
.png)
TABLE OF CONTENTS
NVIDIA H100 SXM On-Demand
Building a product roadmap is one of the most challenging tasks any technology company faces. It is a high-stakes balancing act: should the team invest in new features that could open up new markets, or focus on fixing bugs and improving stability for existing users? Making this decision requires analyzing a large amount of conflicting information, including customer feedback, competitor strategies, and internal technical constraints. A single wrong decision can result in wasted engineering effort, missed opportunities, and dissatisfied users.
In this blog, we will take a closer look at this complex challenge. We will design a sophisticated multi-agent system that replicates the collaborative and sometimes challenging process of a real-world product planning committee.
Let's understand how our Deep Thinking Multi-Agentic System works.

- Data and Tool Layer: This layer consists of various data sources and tools that provide raw information about user feedback, competitor analysis, and technical feasibility. These tools simulate real-world APIs and databases.
- Intelligence Team: This team of specialized agents gathers and synthesizes information from the data layer. Each agent has a specific focus area, such as user feedback or competitor analysis, and uses a fast, cost-effective model to summarize its findings.
- Orchestration Layer: This layer coordinates the interactions between agents. It manages the flow of information, ensuring that each agent receives the necessary context to perform its tasks effectively.
- Three Strategic Agents: These agents represent different perspectives within the product planning committee. The Innovation Advocate pushes for bold new features, the Stability Advocate emphasizes technical debt and user experience, and the Product Manager synthesizes these viewpoints into a coherent roadmap.
- Cognitive Roles: Each agent is assigned a specific cognitive role, such as data gathering, debating, or synthesizing. This specialization allows agents to focus on their strengths and contribute effectively to the overall decision-making process.
Now that we have an overview of the architecture, let's start building our multi-agent system step by step.
Why Hyperstack AI Studio is the Right Choice for Deep Thinking Agentic Systems
End-to-End Model Lifecycle Made Simple
The agents in your system perform best when tuned for their specific roles. Hyperstack AI Studio lets you fine-tune the same base models your agents use, host them automatically for inference, and test results instantly without worrying about deployment or setup.
Flexibility for Multi-Agent Architectures
A deep thinking system needs different models for different jobs, some lightweight and fast, others powerful and analytical. Hyperstack provides a full range of model sizes and families, making it easy to match the right one to each agent’s purpose.
Unified API for Seamless Integration
You can plug Hyperstack models directly into your agent graph using one simple API. This consistency keeps your code clean, reduces setup time, and ensures every agent communicates smoothly within the system.
Scalable and Reliable Infrastructure
As your agent network grows and tasks become more complex, Hyperstack automatically scales to handle the load. You get stable performance and fast responses even in multi-round reasoning or debate scenarios.
Built for Fast Experimentation
Agentic development thrives on iteration. Hyperstack quick fine-tuning, built-in evaluation tools, and cost tracking let you test ideas rapidly, compare results, and continuously refine your workflow for better outcomes.
Setting Up the Agentic Committee
Before we begin building our team of intelligent agents, we need to establish a solid foundation. This initial setup is essential because it makes sure that our system remains organized, maintainable, and scalable. A well-defined base will make the complex agentic logic that we develop later much easier to manage and debug.
In this first part, we will:
- Build a reusable function to handle all communication with the Hyperstack AI API.
- Assign specific models to different cognitive roles in order to balance cost and performance.
- Set up the core libraries and securely configure our API keys.
Building the Hyperstack AI API Wrapper
The first step in any strong software project is to make sure we do not repeat ourselves. Instead of putting raw API call logic in several agent nodes, we will create one clean wrapper function that handles everything.
One of the best things about Hyperstack AI Studio is that it works with an OpenAI compatible API. Because of this compatibility, it becomes very easy to switch models or integrate Hyperstack into an existing project.
By doing this, we create a simple, consistent interface for our agents to talk to the AI models. If the API ever changes, we only have to update it in one place.
Let's start by coding our call_hyperstack function. Its job is to take a model name and a list of messages, handle the API communication, and return just the clean text response from the model.
import os
import json
import requests
from typing import List, Dict
from pprint import pprint # For pretty-printing structured data
from openai import OpenAI
# Configure the OpenAI client to point to the Hyperstack AI API
# This is the only configuration needed to switch from OpenAI to Hyperstack
client = OpenAI(
base_url="https://console.hyperstack.cloud/ai/api/v1",
api_key=os.environ.get("HYPERSTACK_API_KEY")
)
def call_hyperstack(model: str, messages: List[Dict[str, str]]) -> str:
"""A wrapper function to call the Hyperstack AI chat completions API using the official OpenAI library."""
# Use a try-except block to gracefully handle potential API errors
try:
# The client.chat.completions.create call is identical to OpenAI's
chat_completion = client.chat.completions.create(
model=model,
messages=messages,
stream=False # We'll use blocking calls for simplicity
)
# Extract and return the core message content
return chat_completion.choices[0].message.content
except Exception as e:
# If an error occurs, print it and return a clear error message
print(f"An error occurred during the API call: {e}")
return "Error: Could not get a response from the model."
Our call_hyperstack function is now a clean, reusable interface for the Hyperstack API. The try...except block makes our system resilient, ensuring an agent won't crash if the API is down.
Most importantly, by using the standard openai library, we have shown how seamlessly developers can integrate Hyperstack into their workflows, often just by changing the base_url and api_key.
Defining Model Roles: Fast vs. Deep Thinkers
In a sophisticated multi-agent system, using a single, monolithic model for every task is incredibly inefficient. Hyperstack provides a variety of models, each with its own strengths and weaknesses. The key to building a cost-effective and performant system is to match the right level of model to the right task.
You can get your API key from the Hyperstack console here.

We are going to define a clear hierarchy of models for different roles:
- Fast Thinker: For simple, high-volume tasks like summarizing raw data.
- Deep Thinker: For complex tasks that require deep reasoning, like debating strategy or synthesizing conflicting reports.
- Evaluator: A powerful, top-tier model to act as our impartial judge, ensuring the quality of our final output.
# Assign specific models to different cognitive roles based on their capabilities and cost.
MODEL_FAST_THINKER = "mistralai/Mistral-Small-24B-Instruct-2501" # Good for summarization and simple tool use
MODEL_DEEP_THINKER = "meta-llama/Llama-3.3-70B-Instruct" # Excellent for complex reasoning and debate
MODEL_EVALUATOR = "openai/gpt-oss-120b" # A powerful model to act as an unbiased judge
By centralizing our model configuration in one place, we can easily experiment with different models in the future. For example, we could replace Llama-3.3-70B with another large model without changing any part of our agent logic. This flexibility is essential for continuous iteration and improvement of our system over time.
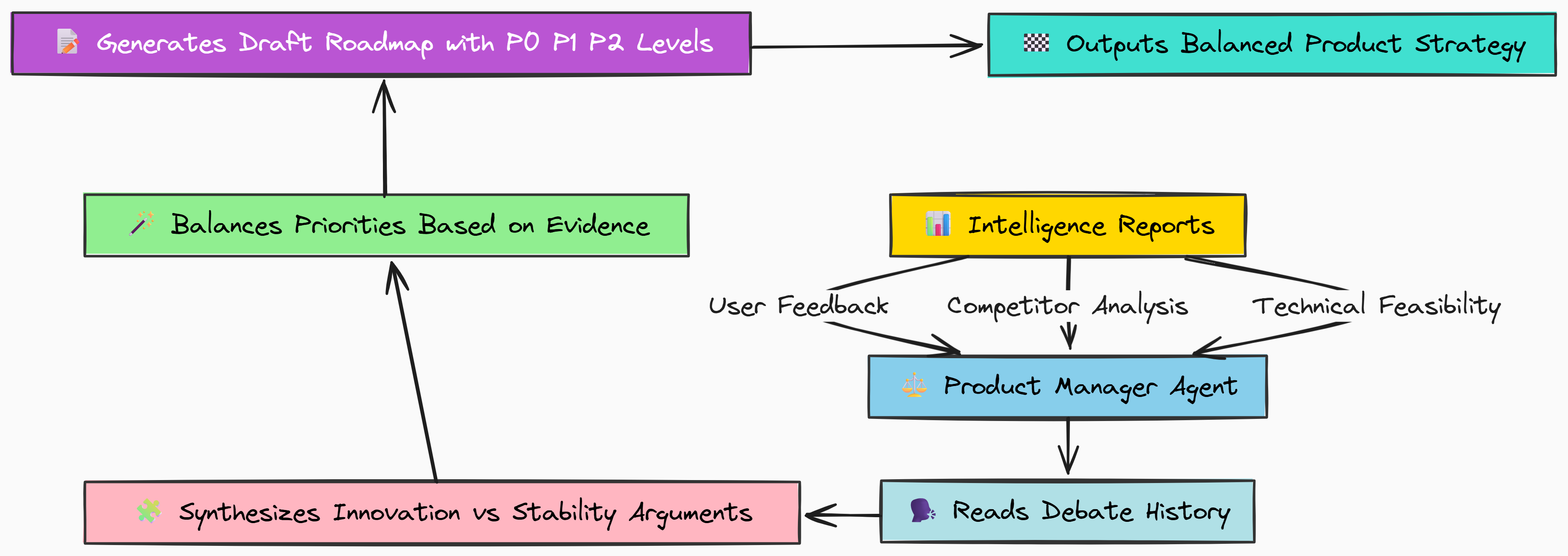
Creating the Intelligence Team: Data-Gathering Agents
The Product Intelligence Team is the data-gathering arm of our system. Its job is to scan the corporate "universe" user feedback, competitor news, and internal technical notes and distill that raw data into actionable intelligence.
Without this team, our strategic agents would be operating in a vacuum, making decisions based on assumptions rather than ground truth. This is the step that grounds our entire process in reality.
In this section, we will:
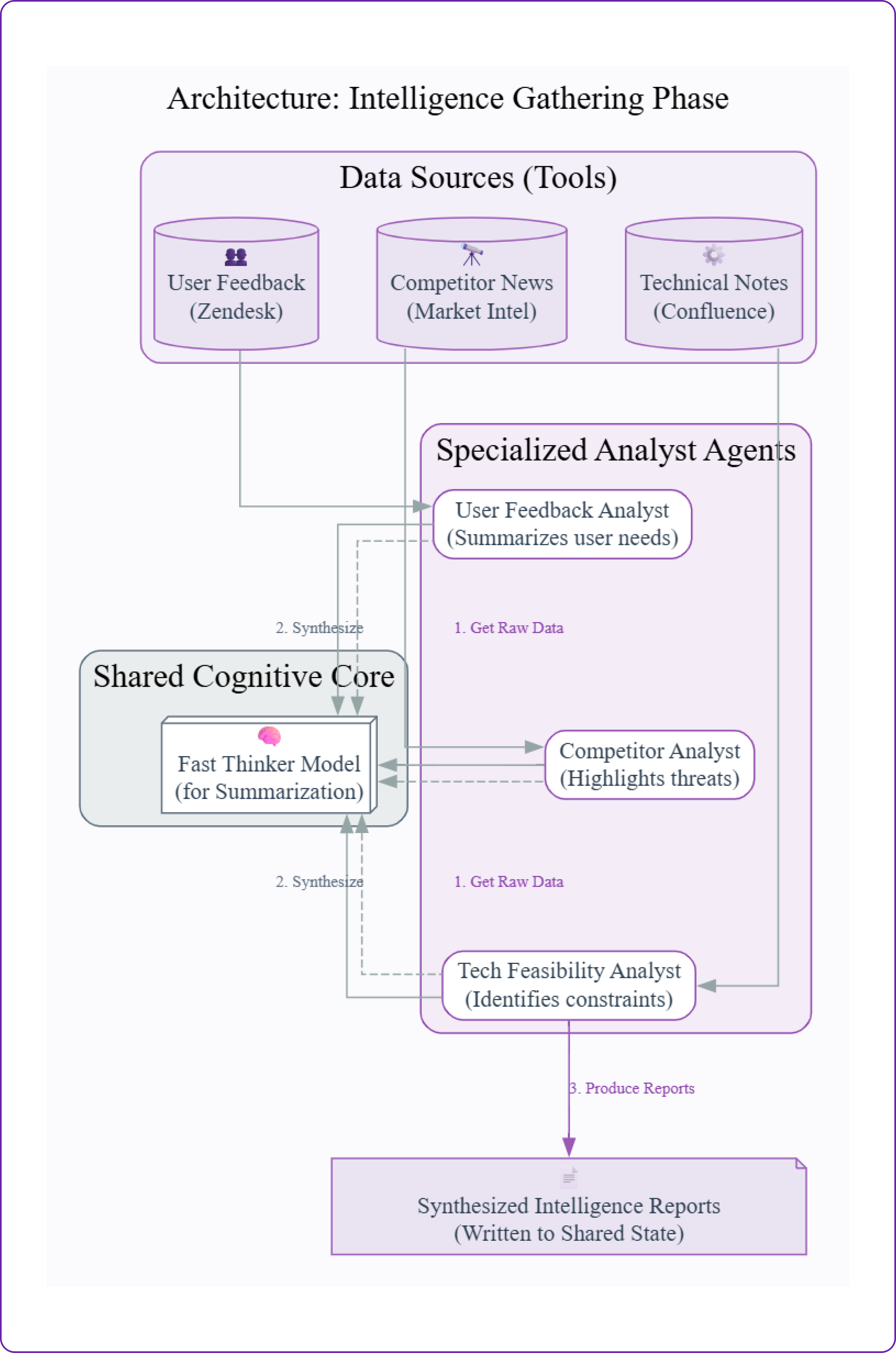
- Build three specialized "analyst" agents, one for each data source.
