

TABLE OF CONTENTS
NVIDIA H100 SXM On-Demand
Deep learning workloads push hardware to its limits harder than almost any other use case, making the choice of the right cloud GPU provider critical. In this blog, we’ll explore the best providers for managing GPUs in deep learning and compare their features, performance, and scalability to help you choose the right one for your workflow.
1. Hyperstack
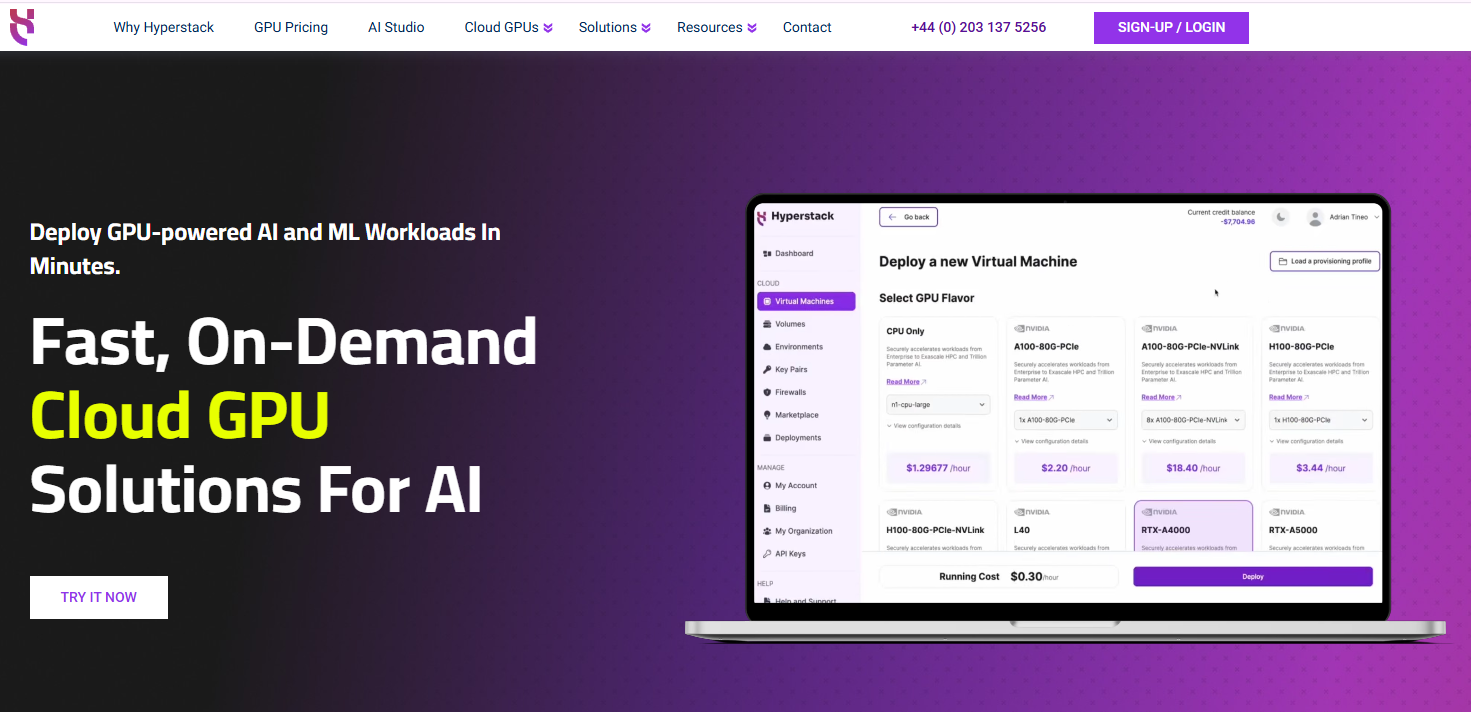
At Hyperstack, we focus on delivering high-performance infrastructure that deep learning workloads need. With high-speed networking, NVLink-enabled GPUs, fast storage and flexible deployment that scales seamlessly from single-GPU experiments to multi-GPU distributed training.
