernet header
- Ether Type: Uses a dedicated Ether type (0x8915)
- VLAN Tag: Can be used with or without VLAN tagging
- MTU: Adheres to regular Ethernet Maximum Transmission Unit (MTU)
RoCEv2
- Encapsulation: UDP and IP headers
- Ether Type: Uses a well-known UDP destination port (4791)
- IP Layer: Operates at the IP layer (Layer 3), enabling traffic to traverse IP routers
- UDP Header: Provides stateless encapsulation for RDMA transport protocol packets over IP
- Flow-identifier: The UDP source port field carries an opaque flow-identifier for network optimisations like Equal-Cost Multi-Path (ECMP) routing
- Interoperability: RoCEv2 packets are designed to seamlessly work with RDMA applications without changes to the application layer
Benchmark Results
To achieve optimal network performance, understanding the impact of various configurations on throughput and latency is imperative. We conducted a series of tests using iPerf, a widely used network testing tool to measure the bandwidth and performance of different network setups. Our focus was on comparing Baremetal with OpenFabrics Enterprise Distribution (OFED) stack, Virtual Machines (VM) with different Maximum Transmission Unit (MTU) settings and VMs configured with SR-IOV (Single Root I/O Virtualisation), VF-LAG (Virtual Function Link Aggregation Group) and NUMA (Non-Uniform Memory Access). The settings compared are as mentioned:
1. Baremetal with OpenFabrics Enterprise Distribution (OFED) stack
Provides direct access to hardware, leading to minimal overhead and high performance.
2. Virtual Machines (VM) with MTU 1500 (default Ethernet frame size)
The standard MTU size, typically 1500 bytes, includes the payload and headers.
3. Virtual Machines (VM) with MTU 9000 (Jumbo frames)
Jumbo frames increase the MTU size to 9000 bytes, allowing larger packets to be sent, which can reduce overhead and improve throughput.
4. Virtual Machines (VM) with SR-IOV VF-LAG and NUMA
- SR-IOV allows a single physical network interface to be shared among multiple VMs, reducing latency and improving throughput.
- VF-LAG aggregates multiple virtual functions into a single logical interface for redundancy and load balancing.
- NUMA architecture optimises memory access by allowing processors to access their local memory faster than non-local memory.
Understanding Testing Methodology
We conducted network performance measurements using iPerf for evaluating and improving the speed and reliability of wired and wireless networks. Our tests spanned multiple configurations, each assessed with a range of thread counts: 1, 2, 4, 8, 10, 12, 16, 20, and 24. This comprehensive approach allowed us to gauge how different setups respond to varying levels of concurrent network activity.
Take a look into our measurements below. The numbers are mentioned in Gbps:
|
1T |
2T |
4T |
8T |
10T |
12 T |
16T |
20T |
24T |
|
|
1 |
18,9 |
39,2 |
93,9 |
176 |
190 |
225 |
313 |
381 |
395 |
|
2 |
10,5 |
8,89 |
8,68 |
8,52 |
8,45 |
8,41 |
8,4 |
8,23 |
8,23 |
|
3 |
16,2 |
17 |
14 |
14,1 |
13,2 |
13,8 |
14 |
13,3 |
13,4 |
|
4 |
37,1 |
67,8 |
122 |
199 |
197 |
262 |
290 |
331 |
349 |
Benchmark Observations
In the performance benchmark results, we observed the following:
- Baremetal with OFED Stack: This exhibits the highest overall throughput, particularly as thread count increases. It reaches a peak of 395 Gbps with 24 threads. However, SR-IOV follows closely behind at 349 Gbps and can achieve up to 400 Gbps in certain scenarios. Notably, SR-IOV outperforms bare metal in the 1-12 thread range.
- VM with MTU 1500: Throughput consistently hovers around 8-10 Gbps, suggesting potential constraints in managing higher network loads.
- VM with MTU 9000: Reaches its maximum of about 17 Gbps with 2 threads, then stabilises between 13-14 Gbps as thread count increases.
- VM with SR-IOV VF-LAG and NUMA: This shows significant performance gains over standard VMs. It achieves a peak of 400 Gbps with 24 threads, which is slightly lower than the bare metal configuration's peak of 400 Gbps. Interestingly, it surpasses bare metal performance in the 1-12 thread range.
What’s Next?
Don't miss our next post in the “SR-IOV Series” for a real-world example of SR-IOV in action! See how Meta leverages this technology for optimal performance. Get started now to explore our platform for more.
FAQs
What is RDMA and why is it important?
RDMA allows direct memory access between networked computers for improving throughput and performance.
How does RoCE improve network performance?
RoCE uses kernel bypass and workload offloading to reduce CPU usage and increase data transfer speeds.
What configuration showed the highest overall throughput in the benchmarks?
Baremetal with OFED Stack showed the highest throughput, peaking at 395 Gbps with 24 threads.
How does SR-IOV performance compare to baremetal in the benchmarks?
SR-IOV closely follows baremetal performance, outperforming it in the 1-12 thread range.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