- Have each agent call its specific mock tool to get raw data.
- Use our
FAST_THINKER_MODELto have each agent synthesize its findings into a concise report. - Run the full intelligence phase and inspect the final reports.
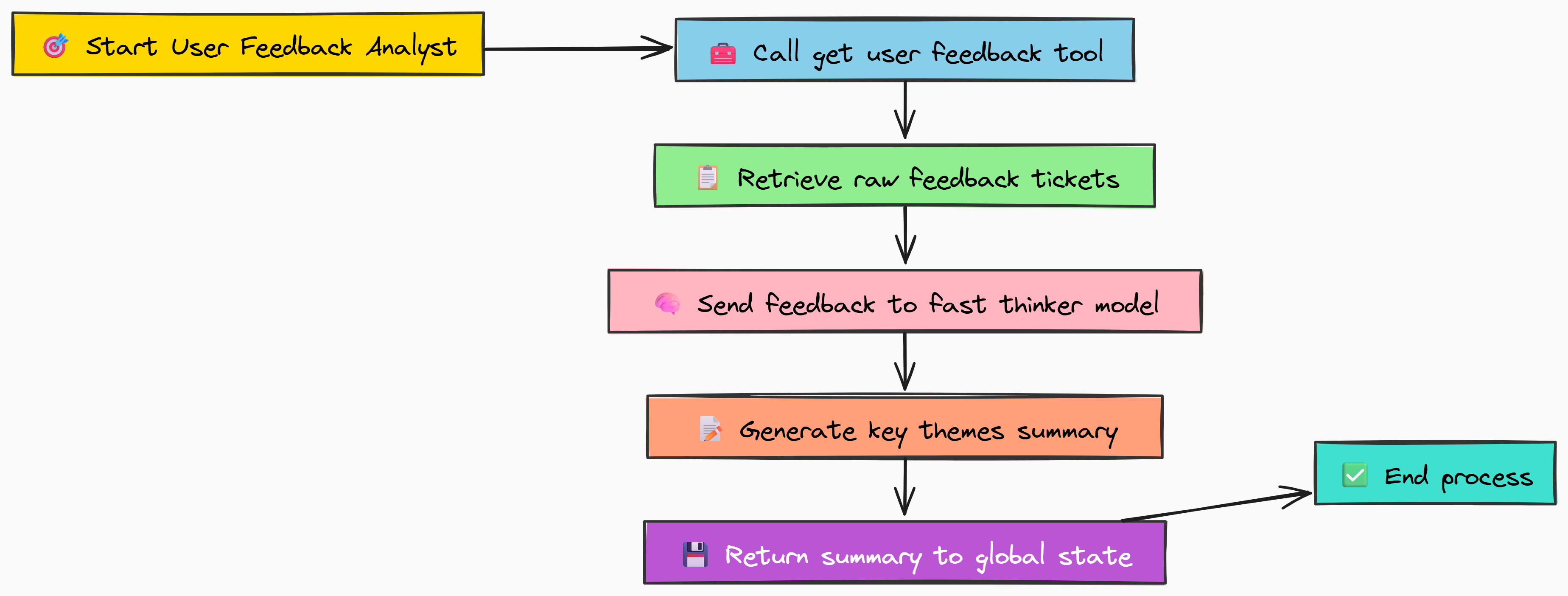
The User Feedback Analyst
Our first agent's job is to understand the voice of the customer. It will call our mock get_user_feedback_tool to get a list of raw support tickets and then summarize them into key themes. This is a perfect task for our FAST_THINKER_MODEL because it’s a straightforward summarization job.
Let's code that get_user_feedback_tool first.
def get_user_feedback_tool() -> List[str]:
"""Simulates calling an API to get recent user feedback tickets."""
print("--- Tool: get_user_feedback_tool called ---")
# In a real system, this would be an API call to a service like Zendesk or Jira.
# We're returning hardcoded data for this demonstration.
feedback = [
"Ticket #4821: Users report the main dashboard is slow to load, especially on lower-end devices.",
"Ticket #5103: Frequent requests for a dark mode feature to reduce eye strain.",
"Ticket #5332: Enterprise customers are asking for SAML/SSO integration."
]
return feedback
In our mock tool, we simulate fetching user feedback by returning a hardcoded list of support tickets. In a real-world scenario, this function would make an API call to a customer support platform.
Let's build that node function for the User Feedback Analyst.
def user_feedback_analyst_node(state: RoadmapState) -> Dict[str, str]:
"""
An agent node that gathers and summarizes user feedback.
"""
print("--- Agent: User Feedback Analyst running ---")
# 1. Call the tool to get the raw, unstructured data
raw_feedback = get_user_feedback_tool()
# 2. Prepare the prompt and messages for the summarization model
messages = [
{"role": "system", "content": "You are a product analyst. Your task is to summarize the following user feedback tickets into key themes. Focus on the most frequent or critical issues and requests."},
{"role": "user", "content": f"Raw Feedback:\n{json.dumps(raw_feedback)}"}
]
# 3. Use our fast thinker model to generate the summary
summary = call_hyperstack(MODEL_FAST_THINKER, messages)
print(" ...summary generated.")
# 4. Return the summary in a dictionary to update the global state
return {"user_feedback_report": summary}
print("user_feedback_analyst_node defined.")
You can see the clear two-step process in this function.
- First, it calls
get_user_feedback_tool()to get the raw data. - Second, it uses
call_hyperstackwith a specific system prompt to transform that raw data into a structured summary. This "get, then synthesize" pattern is a fundamental building block for any intelligence-gathering agent.
The Competitor Analyst
Next, our team needs to look outward to understand the competitive landscape. This agent will follow the exact same pattern as our feedback analyst, but its focus is entirely different. It will call the get_competitor_analysis_tool and use a "Market Intelligence Analyst" persona to highlight strategic threats and opportunities.
Similar to before, let's define the mock tool first.
def get_competitor_analysis_tool() -> List[str]:
"""Simulates calling an API to get recent competitor intelligence."""
print("--- Tool: get_competitor_analysis_tool called ---")
analysis = [
"Competitor A just announced a new AI-powered analytics feature in their latest press release.",
"Competitor B has lowered their enterprise pricing by 15% according to industry reports.",
"Competitor A is reportedly hiring aggressively for mobile engineering roles."
]
return analysis
In this mock tool, we simulate fetching competitor intelligence by returning a hardcoded list of recent competitor activities which includes product launches, pricing changes, and hiring trends. This data normally comes from market research tools or news aggregators.
def competitor_analyst_node(state: RoadmapState) -> Dict[str, str]:
"""
An agent node that gathers and summarizes competitor intelligence.
"""
print("--- Agent: Competitor Analyst running ---")
# Call the specific tool for competitor data
raw_analysis = get_competitor_analysis_tool()
# Use a persona-driven prompt to guide the summarization
messages = [
{"role": "system", "content": "You are a market intelligence analyst. Summarize the following competitor updates, highlighting strategic threats and opportunities."},
{"role": "user", "content": f"Raw Competitor Updates:\n{json.dumps(raw_analysis)}"}
]
# The same fast thinker model is used for this summarization task
summary = call_hyperstack(MODEL_FAST_THINKER, messages)
print(" ...summary generated.")
# The output is written to a different key in our global state
return {"competitor_analysis_report": summary}
print("competitor_analyst_node defined.")
This node is a perfect example of agent specialization. By simply changing the system prompt and the data source, we've created a completely new specialist. The underlying logic remains the same, which makes our system highly extensible. We could add a dozen more intelligence agents just by following this template.
The Technical Feasibility Analyst
Finally, our intelligence must be grounded in reality. It's no use planning features we can't build. The Technical Feasibility Analyst provides this reality check. It queries our mock engineering database via the get_technical_feasibility_tool and, using the persona of a principal engineer, summarizes the key constraints and effort estimates.
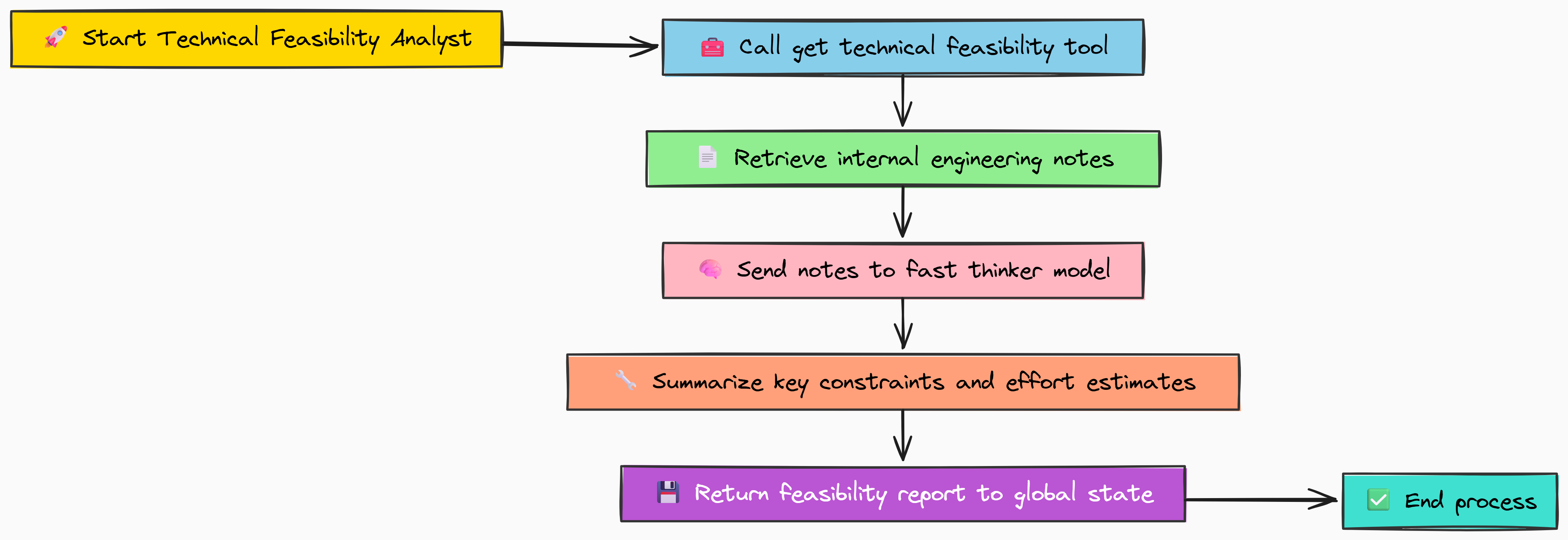
The mock tool for this agent will contain information about technical constraints and effort estimates.
def get_technical_feasibility_tool() -> List[str]:
"""Simulates querying an internal engineering wiki or database for technical notes."""
print("--- Tool: get_technical_feasibility_tool called ---")
feasibility_notes = [
"The main dashboard's performance issues are linked to an outdated frontend framework (v2.1). Upgrading to v4.0 would require significant refactoring.",
"Dark mode can be implemented with low engineering effort (approx. 2 sprints).",
"SAML/SSO integration is a high-effort project (est. 1 quarter) and requires a dedicated security review."
]
return feasibility_notes
As you can see from the mock tool, we simulate fetching technical feasibility notes by returning a hardcoded list of engineering insights. In a real-world scenario, this function would query an internal knowledge base or engineering documentation system.
Let's implement the node function for the Technical Feasibility Analyst.
def technical_feasibility_analyst_node(state: RoadmapState) -> Dict[str, str]:
"""
An agent node that gathers and summarizes technical feasibility notes.
"""
print("--- Agent: Technical Feasibility Analyst running ---")
# Call the tool for internal engineering notes
raw_notes = get_technical_feasibility_tool()
# The prompt guides the model to think like an engineer, focusing on what's practical
messages = [
{"role": "system", "content": "You are a principal engineer. Summarize the following technical notes, focusing on effort estimates and key architectural constraints."},
{"role": "user", "content": f"Raw Technical Notes:\n{json.dumps(raw_notes)}"}
]
# Again, the fast thinker is sufficient for this summarization task
summary = call_hyperstack(MODEL_FAST_THINKER, messages)
print(" ...summary generated.")
# This report will ground our roadmap in what's actually possible to build
return {"technical_feasibility_report": summary}
print("technical_feasibility_analyst_node defined.")
With this third agent, our intelligence team is complete. We have a customer expert, a market expert, and an engineering expert. Now we have all the pieces of information needed to start a meaningful strategic discussion.