If you want to accelerate your deep learning workloads, you need more than just a powerful GPU. It is about how efficiently data flows between them, how quickly you can load and process large datasets and how reliably you can scale while managing cost. That’s where you choose Hyperstack cloud GPU provider for AI:
NVLink-Enabled NVIDIA H100 and A100 GPUs
You can choose our NVIDIA H100 and NVIDIA A100 GPUs with the NVIDIA NVLink, a high-bandwidth interconnect that allows GPUs to communicate at speeds
- This is crucial for large-scale training, where gradients and model parameters need to be shared rapidly across GPUs.
- NVLink reduces communication overhead and enables efficient data and model parallelism, ideal for training massive transformer models or multi-node clusters.
High-Speed Networking
Our high-speed networking for NVIDIA A100 and NVIDIA H100 GPUs reduces latency and increases throughput.
- This low-latency networking ensures multi-node training jobs sync quickly, minimising idle GPU time.
- It’s particularly beneficial for distributed deep learning frameworks like PyTorch DDP, Horovod or DeepSpeed, where inter-GPU communication speed directly affects training efficiency.
NVMe Block Storage for Fast Data Access
Our NVMe storage delivers high IOPS and low-latency access to training datasets.
- Deep learning models often rely on massive datasets from image libraries to text corpora and fast storage ensures data pipelines keep up with GPU processing speed.
Scalable Infrastructure with Flexible Management
Hyperstack offers one of the best tools for scalable GPU resources, allowing teams to scale seamlessly from single-GPU experiments to large distributed training setups.
- You can deploy GPU instances with one click, pause workloads when not in use with the Hibernation feature and resume them later, saving both time and cost.
- This flexibility is ideal for teams running experiments, iterative training or multi-stage model development.
Transparency and Cost Control
With per-minute billing and hibernation options, you pay only for active usage.
- Deep learning workloads often require long but intermittent training cycles. Our cloud GPU pricing model ensures you never overpay for idle resources.
- Teams can also reserve GPUs in advance at lower prices for large-scale or continuous projects.
GPUs for Deep Learning at Hyperstack
We offer high-performance NVIDIA GPUs optimised for deep learning:
- NVIDIA H100 PCIe and NVIDIA H100 SXM are ideal for large-scale transformer and LLM training.
- NVIDIA A100 PCIe is excellent for high-throughput model training and fine-tuning.
2. Runpod
Alongside Hyperstack, several most reliable GPU providers cater to different user needs—from rapid deployment and experimentation to globally distributed deep learning workloads. Runpod focuses on rapid deployment and developer agility. It’s popular among researchers and AI engineers who frequently iterate on model versions or fine-tune open models.
- Instant GPU Launch: Spin up GPU pods in seconds. In experimentation cycles, being able to quickly spin up a GPU, test and iterate speeds up productivity. This reduces friction for small-scale tests or debugging.
- Serverless Autoscaling: Automatically scales GPU resources based on workload demand.
- Container-First Design: Runpod integrates seamlessly with Docker images, simplifying reproducibility and environment setup.
3. Vast.ai
Vast.ai operates as a decentralised GPU marketplace, offering some of the lowest GPU prices through real-time bidding.
- A100 and V100 GPU Availability: You can access powerful GPUs for heavy training at competitive rates.
- Docker-Based Environment: They offerimple setup for machine learning frameworks like PyTorch and TensorFlow.
- Interruptible Pricing: Ideal for experiments or non-critical workloads where occasional pauses are acceptable.
- Bidding System: You can choose between fixed or auction-based pricing for cost flexibility.
4. Vultr
Vultr has become a major player in the GPU cloud space due to global reach with enterprise reliability. With data centres in over 30 regions, it’s ideal for distributed deep learning across continents.
