

TABLE OF CONTENTS
NVIDIA H100 SXM On-Demand
With AI compute demand increasing by 10× every 18 months, choosing the right cloud GPU provider for AI is now a performance and cost decision. The answer is: providers offering modern GPUs, strong networking and predictable pricing deliver the most value. This blog helps you pick a provider built for training and inference at scale.
Best Cloud GPU Providers for AI
A GPU as a service provider gives on-demand access to GPUs (H100, A100, L40s) for AI. We compared 5 providers on pricing, NVLink/RDMA support, network bandwidth and use cases, highlighting when to choose.
| Provider | Ideal AI Use Cases | Key Features | Pricing (Starting per Hour) |
|---|---|---|---|
| Hyperstack | Large-scale AI training, fine-tuning LLMs, and distributed inference | NVLink support, high-speed networking (350 Gbps), VM hibernation, AI Studio, NVMe storage, 1-click deployment, AI-optimised Kubernetes |
NVIDIA H200 SXM: $3.50 NVIDIA H100 SXM: $2.40, NVIDIA H100 PCIe: $1.90 NVIDIA RTX A6000: $0.50 |
| Runpod | Iterative model training, AI experimentation, dynamic workloads | Instant GPU launch, serverless autoscaling, FlashBoot (<200ms cold-start), persistent S3 storage, scale-on-demand | Pay-as-you-go (flexible, pricing varies by GPU type) |
| Lambda Labs | Enterprise AI, research, large model training | NVIDIA H100 & H200 GPUs, Quantum-2 InfiniBand networking, pre-configured Lambda Stack, 1-click clusters, on-demand/reserved options | H100/H200 GPUs: Starting ~$1.60–$2.50/hour |
| Paperspace (DigitalOcean) | Startups, prototyping, full ML lifecycle, collaborative workflows | Pre-built environments, version control, team collaboration tools, H100/A6000/RTX 6000 GPUs, easy-to-use UI |
H100: ~$2.20/hr A6000: ~$0.80/hr RTX 6000: ~$1.20/hr |
| Nebius | DevOps-integrated AI, multi-node training, scalable ML pipelines | NVIDIA H100, A100 & L40 GPUs, InfiniBand networking, API/CLI/Terraform control, hourly & reserved billing |
H100: ~$2.00/hr A100: ~$1.40/hr L40: ~$1.00/hr |
Top 5 Best Cloud GPU Providers for AI
Here are the best GPU as a service companies for AI in 2025:
1. Hyperstack
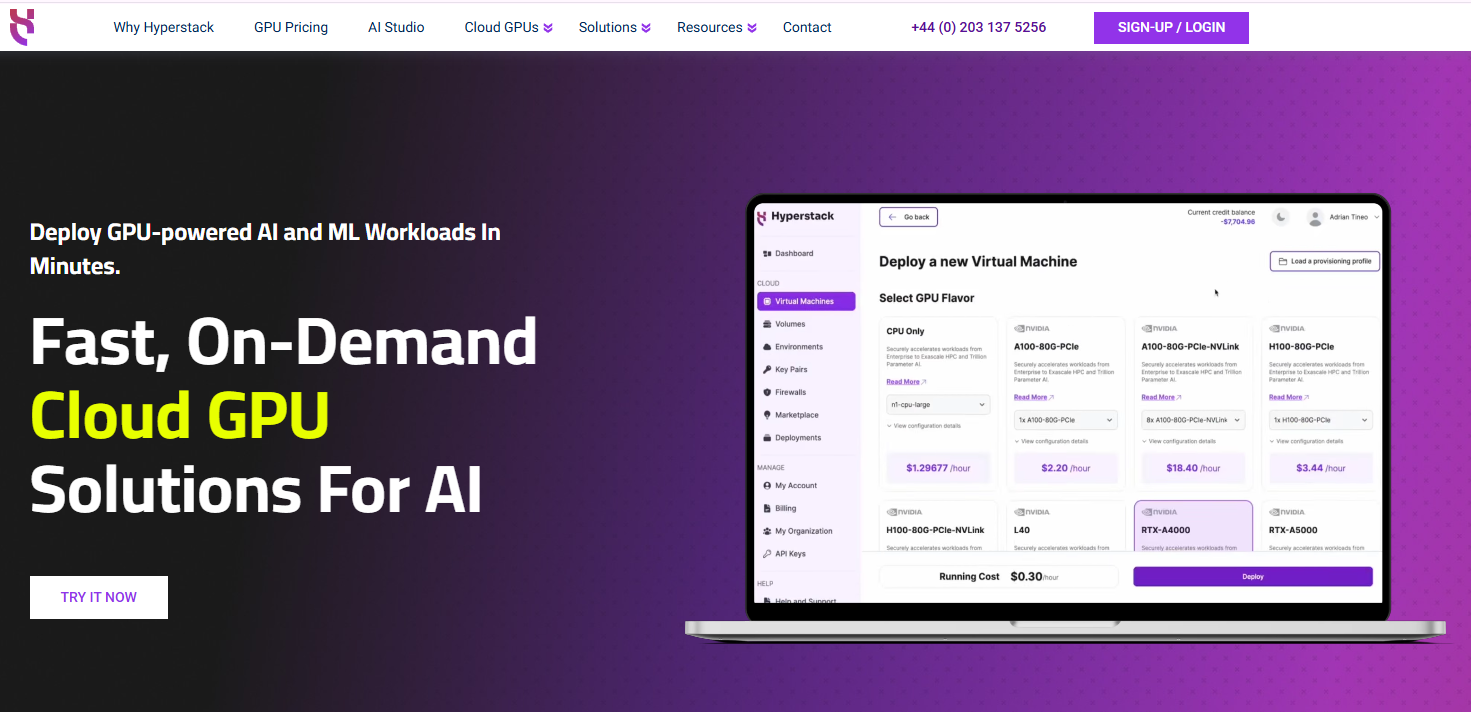
Hyperstack is a high-performance GPU cloud platform tailored for AI development and deep learning. It offers NVIDIA H100, A100, and L40 GPUs with NVLink support and high-speed networking up to 350 Gbps. Features like VM hibernation, minute-level billing, and real-time GPU availability help users optimise both performance and cost. Hyperstack also includes AI Studio—a no-code/low-code environment for managing GenAI workflows end-to-end.
Why Hyperstack is Ideal for AI
Hyperstack is not just another cloud provider. Our cloud platform is optimised to handle demanding AI workloads. Every feature we offer is designed to meet the performance and efficiency needs of our users:
-
NVLink support for scalable training and inference: We offer NVIDIA A100 and H100 GPUs with NVLink for ultra-fast GPU-to-GPU communication in multi-GPU setups. This reduces training time and improves efficiency in large model workloads.
-
High-speed networking: Hyperstack offers low-latency, high-throughput networking that enhances distributed training, parallel processing and real-time AI inference performance.
-
VM hibernation for cost efficiency: You can also pause unused workloads without losing state for full control over idle costs. This is useful during long AI experimentation cycles or intermittent development phases.
-
1-click deployment for rapid prototyping: You can launch environments instantly without manual configuration with 1-click deployment for faster iteration in AI training.
-