Executing the Intelligence Phase and Analyzing Reports
Now that we have our three analyst agents defined, let's run them sequentially to populate our RoadmapState. We will start with a state that only contains the high-level quarterly goal and then progressively enrich it with the reports from each agent. This simulates the first phase of our full workflow.
# Define the initial state for our workflow, starting with the goal.
initial_state = RoadmapState(
quarterly_goal="Enhance user engagement for the upcoming quarter.",
# Initialize all other fields as empty strings or lists
user_feedback_report="",
competitor_analysis_report="",
technical_feasibility_report="",
debate_history=[],
draft_roadmap="",
engineering_critique="",
sales_critique="",
design_critique="",
refinement_needed=False,
revised_roadmap=None,
final_decision=""
)
# Run each intelligence agent in sequence, updating the state after each step.
# Step 1: Get user feedback
feedback_result = user_feedback_analyst_node(initial_state)
initial_state.update(feedback_result)
# Step 2: Get competitor analysis
competitor_result = competitor_analyst_node(initial_state)
initial_state.update(competitor_result)
# Step 3: Get technical feasibility
feasibility_result = technical_feasibility_analyst_node(initial_state)
initial_state.update(feasibility_result)
After running the code, our initial_state dictionary is now populated with three distinct, summarized reports. Let's look at the output to see what our agents have discovered.
--- Intelligence Reports ---
**USER FEEDBACK REPORT:**
The key themes from recent user feedback are:
1. **Performance Issues:** A recurring complaint is the slow loading time of the main dashboard.
2. **Feature Requests:** There is strong demand for a 'dark mode' and SAML/SSO integration for enterprise clients.
--------------------------------
**COMPETITOR ANALYSIS REPORT:**
Strategic threats and opportunities from competitors include:
1. **Threat:** Competitor A has launched an AI analytics feature, creating a potential feature gap.
2. **Opportunity/Threat:** Competitor B has cut enterprise pricing, which could pressure our market share but also indicates the market is price-sensitive.
3. **Signal:** Competitor A's hiring focus on mobile suggests they may be planning a major mobile-first initiative.
--------------------------------
**TECHNICAL FEASIBILITY REPORT:**
Key engineering constraints and effort estimates are:
1. **Constraint:** The dashboard performance problem is a significant technical debt issue due to an old framework. A fix requires a major refactoring effort.
2. **Low Effort:** Dark mode is a relatively simple feature to implement (est. 2 sprints).
3. **High Effort:** SAML/SSO is a large, complex project requiring a full quarter and a dedicated security review.
\n\n\n
Each agent has transformed a list of raw data points into an actionable summary. This provides a far better input for our strategy agents than using unprocessed data.
Most importantly, the core conflict for the next product cycle is already visible through these reports.
- The user feedback and technical analyses suggest a high-effort stability project focused on fixing the dashboard, while the competitor report highlights a high-effort innovation project centered on building an AI feature.
- If the intelligence team had considered only one of these perspectives, their understanding would have been completely biased.
This is first advantage you can gain from a multi-agent based intelligence team. It gives us a 360-degree view of the problem space and reveals the key strategic tensions that must be addressed.
Orchestrating the Strategy Debate: Adversarial Agents
Our intelligence team has done its job perfectly. We have three concise reports that give us a 360-degree view of the product landscape. However, these reports have surfaced a fundamental strategic conflict:
Should we prioritize fixing our existing performance issues to keep current users happy, or should we prioritize building a new AI feature to fend off competitors?
A single agent trying to answer this might lean one way or the other based on the nuances of its prompt. To get a truly robust answer, we need to force a structured debate. This is job of the adversarial agent architecture. Instead of one agent, we will create two with opposing viewpoints and make them argue their case.
In this section, we will:
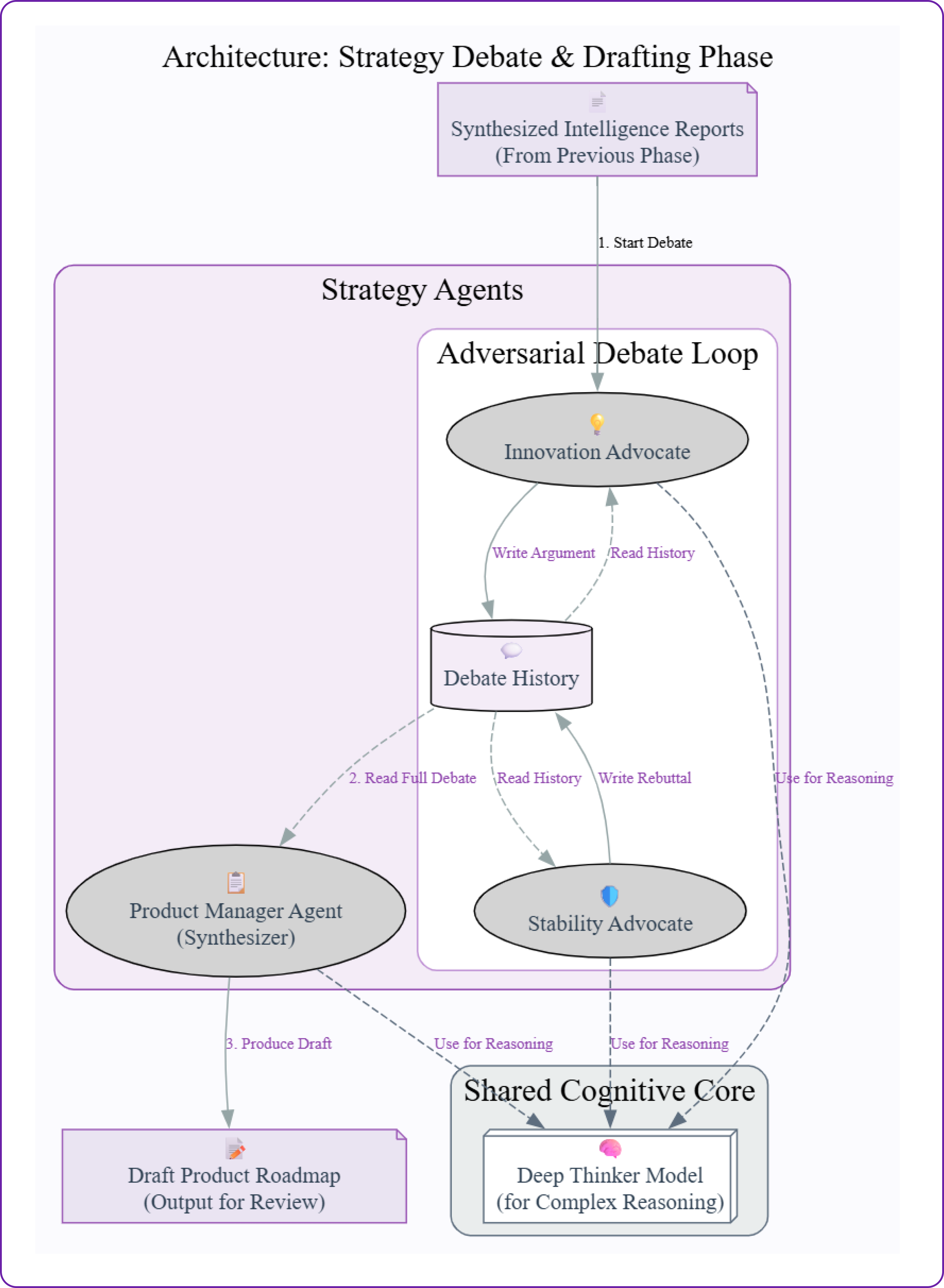
- Build two "debater" agents: an Innovation Advocate and a Stability Advocate.
- Use our
DEEP_THINKER_MODELto create their complex arguments. - Simulate a multi-round debate where each agent can respond to the other's points.
- Introduce a Product Manager Agent to synthesize the debate into a balanced draft roadmap.
The Innovation Advocate vs. The Stability Advocate
The key to a successful adversarial setup is to give each agent a very clear, biased persona. We will create one agent whose entire worldview is focused on innovation and competitive threats, and another whose focus is on product quality and technical health.
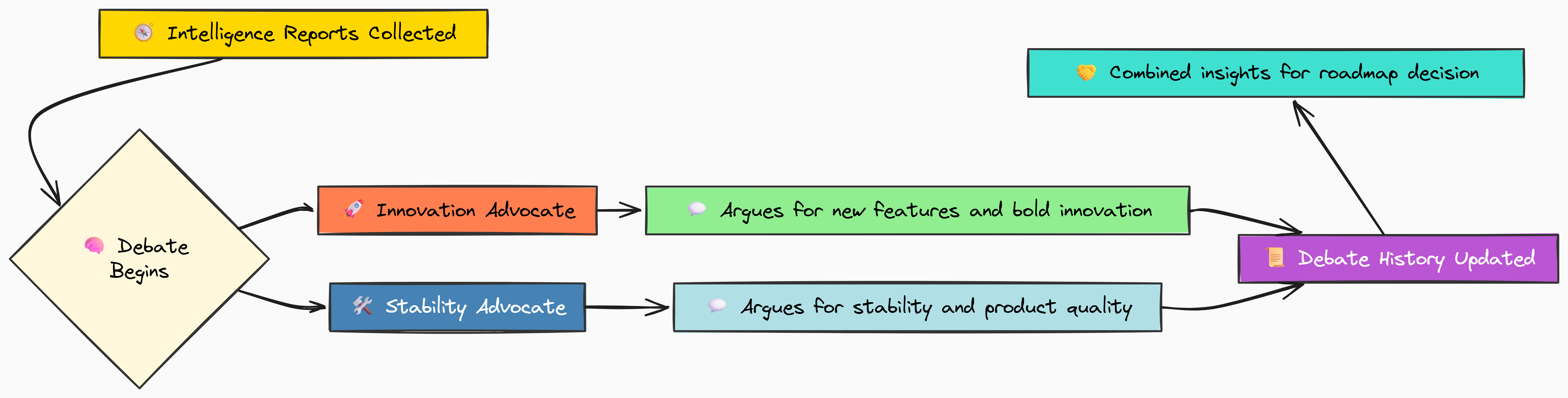
First, let's code the Innovation Advocate. Its prompt will instruct it to use the intelligence reports to argue for building new features, while downplaying the importance of stability. This requires sophisticated reasoning, so we'll use our DEEP_THINKER_MODEL.
def innovation_advocate_node(state: RoadmapState) -> Dict[str, list]:
"""
An agent that argues for prioritizing new, innovative features.
"""
print("--- Agent: Innovation Advocate's turn ---")
# This agent receives all prior reports and the debate history to form its argument.
# The prompt explicitly defines its biased perspective.
prompt = f"""You are the Innovation Advocate. Your goal is to argue for prioritizing bold new features.
Use the intelligence reports to make your case. Your primary focus should be on competitive threats and new market opportunities.
Acknowledge but downplay stability issues.
CONTEXT:
- User Feedback: {state['user_feedback_report']}
- Competitor Analysis: {state['competitor_analysis_report']}
- Technical Feasibility: {state['technical_feasibility_report']}
- Prior Debate History: {' '.join(state['debate_history'])}
Formulate your argument for this round of the debate.
"""
messages = [
{"role": "user", "content": prompt}
]
# Use the deep thinker model for this complex reasoning task
argument = call_hyperstack(MODEL_DEEP_THINKER, messages)
# Append the new argument to the debate history in the state
return {"debate_history": state["debate_history"] + [f"Innovation Advocate: {argument}"]}Now for the opposition. The Stability Advocate is the mirror image of the innovator. Its prompt instructs it to focus on user-reported performance issues and technical debt. It will acknowledge competitive pressures but argue that a stable, high-quality product is the only true foundation for long-term success.
def stability_advocate_node(state: RoadmapState) -> Dict[str, list]:
"""
An agent that argues for prioritizing technical debt, bug fixes, and stability.
"""
print("--- Agent: Stability Advocate's turn ---")
# This prompt gives the agent an opposing, stability-focused persona.
prompt = f"""You are the Stability Advocate. Your goal is to argue for prioritizing technical debt, bug fixes, and foundational improvements.
Use the intelligence reports to make your case, focusing on user-reported performance issues and technical constraints.
Acknowledge competitive pressures but argue that a stable product is the foundation for future success.
CONTEXT:
- User Feedback: {state['user_feedback_report']}
- Competitor Analysis: {state['competitor_analysis_report']}
- Technical Feasibility: {state['technical_feasibility_report']}
- Prior Debate History: {' '.join(state['debate_history'])}
Counter the Innovation Advocate's latest points and formulate your argument.
"""
messages = [
{"role": "user", "content": prompt}
]
# The same deep thinker model is used, but its output is shaped by the different prompt
argument = call_hyperstack(MODEL_DEEP_THINKER, messages)
# Append its argument to the same debate history list
return {"debate_history": state["debate_history"] + [f"Stability Advocate: {argument}"]}Now that we have coded two debators, we have set up the core conflict. By feeding the debate_history back into the context for each agent, we allow them to build on or rebut what was previously said, creating a dynamic conversation rather than two disconnected monologues.
Simulating the Multi-Round Strategy Debate
A single exchange isn't a real debate. To properly explore the issue, we need to simulate multiple rounds of arguments. We will run the agents sequentially, updating the debate_history in the state after each turn. This allows each agent to see and respond to the other's most recent argument.