- High-End GPUs (GH200, H100 and A100): Offers diverse GPU types for different workloads.
- Global Data Centres: Enables regional scalability and low-latency data access.
- Flexible Deployment Options: Choose on-demand or reserved GPU instances to optimise cost and availability.
- Robust Cloud Ecosystem: Integrates storage, networking and orchestration for full ML and deep learning pipelines.
5. OVHcloud

OVHcloud is known for its focus on compliance, security, and hybrid deployment. It’s an excellent choice for enterprises deploying deep learning workloads in regulated sectors such as finance, government, and healthcare.
- Dedicated GPU Nodes (A100, H100): Get consistent, high-throughput performance with no resource contention, which is ideal for large-scale deep learning.
- Hybrid Cloud Flexibility: You can easily scale between on-premise and cloud environments for AI workloads requiring data locality or compliance.
- High-Speed Networking: OVHcloud Connect Direct offers dedicated interconnections with guaranteed bandwidths up to 100 Gbps.
- Predictable Pricing: Transparent costs make it easier to plan for long-running training jobs and inference pipelines.
New on Hyperstack? Sign Up Today and Start Building Market-Ready AI.

FAQs
What is a Cloud GPU provider for deep learning?
A cloud GPU provider offers access to powerful GPU over the cloud for compute-intensive tasks like deep learning model training, fine-tuning, and inference. Many cloud providers’ GPU allow users to scale resources on demand or reserve them for long-term AI development.
Why do deep learning workloads need GPUs instead of CPUs?
Deep learning involves large-scale matrix operations and parallel computations that GPUs handle far more efficiently than CPUs. GPUs accelerate model training by performing thousands of simultaneous calculations, dramatically reducing training time for models like GPT, ResNet or Stable Diffusion.
What features should I look for in a cloud GPU provider?
When choosing a cloud GPU provider, consider:
- GPU types and performance (e.g. NVIDIA A100, H100, RTX A6000 and more)
- Networking and interconnects like NVLink
- Storage performance (NVMe for faster data loading)
- Scalability for distributed training
- Transparent pricing and billing flexibility
- Ease of deployment and management tools
Which NVIDIA GPUs are best for deep learning in 2025?
The top GPUs for deep learning in 2025 are NVIDIA H100 (SXM and PCIe) and NVIDIA A100, thanks to their high tensor core performance, NVLink support and scalability for large language models and diffusion-based workloads. For smaller or budget-friendly projects, GPUs like the NVIDIA RTX A6000 are also solid choices.
Which cloud platforms offer the fastest GPUs for AI workloads?
Hyperstack stands out by providing the latest NVIDIA GPUs — including NVIDIA H100, NVIDIA A100 and NVIDIA RTX A6000 — optimised for AI, rendering, and high-performance computing. With spot and reserved VM options, users can access ultra-fast compute at a fraction of the typical cloud cost.
How to choose a cloud GPU provider for deep learning applications?
When selecting a cloud GPU provider, consider factors like GPU type, cost-efficiency, scalability, latency, and ease of deployment. Hyperstack simplifies this process by offering on-demand, scalable GPU VMs with transparent pricing and real-time performance tracking. It’s designed for researchers, developers, and enterprises who need consistent, high-speed GPU performance without hidden costs.
How to migrate deep learning workloads to cloud GPU providers?
Migrating to a cloud GPU platform involves containerising your environment, ensuring data compatibility and selecting the right GPU configuration for your model. Hyperstack supports seamless workload migration with easy-to-use APIs, pre-configured AI environments, and integration with tools like Docker and Kubernetes. This means you can move from local or on-prem systems to Hyperstack’s GPU cloud with minimal setup and maximum performance.
What is the cost of a deep learning cloud GPU?
Hyperstack offers the NVIDIA H100 and NVIDIA A100 PCIe GPUs for deep learning, starting at $1.90 and $1.35, respectively. Check out our cloud GPU pricing here.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