NVMe block storage for data-intensive workloads: We offer high-speed NVMe storage that ensures you get quick access to large datasets, improving overall performance in both model training and inference.
-
AI Studio for seamless model management: Our full-stack Gen AI platform where you can fine-tune and sell AI as a service easily, removing infrastructure complexity and accelerating time to market.
-
Flexible pricing and availability: With per-minute billing, Spot VMs and reservation options, you get predictable costs and full control over budget planning while maintaining GPU availability for demanding projects.
- AI-Optimised Kubernetes: For teams running complex containerised workloads, we provide on-demand, fully optimised Kubernetes clusters. These come with NVIDIA drivers, high-speed networking and scalable storage preconfigured, so you can easily orchestrate large AI/ML jobs.
Best Cloud GPUs for AI
Hyperstack offers a powerful range of NVIDIA cloud GPUs optimised for a wide range of AI workloads:
-
NVIDIA H100 PCIe and NVIDIA H100 SXM: Ideal for large-scale AI training, fine-tuning LLMs and complex inference workloads, delivering cutting-edge performance with NVLink and advanced tensor cores.
-
NVIDIA H200 SXM: Built for next-generation AI workloads requiring massive memory bandwidth and performance for transformer-based and generative AI models.
-
NVIDIA A100 PCIe: A balanced yet affordable choice for scalable AI training with NVLink support for multi-GPU setups.
-
NVIDIA L40: Optimised for performance AI workloads at an efficient cost.
-
NVIDIA RTX A6000: A versatile GPU suited for training smaller AI models and creative AI workflows requiring precision and visual performance.
-
NVIDIA RTX 6000 Pro SE: Perfect for advanced visual computing and AI inference workloads.
Hyperstack Cloud GPU Pricing for AI
We offer transparent and flexible cloud GPU pricing for AI with no hidden costs:
| GPU Model | Pricing Per Hour |
|---|---|
|
NVIDIA H200 SXM |
$3.50 |
|
NVIDIA H100 SXM |
$2.40 |
|
NVIDIA H100 NVLink |
$1.95 |
|
NVIDIA H100 |
$1.90 |
|
NVIDIA RTX A6000 |
$0.50 |
|
NVIDIA RTX 6000 Pro SE |
$1.80 |
|
NVIDIA A100 SXM |
$1.60 |
|
NVIDIA A100 NVLink |
$1.40 |
|
NVIDIA A100 |
$1.35 |
|
NVIDIA L40 |
$1.00 |
2. Runpod
Runpod is a serverless GPU platform built for fast, responsive AI workloads. It enables near-instant launches of GPU containers, which are ideal for iterative AI model tuning, small experiments and scale-on-demand use cases.
Why it’s ideal for AI:
- Instant GPU Launch for Faster AI Experimentation: Runpod enables developers to launch GPU pods in seconds and spin up a fully-loaded environment in under a minute. This speed is ideal for AI researchers and engineers running iterative model training, fine-tuning, and experimentation, allowing rapid testing and faster innovation cycles.
- Serverless Autoscaling for Dynamic AI Workloads: With Runpod’s Serverless architecture, AI workloads can scale automatically from zero to thousands of GPU workers in seconds. This elasticity is perfect for training or inference pipelines where compute demand fluctuates—ensuring performance when needed and cost savings when idle.
- FlashBoot: Runpod’s FlashBoot technology delivers near-instant scaling with cold-start times under 200 milliseconds. For AI inference applications that rely on real-time responseslike chatbots or image recognition, this ultra-fast startup ensures consistent low latency and uninterrupted execution.
- Persistent Network Storage: Runpod offers persistent, S3-compatible storage that allows AI teams to manage training data, model checkpoints, and inference outputs seamlessly without egress fees. This integration supports full data pipelines from ingestion to deployment within one environment, making it highly efficient for AI operations.
3. Lambda Labs