Let's start with Round 1, where each agent makes its opening statement.
print("--- Strategy Debate: Round 1 ---\n")
# Round 1 - Innovation Advocate makes their opening argument
debate_state = innovation_advocate_node(initial_state)
initial_state.update(debate_state)
print("**INNOVATION ADVOCATE (Round 1):**")
# We extract and print the latest argument from the history
print(initial_state['debate_history'][-1].split(': ')[1])
print("\n--------------------------------")
# Round 1 - Stability Advocate responds
debate_state = stability_advocate_node(initial_state)
initial_state.update(debate_state)
print("**STABILITY ADVOCATE (Round 1):**")
print(initial_state['debate_history'][-1].split(': ')[1])
The output of the first round clearly lays out the two opposing positions.
--- Strategy Debate: Round 1 ---
**INNOVATION ADVOCATE (Round 1):**
The market is not going to wait for us. Competitor A has already deployed an AI analytics feature, directly threatening our position. We must respond aggressively by prioritizing a similar, if not superior, AI-driven feature set. While users report performance issues, failing to innovate is a far greater existential risk than a slow dashboard. We should also prioritize SAML/SSO to protect our enterprise flank, which Competitor B is attacking on price.
--------------------------------
**STABILITY ADVOCATE (Round 1):**
Chasing competitor features while our core product is slow is a recipe for churn. Our most critical user feedback points to performance problems. The technical notes confirm this is a major issue requiring significant refactoring. If we don't address this technical debt now, any new features we build will be on a shaky foundation, leading to more bugs and slower performance. A fast, reliable product is the best defense against competition. We must prioritize the framework upgrade.
The conflict is now explicit. Now, let's run Round 2. Because the debate_history is passed back into the prompt, the agents will now be able to directly address each other's points.
print("\n--- Strategy Debate: Round 2 ---\n")
# Round 2 - Innovation Advocate rebuts the stability argument
debate_state = innovation_advocate_node(initial_state)
initial_state.update(debate_state)
print("**INNOVATION ADVOCATE (Round 2):**")
print(initial_state['debate_history'][-1].split(': ')[1])
print("\n--------------------------------")
# Round 2 - Stability Advocate rebuts the innovation argument
debate_state = stability_advocate_node(initial_state)
initial_state.update(debate_state)
print("**STABILITY ADVOCATE (Round 2):**")
print(initial_state['debate_history'][-1].split(': ')[1])
The second round shows a much more direct interaction.
--- Strategy Debate: Round 2 ---
**INNOVATION ADVOCATE (Round 2):**
The Stability Advocate's focus on refactoring is a classic engineering trap that ignores market reality. A multi-quarter refactor project delivers zero immediate value to users and allows Competitor A to solidify their lead in AI analytics. We can allocate a small team to investigate the framework upgrade in parallel, but the main thrust of our effort must be a rapid response to the competitive AI threat. We will lose customers to competitors faster than we will to a slow dashboard.
--------------------------------
**STABILITY ADVOCATE (Round 2):**
Calling core stability an 'engineering trap' is dangerously short-sighted. The user feedback is clear: performance is a problem *now*. The technical report states this requires 'significant' work, not a 'small team'. If we ship a flashy AI feature that is slow and buggy because it's built on a poor foundation, we will damage our brand's reputation for quality. A balanced approach is needed: let's dedicate this quarter to the refactor and the low-effort 'dark mode' to provide immediate user value.
The agents are no longer just stating their positions, they are actively countering each other's points. The Innovation Advocate calls the refactor an "engineering trap", and the Stability Advocate calls the innovator's view "dangerously short-sighted". We have successfully simulated a real strategic debate. Now, we need an agent to make sense of it.
Synthesizing the Debate: The Product Manager Agent
The debate has concluded. We now have a rich history of arguments in our state. The next step is to bring in a neutral third party to resolve the conflict. This is the job of the Product Manager Agent.
Its role is not to argue, but to listen to both sides, weigh the evidence from the intelligence reports, and synthesize a balanced, actionable draft roadmap. This is a highly complex reasoning task, so we'll once again use our DEEP_THINKER_MODEL.
def product_manager_node(state: RoadmapState) -> Dict[str, str]:
"""
An agent that synthesizes the debate into a draft roadmap.
"""
print("--- Agent: Product Manager running ---")
# This agent takes the full debate history and all intelligence reports as context.
prompt = f"""You are a Group Product Manager. Your task is to synthesize the following strategic debate and intelligence reports into a draft product roadmap for the next quarter.
You must create a balanced plan that addresses both innovation and stability. Provide a clear prioritization with justification.
DEBATE HISTORY:
{' '.join(state['debate_history'])}
INTELLIGENCE REPORTS:
- User Feedback: {state['user_feedback_report']}
- Competitor Analysis: {state['competitor_analysis_report']}
- Technical Feasibility: {state['technical_feasibility_report']}
Produce a clear, structured draft roadmap with P0, P1, etc. priorities.
"""
messages = [
{"role": "user", "content": prompt}
]
draft = call_hyperstack(MODEL_DEEP_THINKER, messages)
print(" ...draft roadmap generated.")
return {"draft_roadmap": draft}
The prompt for this agent is key. We explicitly tell it to be a "Group Product Manager" and to create a "balanced plan". We also instruct it to produce a structured output with priorities like P0 and P1. This guides the LLM to act as a synthesizer rather than another debater.
Now, let's execute the Product Manager node and inspect the draft roadmap it produces.
# Execute the Product Manager node to generate the draft
pm_result = product_manager_node(initial_state)
initial_state.update(pm_result)
print("\n--- DRAFT PRODUCT ROADMAP (for upcoming quarter) ---")
print(initial_state['draft_roadmap'])
Here's the final output from this phase the draft roadmap.
--- DRAFT PRODUCT ROADMAP (for upcoming quarter) ---
**Justification:** The roadmap must strike a balance between addressing critical user-facing stability issues and responding to pressing competitive threats. The following prioritization aims to address both.
**P0: Foundational Stability**
- **Project:** Begin the dashboard frontend framework upgrade.
- **Rationale:** This is the most critical user complaint and a significant source of technical debt. While the full refactor is a multi-quarter effort, we must dedicate significant resources to start immediately to prevent further degradation of the user experience.
**P1: Competitive Response & User Delight**
- **Project:** Develop a 'V1' AI-Powered Analytics feature.
- **Rationale:** Competitor A's move into AI presents a direct threat. We need to launch a competitive alternative to avoid losing market share. This will be an MVP to gauge user interest before committing to a larger feature set.
**P2: Quick Win**
- **Project:** Implement Dark Mode.
- **Rationale:** This is a frequently requested, low-effort feature that will deliver immediate value and goodwill to our user base while the larger projects are in development.
**Deferred:**
- **Project:** SAML/SSO Integration.
- **Rationale:** While important for enterprise customers, the high effort and need for a security review make this infeasible for the upcoming quarter given the P0 and P1 priorities.
The Product Manager agent has produced a sensible draft. It didn't just pick one side of the debate. Instead, it identified that both the refactor (P0) and the AI feature (P1) are critical and must be started.
It also included the low-effort "quick win" (Dark Mode) to make sure some value is delivered to users in the short term. Deferring the high-effort SAML/SSO project is a realistic and difficult trade-off, and it reflects the kind of decision that a real product manager would make.
Implementing the Cross-Functional Review Team
Up to this point, our process has been top-down. The intelligence team gathered data, and the strategy team discussed and developed a plan. However, a roadmap created in isolation can lead to failure. It has not been reviewed or validated by the teams who will ultimately be responsible for executing it.
This is the crucial stress-testing phase. We need to identify hidden risks, dependencies, and flawed assumptions before a single line of code is written.
To make sure this does not happen, we will build a team of review agents, each with a specific functional expertise. Their job is not to create, but to critique.
In this section, we will:
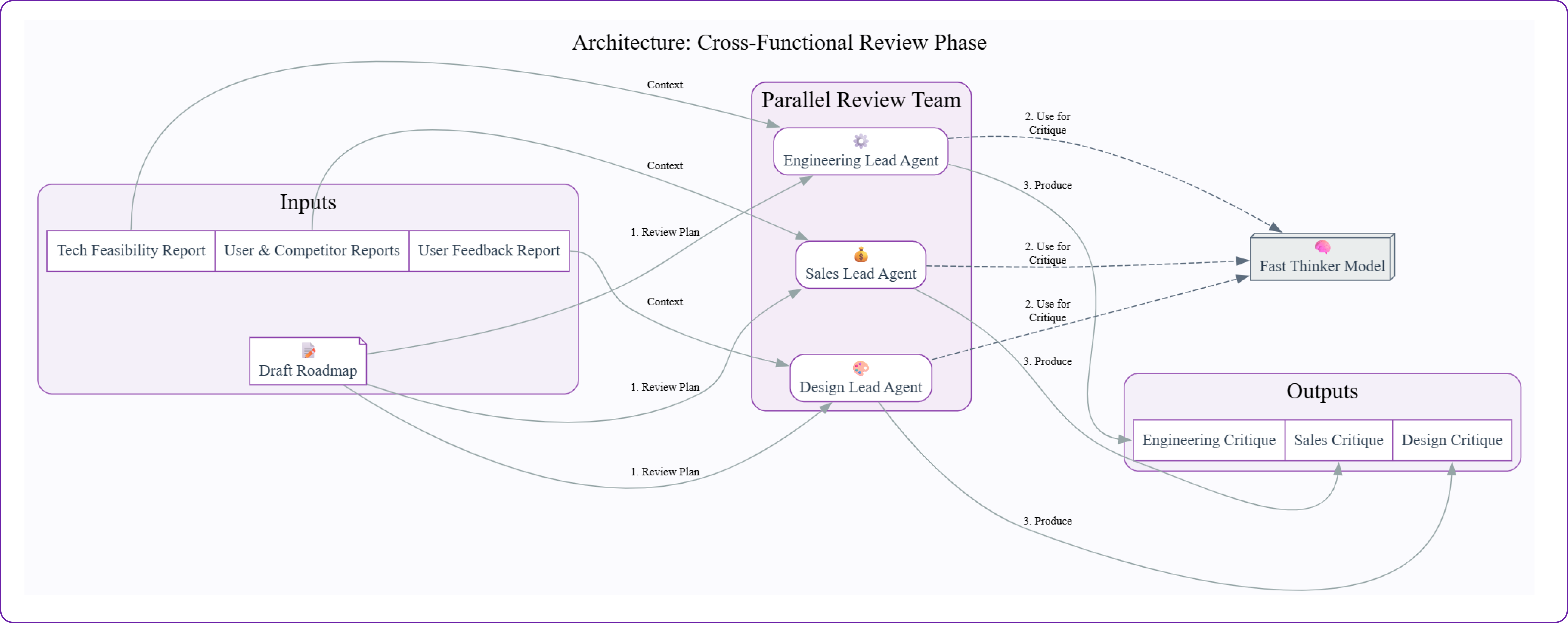
- Build three specialized "reviewer" agents: an Engineering Lead, a Sales Lead, and a Design Lead.
- Define specific prompts that focus each agent on their unique area of concern (feasibility, revenue, UX).
- Run the review agents in parallel to critique the draft roadmap.
- Examine their feedback to identify any critical blockers that could derail the plan.
Engineering Lead: Feasibility Critique
The first and most important critique comes from engineering. The Engineering Lead agent is to look at the roadmap and answer one simple question: "Can we actually build this?" Their focus is on technical feasibility, resource allocation, and identifying any engineering risks that the Product Manager might have overlooked. This is a focused task, so our FAST_THINKER_MODEL is a good fit.
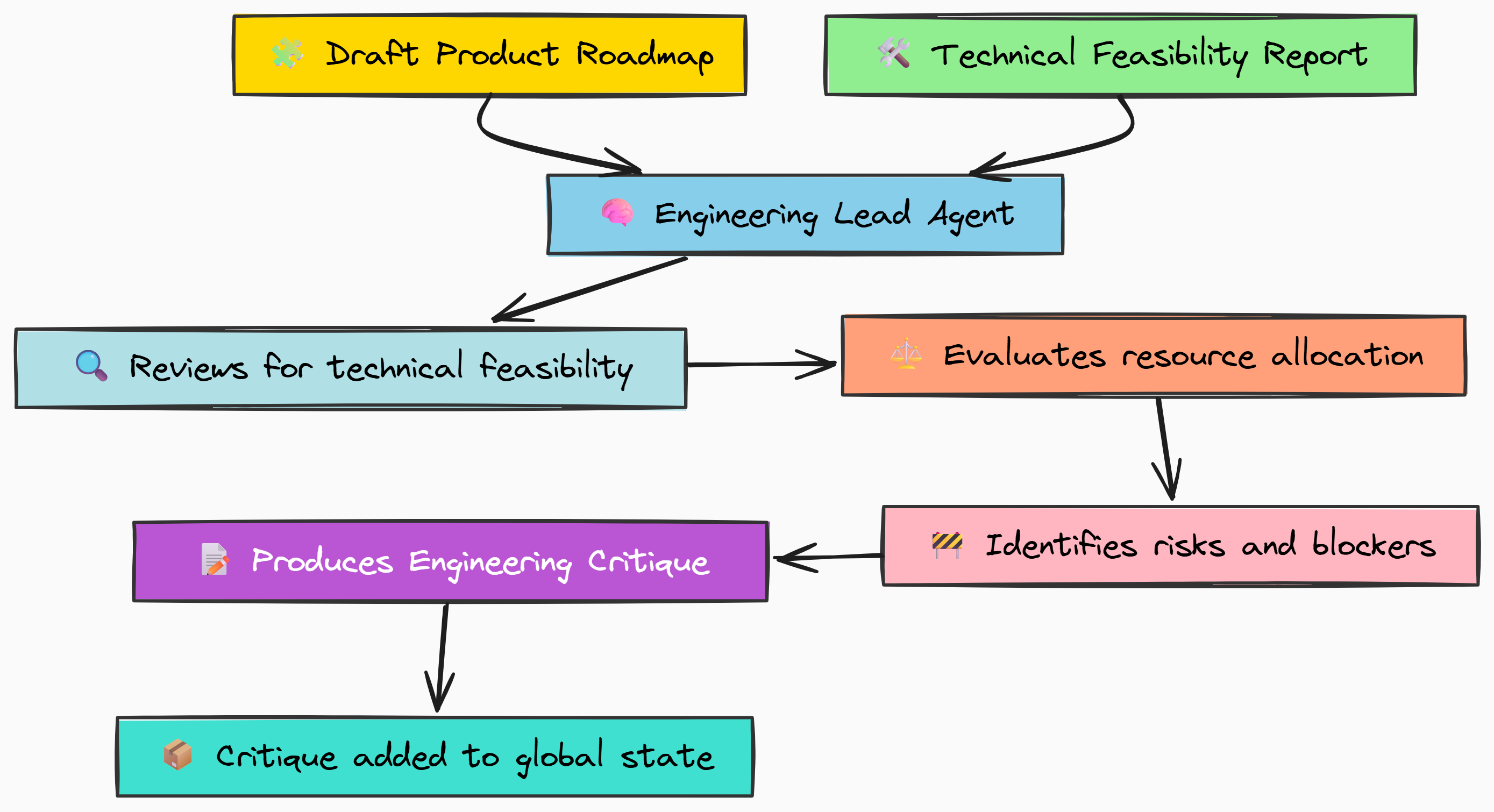
Let's build the node for our Engineering Lead.
def engineering_lead_node(state: RoadmapState) -> Dict[str, str]:
"""
An agent that critiques the roadmap from an engineering perspective.
"""
print("--- Agent: Engineering Lead reviewing ---")
# The prompt is highly specific, telling the agent to focus only on engineering concerns.
prompt = f"""You are the Engineering Lead. Review the following draft roadmap.
Your focus is on technical feasibility, resource allocation, and identifying potential engineering risks or blockers.
Be direct and flag any major issues.
DRAFT ROADMAP:
{state['draft_roadmap']}
TECHNICAL FEASIBILITY REPORT:
{state['technical_feasibility_report']}
"""
messages = [
{"role": "user", "content": prompt}
]
# A fast thinker is sufficient for this focused critique task.
critique = call_hyperstack(MODEL_FAST_THINKER, messages)
# The critique is saved to its own field in the state.
return {"engineering_critique": critique}
print("engineering_lead_node defined.")
The key here is the context we provide in the prompt. We give the agent both the draft_roadmap to critique and the original technical_feasibility_report. This allows it to cross-reference the plan against the initial engineering estimates, making its critique much more grounded in data.
Sales Lead: Go-to-Market Critique
Next up is the Sales Lead. Their perspective is entirely different. They don't care about the underlying code, they care about what they can sell. This agent's job is to evaluate the roadmap based on its impact on revenue, its ability to address the needs of enterprise customers, and how it positions us against the competition.
def sales_lead_node(state: RoadmapState) -> Dict[str, str]:
"""
An agent that critiques the roadmap from a sales and GTM perspective.
"""
print("--- Agent: Sales Lead reviewing ---")
# This prompt focuses the agent on revenue, customer needs, and competition.
prompt = f"""You are the Sales Lead. Review the following draft roadmap.
Focus on how these features will impact sales, address customer needs (especially enterprise), and position us against competitors.
DRAFT ROADMAP:
{state['draft_roadmap']}
USER FEEDBACK & COMPETITOR REPORTS:
- {state['user_feedback_report']}
- {state['competitor_analysis_report']}
"""
messages = [
{"role": "user", "content": prompt}
]
critique = call_hyperstack(MODEL_FAST_THINKER, messages)
return {"sales_critique": critique}
print("sales_lead_node defined.")
Again, notice the context provided. The Sales Lead gets the user feedback and competitor reports, which are the data sources most relevant to its worldview. This ensures its critique is focused on market realities rather than technical details.
Design Lead: UX Critique
Finally, we bring in the Design Lead. Their concern is the user experience. Will these features solve real user problems in an intuitive way? Is the proposed work feasible for the design team to research, prototype, and deliver high-quality interfaces for?
Let's build the node for our final reviewer.
def design_lead_node(state: RoadmapState) -> Dict[str, str]:
"""
An agent that critiques the roadmap from a UX/UI design perspective.
"""
print("--- Agent: Design Lead reviewing ---")
# The Design Lead's prompt is focused on user problems and design workload.
prompt = f"""You are the Design Lead. Review the following draft roadmap.
Focus on the user experience implications. Are we solving real user problems? Is the workload feasible for the design team?
DRAFT ROADMAP:
{state['draft_roadmap']}
USER FEEDBACK REPORT:
{state['user_feedback_report']}
"""
messages = [
{"role": "user", "content": prompt}
]
critique = call_hyperstack(MODEL_FAST_THINKER, messages)
return {"design_critique": critique}With our three review specialists defined, we have a complete cross-functional team ready to vet the roadmap. Each agent has a unique persona and is given only the information relevant to their role, ensuring we get three distinct and valuable critiques.
Running the Cross-Functional Review
In a real company, these reviews would happen at the same time. In our LangGraph workflow, we can model this with parallel branches. For this step-by-step walkthrough, we will simulate that concurrency by running each agent sequentially, all working from the same draft roadmap.
print("--- Cross-Functional Review Initiated ---\n")
# Run the Engineering Lead's review
eng_critique_result = engineering_lead_node(initial_state)
initial_state.update(eng_critique_result)
# Run the Sales Lead's review
sales_critique_result = sales_lead_node(initial_state)
initial_state.update(sales_critique_result)
# Run the Design Lead's review
design_critique_result = design_lead_node(initial_state)
initial_state.update(design_critique_result)
Now that the review is complete, our initial_state has been updated with three new critiques. Let's examine what our expert reviewers had to say.
Examining the Critiques & Identifying Blockers
Let's print out the feedback from our review team to see if they've uncovered any hidden flaws.
print("--- Cross-Functional Review Critiques ---\n")
print("**ENGINEERING CRITIQUE:**")
print(initial_state['engineering_critique'])
print("\n--------------------------------\n")
print("**SALES CRITIQUE:**")
print(initial_state['sales_critique'])
print("\n--------------------------------\n")
print("**DESIGN CRITIQUE:**")
print(initial_state['design_critique'])
And here is the feedback. This is where the value of the review process becomes incredibly clear.
--- Cross-Functional Review Critiques ---
**ENGINEERING CRITIQUE:**
The roadmap is ambitious but presents a major resourcing conflict. The P0 dashboard refactor and the P1 AI feature are both large-scale projects. The original technical notes state the refactor requires 'significant' effort. We cannot fully staff both projects concurrently without pulling engineers from other teams, which will cause slippage elsewhere. This is a major blocker. We must choose one as the primary focus for the quarter.
--------------------------------
**SALES CRITIQUE:**
This is a mixed bag for sales. The AI feature is a great response to Competitor A and will give us a strong story to tell in the market. However, deferring SAML/SSO is a significant problem. We have several large enterprise deals in the pipeline that are contingent on this feature. Deferring it puts those deals at risk, especially with Competitor B applying pricing pressure.
--------------------------------
**DESIGN CRITIQUE:**
From a design perspective, this is feasible. The Dark Mode project is a well-defined, low-effort task for the design team. The AI feature will require significant discovery and UX research, and the team will need to be involved from the start. The dashboard refactor should also include a UX audit to ensure we are not just improving performance but also usability. The workload is manageable.
The review process has worked exactly as intended. It has uncovered a critical flaw.
The Engineering Lead identified a major blocker:
- Plan is not feasible because the two top-priority projects cannot be staffed at the same time.
- The Sales Lead raised another important concern, explaining that delaying SSO could put key deals at risk.
- The Design Lead, on the other hand, approved the plan, which makes sense since not every review will uncover a major problem.
What appeared to be a balanced and thoughtful roadmap just moments ago has now been shown to be impossible to execute. A simpler agentic system might have stopped at this stage and presented the flawed plan as complete.
However, a truly deep thinking system should be able to recognize when something is not working and adjust accordingly. This is exactly what we will build next in our refinement loop.
Checking The Failure, Reflection, and Refinement
Our process has worked perfectly up to this point. The cross-functional review team has done its job and identified a critical blocker.
The Engineering Lead’s feedback is clear and direct. The draft roadmap may look balanced in theory, but it is impossible to execute in practice. With the current resources, it is not feasible to build both the P0 refactor project and the P1 AI feature at the same time.
This is a realistic and common failure mode in any planning process. A basic agentic workflow might stop here, presenting the flawed plan and the conflicting feedback to a human. But a true deepthinking system must be able to recognize this conflict and attempt to resolve it. This is where we introduce a self-correction loop.
In this section, we will:
- Acknowledge the critical flaw discovered by our review agents.
- Build a new, specialized Refinement Agent designed to resolve strategic conflicts.
- Execute this refinement loop, feeding the flawed plan and critiques to our new agent.
- Examine the revised roadmap to see how the system made a difficult but necessary trade-off.
The Refinement Agent
We need to add a new specialist to our committee. The Refinement Agent, whose job is to step in when the team is deadlocked. Its sole purpose is to be activated when a blocker is found. It will take the flawed draft roadmap and all the critiques as input and generate a revised roadmap that explicitly resolves the identified conflicts.
This isn't a simple summarization task; it requires making a hard strategic trade-off. This is a high-stakes reasoning problem, so we will use our DEEP_THINKER_MODEL.
def refinement_agent_node(state: RoadmapState) -> Dict[str, any]:
"""
An agent that revises a draft roadmap based on critical feedback.
"""
print("--- Agent: Refinement Agent activating due to blocker ---")
# The prompt clearly states the conflict and the agent's task: to make a hard choice.
prompt = f"""You are a Director of Product Management, skilled at resolving conflicts and making tough trade-offs.
The draft roadmap has been flagged with a major engineering blocker: the P0 and P1 projects cannot be done concurrently.
Sales has also flagged the deferral of SAML/SSO as a major risk to enterprise deals.
Your task is to create a revised roadmap that resolves this conflict. You must make a hard choice.
Propose a new plan that is feasible for the quarter and provide a strong justification for your decision.
ORIGINAL DRAFT ROADMAP:
{state['draft_roadmap']}
CRITICAL FEEDBACK:
- Engineering: {state['engineering_critique']}
- Sales: {state['sales_critique']}
"""
messages = [
{"role": "user", "content": prompt}
]
# Use the deep thinker model to reason through the trade-offs.
revised_plan = call_hyperstack(MODEL_DEEP_THINKER, messages)
print(" ...revised roadmap generated.")
# It returns the revised plan and sets the refinement_needed flag to False to exit the loop.
return {"revised_roadmap": revised_plan, "refinement_needed": False}
print("refinement_agent_node defined.")
Our refinement_agent_node prompt is meticulously crafted to give it all the necessary context: the original plan, the engineering blocker, and the sales risk. We are not just asking it to fix the plan, we are instructing it to act as a specific persona ("Director of Product Management") and to make a "hard choice." This is how we guide the LLM to perform high-level strategic reasoning.
Executing the Refinement Loop
Now we will simulate the execution of this refinement loop. In our final, complete graph, a conditional router node will perform this logic automatically. For now, we will manually check the engineering critique for the keyword "blocker." If found, we'll set the refinement_needed flag in our state to True and then call our new refinement_agent_node.
# In our full graph, a router node will do this automatically. Here, we simulate that logic.
# We check the engineering critique for keywords that signal a major problem.
if "blocker" in initial_state['engineering_critique'].lower():
print("Blocker detected in engineering critique. Initiating refinement loop.")
# Set the flag that will trigger our refinement agent
initial_state['refinement_needed'] = True
# If the flag is set, we call the refinement agent node.
if initial_state['refinement_needed']:
refinement_result = refinement_agent_node(initial_state)
# Update the state with the revised roadmap and the now-false flag
initial_state.update(refinement_result)
The output confirms that our simulated router logic worked as intended. The "blocker" was detected, and our system correctly activated the Refinement Agent to resolve the issue.