Lambda Labs offers enterprise-level GPU instances using NVIDIA H100 and H200, combined with Quantum-2 InfiniBand networking for ultra-low latency. Its Lambda Stack includes pre-installed ML frameworks, making it easier to deploy AI workflows. Users can launch 1-click clusters and choose between on-demand or reserved pricing models.
Why it’s ideal for AI:
-
H100 and H200 GPUs support large model training and inference
-
InfiniBand networking ensures fast, low-latency communication
-
Pre-configured Lambda Stack accelerates development setup
-
Cluster deployment supports scale-out workloads
-
Ideal for enterprise-grade AI applications and research
4. Paperspace (DigitalOcean)

Paperspace, now part of DigitalOcean, is a developer-focused GPU platform offering H100, A6000, and RTX 6000 GPUs. It includes pre-configured environments, version control, and collaboration tools for streamlined AI and ML workflows. Flexible pricing supports short-term and long-term projects.
Why it’s ideal for AI:
-
Pre-built environments for fast prototyping and reproducibility
-
Suitable for full ML lifecycle—training, testing, and deployment
-
Affordable for startups and individuals experimenting with AI
-
Built-in collaboration tools support team workflows
-
Easy-to-use UI lowers the entry barrier for new AI developers
5. Nebius

Nebius offers scalable GPU infrastructure powered by NVIDIA H100, A100, and L40, along with InfiniBand networking. It provides API, CLI, and Terraform-based control for complete customisation, and supports both hourly and reserved billing.
Why it’s ideal for AI:
-
InfiniBand enables high-throughput, multi-node model training
-
Full infrastructure control via API, CLI, and Terraform
-
Ideal for DevOps-integrated AI workflows
-
Flexible pricing adapts to prototyping and production phases
-
Supports large-scale ML and AI pipeline deployment
Get Started with Hyperstack Today and Build the Next Big Thing in AI

FAQs
What is a Cloud GPU Provider for AI?
A Cloud GPU provider for AI offers high-performance GPUs on demand, allowing developers to train, fine-tune and deploy AI models without investing in costly physical hardware.
Which is the best Cloud GPU Provider for AI?
Hyperstack is the best Cloud GPU provider for AI, offering high-performance NVIDIA A100, NVIDIA H100 GPUs with NVLink, high-speed networking and flexible per-minute billing for efficiency.
Which are the Best Cloud GPUs for AI Workloads?
The best Cloud GPUs for AI include NVIDIA H100, NVIDIA A100, NVIDIA H200 SXM, NVIDIA RTX A6000, ideal for large-scale training, inference and generative AI applications.
How much does a Cloud GPU for AI cost?
Cloud GPU pricing for AI depends on the model. On Hyperstack, pricing starts as low as $0.50/hour for NVIDIA RTX A6000 GPUs, offering pay-as-you-go flexibility for every workload.
How to choose the best cloud GPU provider for AI research?
When selecting a cloud GPU provider for AI research, the key factors are GPU performance, scalability, framework compatibility, cost-efficiency and ease of deployment. Hyperstack excels across all these dimensions — offering on-demand access to NVIDIA’s most powerful GPUs like the NVIDIA H100, NVIDIA A100 and NVIDIA L40. It’s designed for researchers and developers who need reliable, high-speed compute for model training, fine-tuning, and inference, all at transparent and competitive rates. The platform’s intuitive interface and flexible APIs make it ideal for academic, startup and enterprise-scale AI experimentation.
Which cloud GPU providers support popular AI frameworks?
Hyperstack supports popular AI and deep learning frameworks including TensorFlow, PyTorch and more . You can quickly spin up GPU VMs, integrate their preferred frameworks, and start training instantly.
What are the most affordable Cloud GPUs for AI?
Hyperstack provides affordable Cloud GPUs like the NVIDIA RTX A6000, NVIDIA A100 and NVIDIA L40, delivering high performance for AI training and inference at prices starting from $0.50/hour.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