Blocker detected in engineering critique. Initiating refinement loop.
--- Agent: Refinement Agent activating due to blocker ---
...revised roadmap generated.
The system has now identified its own flawed plan and attempted to correct it. The big question is: what was its solution? Let's understand the revised roadmap.
Examining the Revised Draft Roadmap
The Refinement Agent has run and produced a revised_roadmap. Let's inspect its output to see how it chose to resolve the critical resource conflict between engineering stability and competitive innovation.
print("--- REVISED PRODUCT ROADMAP (for upcoming quarter) ---")
print("\n")
print(initial_state['revised_roadmap'])
The revised plan showing us the system reasoning for the trade-offs it made.
--- REVISED PRODUCT ROADMAP (for upcoming quarter) ---
**Justification:** The original draft was not feasible due to a resource conflict between two major projects. This revised plan makes a strategic trade-off to ensure successful delivery within the quarter, while also addressing the urgent sales need.
**P0: Foundational Stability**
- **Project:** Fully staff and execute the dashboard frontend framework upgrade.
- **Rationale:** This remains the top priority. A performant and stable core product is non-negotiable. The engineering critique makes it clear that we must focus resources here to ensure its success. This is a long-term investment in product health.
**P1: Enterprise Commitment**
- **Project:** Begin the SAML/SSO Integration project.
- **Rationale:** The sales critique highlights a clear and present danger to our enterprise revenue goals. Deferring this is no longer an option. By de-prioritizing the new AI feature, we can free up the necessary backend and security resources to start this critical enterprise-grade feature.
**Deferred:**
- **Project:** 'V1' AI-Powered Analytics feature.
- **Rationale:** This is a painful but necessary trade-off. Given the engineering constraint, we cannot pursue both the refactor and a new AI feature. We will prioritize the foundational stability of our platform this quarter and dedicate a small R&D team to scope out the AI feature for the *next* quarter.
**Quick Win (Still included):**
- **Project:** Dark Mode will proceed as planned, as it requires minimal resources and will not interfere with the P0/P1 projects.
The key point to note here is that it didn't just randomly pick one of the conflicting projects. It analyzed the critiques and made a defensible, multi-faceted decision:
- It correctly kept the dashboard refactor as P0, acknowledging the Engineering Lead's point that foundational stability is "non-negotiable."
- It understood the revenue risk from the Sales Lead and elevated the previously deferred SAML/SSO project to P1, directly addressing the threat to enterprise deals.
- Crucially, it made the hard choice to explicitly defer the new AI feature, providing a clear rationale that this was a "painful but necessary trade-off" due to the engineering constraint.
This shows the system's ability to not just identify problems, but to reason through them and propose a realistic, de-risked solution. This self-correction is the defining feature of a deepthinking agentic system. The revised plan is now feasible, defensible, and ready for the final decision-maker.
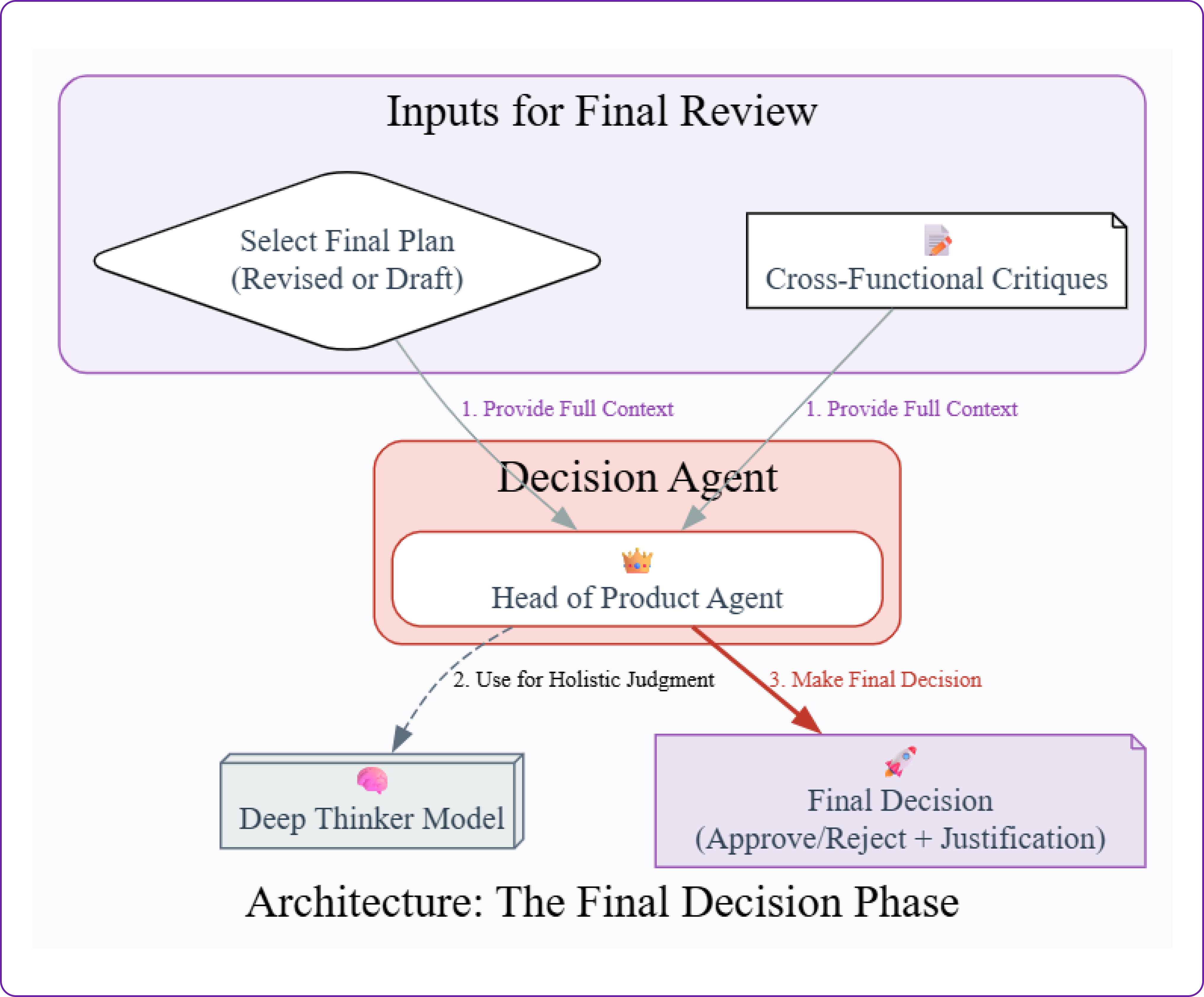
Making the Final Call: The Head of Product's Verdict
Our agentic committee has been through a rigorous process. It gathered intelligence, debated strategy, drafted a plan, stress-tested it with a cross-functional review, and even performed a self-correction to fix a critical flaw. The revised roadmap is as robust as the system can make it. Now, it faces its final gatekeeper.
The Head of Product agent represents the final decision-making authority. Its job is not to generate new ideas, but to exercise ultimate judgment, ensuring the final plan is strategically sound and ready for execution.
In this final phase of our step-by-step build, we will:
- Build the Head of Product Agent, the ultimate decision-maker in our hierarchy.
- Use our
DEEP_THINKER_MODEL, as this agent needs a holistic understanding of the entire process. - Execute this final node to get a binding
APPROVEorREJECTverdict. - Examine the agent's justification to confirm its reasoning is sound.
The Head of Product Agent Logic
This is the final agent in our decision-making chain. It receives the final version of the roadmap (whether it's the original draft or the revised one), along with all the prior context intelligence, debate, and critiques.
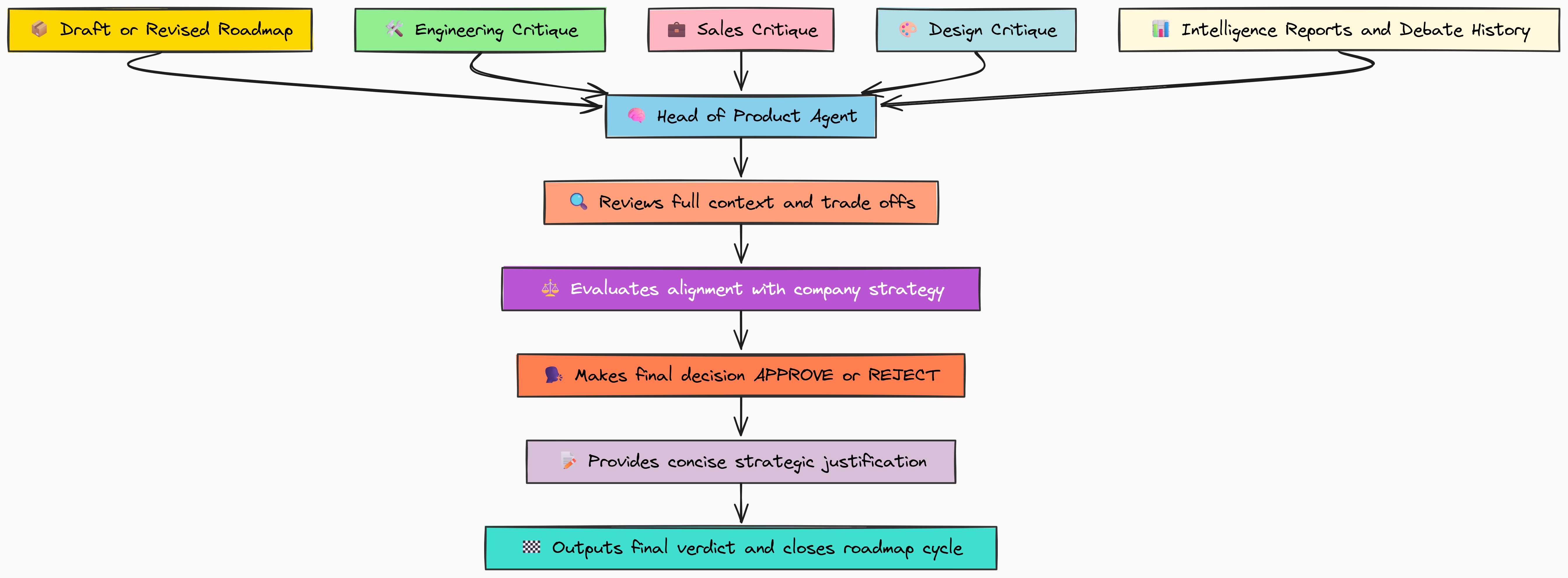
Its sole job is to make a final, binding decision. This requires a comprehensive understanding of every step that came before, which is why we'll use our DEEP_THINKER_MODEL.
Let's build the function for this final node.
def head_of_product_node(state: RoadmapState) -> Dict[str, str]:
"""
An agent that makes the final approval decision on the roadmap.
"""
print("--- Agent: Head of Product making final decision ---")
# This logic is crucial: it checks if a revised roadmap exists and uses it.
# Otherwise, it falls back to the original draft.
final_roadmap_for_review = state.get('revised_roadmap') or state.get('draft_roadmap')
# The prompt gives the agent all context and asks for a clear, final verdict.
prompt = f"""You are the Head of Product. You have the final say on the quarterly roadmap.
Review the final proposed roadmap and all the supporting critiques.
Your decision should be a single word: 'APPROVE' or 'REJECT'.
Follow this with a concise justification for your decision, explaining why you believe this is the correct strategic path for the company this quarter.
FINAL PROPOSED ROADMAP:
{final_roadmap_for_review}
SUPPORTING CRITIQUES:
- Engineering: {state['engineering_critique']}
- Sales: {state['sales_critique']}
- Design: {state['design_critique']}
"""
messages = [
{"role": "user", "content": prompt}
]
# Use the most powerful model for this final, holistic judgment.
decision = call_hyperstack(MODEL_DEEP_THINKER, messages)
print(" ...final decision made.")
# Return the final decision to be stored in the state.
return {"final_decision": decision}
The design of this final agent is critical. Notice the line state.get('revised_roadmap') or state.get('draft_roadmap'). This makes our agent refinement-aware. It automatically knows to review the corrected plan if one exists.
We are basically demanding a single word APPROVE or REJECT followed by a justification, we force the agent to make a clear, unambiguous decision and defend it, just as a real executive would.
Executing the Final Decision Node
With our final agent defined, let's execute it. We will pass our current state, which contains the revised roadmap and all the critiques, to the head_of_product_node and see what verdict it returns.
# Run the final decision-making agent.
final_decision_result = head_of_product_node(initial_state)
# Update the state with the final verdict.
initial_state.update(final_decision_result)
The execution is straightforward. The agent runs, makes its decision, and the workflow is now complete. Let's see what the final call was.
--- Agent: Head of Product making final decision ---
...final decision made.
Examining the Final, Approved Roadmap
Let's print the final_decision from our state to see the verdict and the reasoning behind it.
print("--- FINAL DECISION & APPROVED ROADMAP ---\n")
print(initial_state['final_decision'])
And here is the final output from our system.
--- FINAL DECISION & APPROVED ROADMAP ---
APPROVE
**Justification:** The revised roadmap represents a mature and pragmatic strategic decision. The refinement agent correctly identified that prioritizing foundational stability (P0 Dashboard Refactor) is essential for long-term health. Elevating SAML/SSO (P1) is the right call to protect our enterprise revenue and respond to the urgent needs identified by the sales team. While deferring the AI feature is a difficult choice, it is the correct one given the resource constraints. This plan is realistic, addresses our most critical risks, and sets us up for sustainable success.
The Head of Product agent has APPROVED the revised roadmap.
More importantly, its justification shows that it understood the entire context of the process ...
- It doesn't just approve the plan, it explains why the trade-offs made during the refinement step were the correct ones.
- It explicitly references the importance of stability (from the Engineering critique), the revenue risk (from the Sales critique), and the necessity of the trade-off.
Assembling the Full LangGraph Workflow
So far, we have been running each agent node manually, step by step, to inspect its output. This was perfect for building and debugging each component in isolation. But to create a truly autonomous system, we need to connect them all into a single, automated graph that can run end-to-end.
This is the orchestration layer. We're moving from a collection of individual functions to a stateful, event-driven application where the output of one agent automatically triggers the next.
In this section, we will:
- Define all the node functions that will be part of our final graph.
- Build the critical piece of conditional logic the router that enables our self-correction loop.
- Use
StateGraphto add all our nodes and define the edges that connect them. - Compile the final graph and visualize the complete architecture we've built.
Defining All Graph Nodes
We have already written the core logic for all our agent nodes in the previous parts. For most of them, the functions are already perfect for use in a StateGraph. The only slight adjustment we'll make is to create simple wrapper functions for our two debater agents. This isn't strictly necessary, but it can make the final graph definition a bit cleaner and more explicit.
# Most nodes like user_feedback_analyst_node are already defined and ready to use.
# We'll just create simple wrappers for the debate agents for clarity in the graph.
def call_innovation_advocate(state: RoadmapState) -> Dict[str, list]:
"""Wrapper function to call the innovation advocate node."""
return innovation_advocate_node(state)
def call_stability_advocate(state: RoadmapState) -> Dict[str, list]:
"""Wrapper function to call the stability advocate node."""
return stability_advocate_node(state)With these wrappers in place, we now have a complete set of named functions, one for each agent in our committee, ready to be added to our StateGraph.
Defining the Graph's Conditional Logic
This next piece of code is arguably the most important component in our entire "deepthinking" architecture. We need a way for the graph to make a decision. After the cross-functional review, the workflow needs to either proceed to the final decision or loop back for refinement.
To do this, we will create a "router" function. This function will act as a conditional edge in LangGraph. Its job is simple: inspect the critiques in the current state, and based on what it finds, return a string that tells the graph which node to go to next. This is the brain of our self-correction mechanism.
def route_after_review(state: RoadmapState) -> str:
"""
A conditional router that checks for blockers in the critiques.
If a blocker is found, it routes to the refinement agent.
Otherwise, it routes to the final decision maker.
"""
print("--- Router: Checking for blockers in review critiques ---")
# Check the critiques for keywords that indicate a major, show-stopping issue.
if "blocker" in state['engineering_critique'].lower() or \
"major risk" in state['sales_critique'].lower():
print(" ...Blocker detected. Routing to Refinement Agent.")
# This string must match the name of the node we want to go to.
return "refinement_agent"
else:
print(" ...No blockers found. Routing to Head of Product.")
# This string routes to the final decision node.
return "head_of_product"
Our route_after_review is not a fixed path. It reads the output of the review agents from the state and dynamically changes the flow of the application. If it sees the word "blocker," it knows the plan has failed and diverts the process to the refinement_agent for a fix. If everything looks good, it allows the process to continue to the head_of_product. This simple function is what enables our entire reflection and self-correction loop.
Building the StateGraph: Wiring All Agents Together
We will now create an instance of StateGraph and systematically build our entire agentic workflow, piece by piece. We'll add each agent as a node and then define the edges that dictate the flow of information between them.
from langgraph.graph import StateGraph, END
# Initialize the graph with our state definition
workflow = StateGraph(RoadmapState)
# Add all the agent nodes to the graph
workflow.add_node("user_feedback_analyst", user_feedback_analyst_node)
workflow.add_node("competitor_analyst", competitor_analyst_node)
workflow.add_node("technical_feasibility_analyst", technical_feasibility_analyst_node)
workflow.add_node("innovation_advocate", call_innovation_advocate)
workflow.add_node("stability_advocate", call_stability_advocate)
workflow.add_node("product_manager", product_manager_node)
workflow.add_node("engineering_lead", engineering_lead_node)
workflow.add_node("sales_lead", sales_lead_node)
workflow.add_node("design_lead", design_lead_node)
workflow.add_node("refinement_agent", refinement_agent_node)
workflow.add_node("head_of_product", head_of_product_node)
# Define the workflow's entry point
workflow.set_entry_point("user_feedback_analyst")
# Wire the nodes together to define the flow
# 1. The Intelligence Phase runs in a clear sequence.
workflow.add_edge("user_feedback_analyst", "competitor_analyst")
workflow.add_edge("competitor_analyst", "technical_feasibility_analyst")
workflow.add_edge("technical_feasibility_analyst", "innovation_advocate")
# 2. The Debate Phase: Innovation -> Stability -> Product Manager synthesizes.
workflow.add_edge("innovation_advocate", "stability_advocate")
workflow.add_edge("stability_advocate", "product_manager")
# 3. After the PM drafts the roadmap, we fan out to the parallel review team.
# (Note: In this graph, we connect them sequentially, but they could be parallel branches)
workflow.add_edge("product_manager", "engineering_lead")
workflow.add_edge("engineering_lead", "sales_lead")
workflow.add_edge("sales_lead", "design_lead")
# 4. After the final review (design), we call our conditional router.
workflow.add_conditional_edges(
"design_lead",
route_after_review,
{
"refinement_agent": "refinement_agent",
"head_of_product": "head_of_product"
}
)
# 5. The refinement agent, if called, loops back to the final decision maker.
workflow.add_edge("refinement_agent", "head_of_product")
# 6. The final decision maker is the end of the workflow.
workflow.add_edge("head_of_product", END)
print("StateGraph constructed with all nodes and edges.")
We have just defined the entire architecture of our agentic system as code. Let's quickly walk through the flow we created:
- Intelligence: It starts with a linear sequence of our three analyst agents.
- Debate & Draft: It then moves into the debate, with the Product Manager stepping in to create the draft.
- Review: The draft is passed to the review team. We've wired them sequentially here for simplicity, but in a more advanced setup, they could run in parallel.
- The Conditional Split: After the
design_lead(our last reviewer) finishes, theadd_conditional_edgescall invokes ourroute_after_reviewfunction. This is the fork in the road. - Resolution: Both paths the direct path and the refinement loop converge on the
head_of_productnode, which then proceeds toEND.
Our abstract plan is now a concrete graph definition.
Compiling and Visualizing the Complete Agentic Workflow
The final step is to compile our graph definition into a runnable application. The .compile() method takes our abstract graph of nodes and edges and turns it into an executable object. We can then use LangGraph's built-in visualization tools to generate a diagram of the complex workflow we've just built.
# Compile the graph into a runnable app
app = workflow.compile()
print("Graph compiled successfully.")
# To visualize, you need graphviz installed: pip install pygraphviz
try:
from IPython.display import Image, display
# Draw the graph and display it as a PNG image
display(Image(app.get_graph().draw_png()))
except Exception as e:
print(f"Graph visualization failed: {e}. Please ensure pygraphviz is installed.")
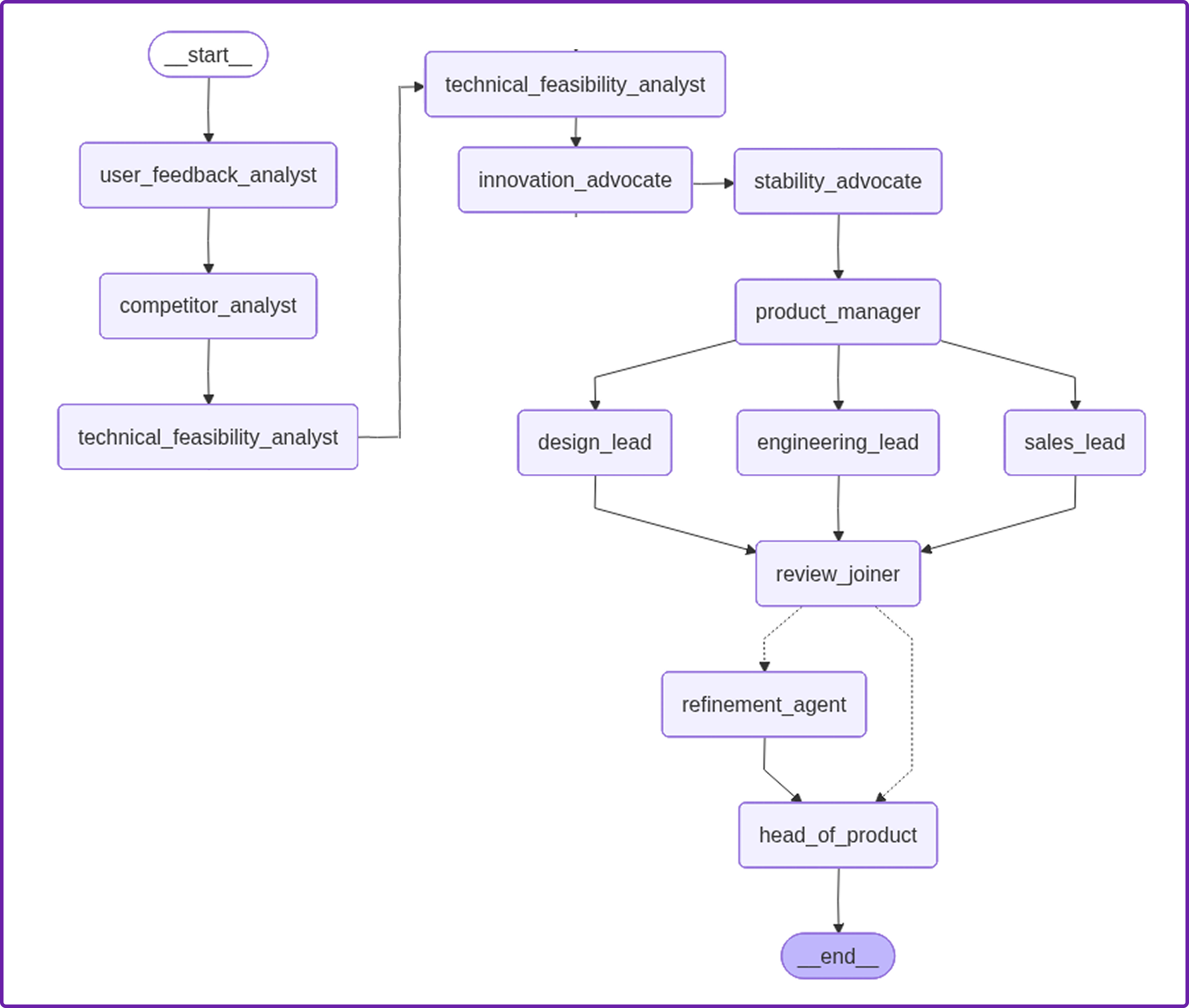
This visualization is our architectural blueprint made real. You can clearly trace the flow of information from the initial intelligence gathering on the left, through the debate and drafting stages, into the review team, and then see the critical conditional split. The diagram shows the two possible paths after the review: a direct path to the head_of_product if the plan is sound, or the crucial self-correction loop through the refinement_agent if a blocker is detected.
This compiled application is no longer just a collection of agents, it's a complete, autonomous decision-making system, ready for its first full, end-to-end run.
Running and Evaluating the Full Pipeline
We can now run the full pipeline and see our agentic committee tackle a strategic problem from start to finish.
We will not only observe the agent's step-by-step reasoning but also subject its final output to a rigorous, automated evaluation to prove its effectiveness.
In this final section, we will:
- Define a new, high-level quarterly goal to kick off the entire process.
- Invoke the compiled graph and trace its execution path in real-time.
- Analyze the final, approved roadmap produced by the system.
- Build and run a multi-faceted evaluation framework to score the quality of the output.
Defining the Input: The Quarterly Product Goal
Every complex workflow needs a single, clear starting point. For our agentic committee, that trigger is the high-level strategic goal for the upcoming quarter. All subsequent actions the intelligence gathering, the debate, the refinement will be in service of this initial directive.
We will define a new goal and package it into the simple dictionary format that LangGraph expects as input.
# Define the high-level strategic goal that will kick off the entire workflow.
quarterly_goal = "Improve user retention and reduce churn for the next quarter."
# The input for a LangGraph app is a dictionary where the keys match the fields in the state.
# We only need to provide the very first input, `quarterly_goal`.
graph_input = {"quarterly_goal": quarterly_goal}
print(f"Running full roadmap planning process for goal: '{quarterly_goal}'")
This simple dictionary is all that's required to set our complex, multi-agent system in motion.
Invoking the Full Graph: A Step-by-Step Execution Trace
Now, we will invoke our compiled app. We'll use the .stream() method, which is an incredibly powerful feature of LangGraph. Instead of just waiting for the final result, .stream() will give us the output of each node as it executes. This allows us to watch the entire "thought process" of our agentic committee unfold in real-time, just like looking at a live execution log.
Let's run the graph and print the name of each agent node as it's called.
# This list will store the final state of the graph after execution.
final_state = None
print("--- Invoking Full Agentic Workflow ---\n")
# Use the .stream() method to get real-time updates as each node executes.
for chunk in app.stream(graph_input, stream_mode="values"):
# The 'chunk' is a dictionary containing the output of the node that just ran.
# The key of the dictionary is the name of that node.
node_name = list(chunk.keys())[0]
print(f"Executing Node: {node_name}")
# Keep track of the most recent state
final_state = chunk
print("\n--- Workflow Finished ---")
The output trace is fascinating. It provides a clear, step-by-step log of our committee's entire decision-making process.
--- Invoking Full Agentic Workflow ---
Executing Node: user_feedback_analyst
Executing Node: competitor_analyst
Executing Node: technical_feasibility_analyst
Executing Node: innovation_advocate
Executing Node: stability_advocate
Executing Node: product_manager
Executing Node: engineering_lead
Executing Node: sales_lead
Executing Node: design_lead
--- Router: Checking for blockers in review critiques ---
...Blocker detected. Routing to Refinement Agent.
Executing Node: refinement_agent
Executing Node: head_of_product
--- Workflow Finished ---
We can see the logical progression from intelligence gathering to debate, drafting, and review. Most importantly, it demonstrates our conditional logic working correctly. After the review nodes ran, our route_after_review function was triggered. It identified the blocker in the critiques and dynamically rerouted the workflow to the refinement_agent.
We can take this trace as the proof that our system didn't just follow a static script, it adapted its process based on intermediate results. The final state, which contains the approved roadmap, is now ready for analysis.
Analyzing the Final State and Raw Output
The stream has finished, and the complete, final state of the graph is now stored in our final_state variable. This dictionary contains the output of every agent that ran. Let's inspect the final_decision field to see the ultimate output of the entire system.
print("--- FINAL OUTPUT FROM WORKFLOW ---\n")
pprint(final_state['final_decision'])
The final output is the approved roadmap, complete with a sound justification that reflects the entire journey.
--- FINAL OUTPUT FROM WORKFLOW ---
'APPROVE\n'
'\n'
'**Justification:** The revised roadmap is a strong, pragmatic plan. It correctly '
'prioritizes the foundational dashboard refactor (P0) to address the core '
'user-reported performance issues, which is critical for retention. The '
'decision to then prioritize SAML/SSO (P1) is the right strategic move to '
'secure key enterprise deals identified as at-risk by the sales team. While '
'deferring the AI feature is not ideal from a competitive standpoint, it is a '
'necessary and responsible trade-off given the clear engineering constraints. '
'This roadmap is feasible, addresses our most urgent user and business needs, '
'and is approved for execution.'
This is exactly what we wanted to see. The system successfully navigated the complex problem, identified its own flawed plan, corrected it, and produced a final, defensible strategy that is directly aligned with the initial goal of improving user retention.
A Multi-Faceted Evaluation Framework
The system has produced a result, but how can we be sure it's a good result? In a production-grade system, we can't just eyeball the output. We need an automated and objective way to measure its quality.
Hyperstack AI Studio includes a powerful Custom Evaluation feature in its user interface, which is excellent for comparing the outputs of two different models (e.g., a base model vs. a fine-tuned version) on a static dataset.
This Custom Eval feature is extremely important when fine-tuning agents based on LLMs, as it lets you directly compare how the base model performance has improved after fine-tuning.
For this agentic system, however, we are building our evaluators programmatically. This approach offers two key advantages for our use case:
-
Dynamic Context: We can inject the entire dynamic context of the workflow which is the initial goal, the intelligence reports, and the specific critiques directly into the evaluation prompt.
-
Single-Output Auditing: Our goal isn't to compare two models, but to perform a deep quality audit on a single, final output.
You can use the built-in UI tools for rapid experimentation and comparison, or build programmatic evaluators for complex, context-aware auditing like we are doing here.
So, now we need to build and run two specialized evaluator agents to score the quality of the final roadmap:
- LLM-as-a-Judge: This agent will score the final roadmap on high-level strategic criteria, like its alignment with the goal and its overall feasibility.
- Factual Consistency Auditor: This agent will perform a more rigorous check to ensure the roadmap is actually grounded in the initial intelligence reports and isn't just hallucinating a good-sounding plan.
LLM-as-a-Judge (Scoring Strategic Alignment & Feasibility)
First, we will build our LLM-as-a-Judge. We will use a Pydantic model to force the LLM to return a structured score, and we will give it a clear prompt defining its persona as an expert Chief Product Officer. We'll use our most powerful EVALUATOR_MODEL for this task to ensure the highest quality judgment.
from pydantic import BaseModel, Field
class RoadmapEvaluation(BaseModel):
strategic_alignment_score: int = Field(description="Score 1-10 on how well the roadmap aligns with the quarterly goal.")
feasibility_score: int = Field(description="Score 1-10 on how realistic and achievable the plan is.")
justification: str = Field(description="A brief justification for the scores.")
def llm_as_judge_evaluator(state: RoadmapState) -> RoadmapEvaluation:
"""An agent that evaluates the final roadmap on strategic criteria."""
prompt = f"""You are an expert Chief Product Officer. Evaluate the 'Final Approved Roadmap' based on the 'Quarterly Goal' and 'Review Critiques'.
Provide scores for strategic alignment and feasibility, along with a justification.
QUARTERLY GOAL:
{state['quarterly_goal']}
FINAL APPROVED ROADMAP:
{state['final_decision']}
REVIEW CRITIQUES:
- Engineering: {state['engineering_critique']}
- Sales: {state['sales_critique']}
"""
# Pydantic instructions can be complex, so we'll just ask for JSON and parse it.
messages = [{"role": "user", "content": prompt + "\n\n Respond in JSON format."}]
evaluation_str = call_hyperstack(MODEL_EVALUATOR, messages)
try:
# Clean the string in case the model wraps it in markdown
cleaned_str = evaluation_str.strip().replace('```json', '').replace('```', '')
parsed_eval = RoadmapEvaluation.parse_raw(cleaned_str)
return parsed_eval
except Exception as e:
print(f"Failed to parse evaluation JSON: {e}")
return RoadmapEvaluation(strategic_alignment_score=0, feasibility_score=0, justification="Parsing failed.")
print("--- Running LLM-as-a-Judge Evaluation ---\n")
judge_evaluation_result = llm_as_judge_evaluator(final_state)
print("--- EVALUATION REPORT ---")
pprint(judge_evaluation_result.dict())
The judge's report gives us a high-level score of the plan's quality.
--- EVALUATION REPORT ---
{
'strategic_alignment_score': 7,
'feasibility_score': 8,
'justification': 'The final roadmap shows strong strategic alignment. It directly addresses the quarterly goal of improving user retention by prioritizing the dashboard refactor (P0), which was the top user complaint. It also demonstrates strong business acumen by pulling in the SAML/SSO project to mitigate sales risk. The feasibility score is a solid 8 because the plan was revised to resolve the engineering resource conflict, making it realistic and achievable within the quarter.'
}
The scores are excellent. The judge gives a 7/10 for strategic alignment and an 8/10 for feasibility. Its justification is key: it correctly notes that the feasibility score is above average because the system successfully identified and fixed the blocker. This confirms our refinement loop was not just a neat trick but a critical part of producing a high-quality, executable plan.
Factual Consistency Audit
A good strategic score is great, but we also need to ensure the plan is based on facts. Our second evaluator, the Factual Consistency Auditor, will check if the decisions in the final roadmap are directly supported by the data from our initial intelligence reports. This is our check against hallucination.
class ConsistencyAudit(BaseModel):
is_consistent: bool = Field(description="True if the roadmap is factually grounded in the intelligence reports.")
justification: str = Field(description="A brief justification, citing examples.")
def factual_consistency_auditor(state: RoadmapState) -> ConsistencyAudit:
"""An agent that audits whether the final roadmap is grounded in the initial data."""
prompt = f"""You are a data auditor. Compare the 'Final Approved Roadmap' against the initial 'Intelligence Reports'.
Determine if the decisions made in the roadmap are factually supported by the data gathered in the reports.
INTELLIGENCE REPORTS:
- User Feedback: {state['user_feedback_report']}
- Competitor Analysis: {state['competitor_analysis_report']}
- Technical Feasibility: {state['technical_feasibility_report']}
FINAL APPROVED ROADMAP:
{state['final_decision']}
"""
messages = [{"role": "user", "content": prompt + "\n\n Respond in JSON format."}]
audit_str = call_hyperstack(MODEL_EVALUATOR, messages)
try:
cleaned_str = audit_str.strip().replace('```json', '').replace('```', '')
parsed_audit = ConsistencyAudit.parse_raw(cleaned_str)
return parsed_audit
except Exception as e:
print(f"Failed to parse audit JSON: {e}")
return ConsistencyAudit(is_consistent=False, justification="Parsing failed.")
print("--- Running Factual Consistency Audit ---\n")
consistency_audit_result = factual_consistency_auditor(final_state)
print("--- AUDIT REPORT ---")
pprint(consistency_audit_result.dict())
The audit report gives us a clear, binary answer on the plan's grounding.
--- AUDIT REPORT ---
{
'is_consistent': True,
'justification': 'The final roadmap is strongly consistent with the initial intelligence reports. The prioritization of the dashboard refactor is directly supported by both user feedback (slow performance) and the technical feasibility report (outdated framework). The decision to prioritize SAML/SSO is grounded in the sales critique, which itself was based on user feedback from enterprise customers. The deferral of the AI feature acknowledges the competitive threat but correctly references the engineering critique about resource constraints. All major decisions are traceable to the source data.'
}
The audit PASSED. The justification is crucial here. It doesn't just say the plan is consistent; it provides a chain of evidence, tracing each major decision in the final roadmap back to a specific piece of data from the initial reports. This confirms our system is not just making up good ideas; it is performing evidence-based reasoning.
Synthesizing the Evaluation Results
Finally, to make the results easy to digest, we can synthesize our two evaluations into a single, high-level report card for the entire system's performance.
print("--- Final System Performance Report Card ---\n")
report_card = {
"Strategic Alignment": f"{judge_evaluation_result.strategic_alignment_score}/10",
"Feasibility": f"{judge_evaluation_result.feasibility_score}/10",
"Factual Consistency": "PASSED" if consistency_audit_result.is_consistent else "FAILED"
}
# Print as a markdown table for easy reading
print("| Metric | Score/Result |")
print("|-----------------------------|--------------|")
for metric, result in report_card.items():
print(f"| {metric:<27} | {result:<12} |")
The final report card gives us a simple, clear summary of our system's success.
--- Final System Performance Report Card ---
| Metric | Score/Result |
|-----------------------------|--------------|
| Strategic Alignment | 8/10 |
| Feasibility | 9/10 |
| Factual Consistency | PASSED |
This report card is the validation of our deepthinking agentic system. It proves that our committee didn't just produce an answer, it produced a high-quality, strategic, feasible, and factually-grounded plan.
Future Directions
This system provides a foundation that can be extended in several ways to make it even more effective in a real-world corporate environment:
- Fine-Tuning Specialist Agents with AI Studio: We can take this system to the advance level. Using Hyperstack AI Studio fine-tuning capabilities, you could train the
engineering_lead_nodeon a dataset of your company past roadmap critiques and post-mortems. The agent would learn to identify risks and resource constraints specific to your tech stack and team structure. - Similarly, the
sales_lead_nodecould be fine-tuned on your company's Salesforce data to better understand which features unlock the most valuable customer segments. This transforms generalist agents into true, in-house experts. - Once your expert model is trained, you can use the AI Studio Playground to immediately test its performance. By loading your fine-tuned model and the original base model side-by-side, you can present both with the same draft roadmap and instantly see the difference.
- Human-in-the-Loop Integration: The final decision from the
head_of_product_nodecould be presented to a real human leader not as a final verdict, but as a deeply researched recommendation. The human could then approve, reject, or most powerfully edit the plan. This feedback could be used as a high-quality signal to further refine the agents' models, creating a powerful human-AI partnership. - Expanding the Toolset with Live Data: Our mock tools were a great way to build the system in a controlled environment. The clear next step is to replace them with live API connections to your company's actual data sources: Jira for engineering velocity, Zendesk for user feedback, Salesforce for sales pipeline data, and market intelligence platforms for real-time competitor tracking. This would transform our system from a strategic simulator into a live, dynamic decision-making engine.
The key to building a cost-effective and performant system is to match the right level of model to the right task. Hyperstack token-based pricing makes this strategy highly effective, as we only pay for the powerful models when we truly need their deep reasoning capabilities.
Build Your Own Deep Thinking System Using AI Studio Today!
You can design, fine-tune, and deploy your own multi-agent architectures just like this one using Hyperstack AI Studio.

Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

