

TABLE OF CONTENTS
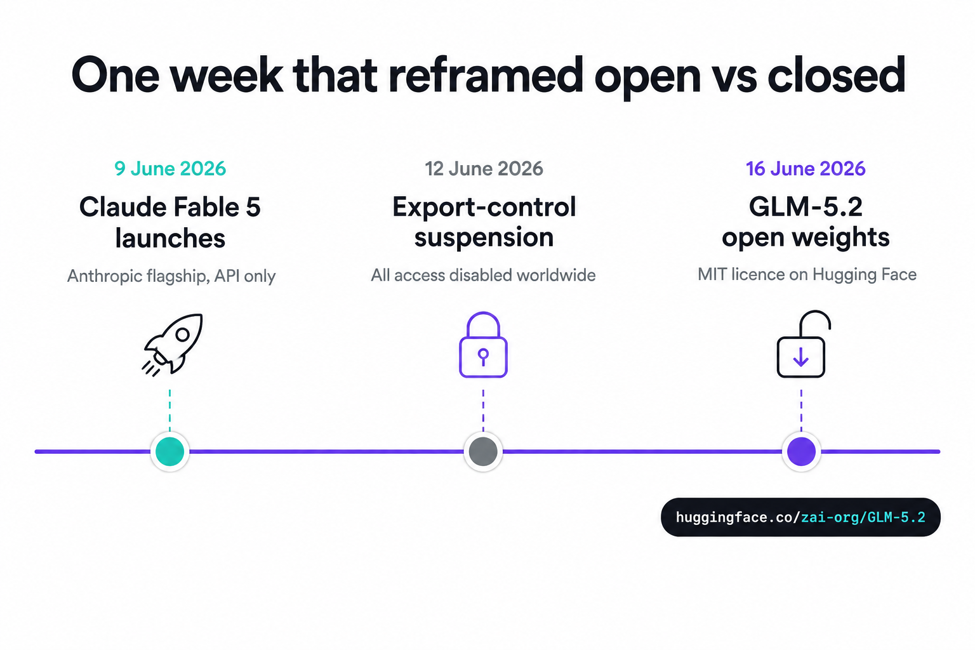
On 12 June 2026, every workflow built on Claude Fable 5 stopped working. No warning. No migration window. A US Commerce Department export-control directive required Anthropic to suspend the model globally. And that was that.
Anthropic had launched Fable 5 only three days earlier, to strong benchmark results. The day after the suspension, Z.ai shipped GLM-5.2; its MIT-licensed open weights hit Hugging Face on 16 June. No government directive can reach weights that are already distributed.
That is why this comparison is trending. GLM-5.2 is genuinely competitive: it posts the top AIME 2026 score, leads all open-weight models on agentic Elo, and sits within a few points of the best closed models on several coding benchmarks. More to the point, it is available right now. Understanding why that distinction exists structurally matters before you build anything critical on a closed API.
What is GLM-5.2
GLM-5.2 is a 744-billion-parameter Mixture-of-Experts model built by Z.ai, the international brand of the Beijing-based company Zhipu AI. Despite its total parameter count, only 40 billion parameters activate per forward pass. The model uses 256 routed experts plus 1 shared expert, with 8 routed experts active per token. That architecture, combined with DeepSeek Sparse Attention and a new technique called IndexShare that reuses a single attention indexer across every four sparse-attention layers, cuts per-token FLOPs at 1M context by 2.9x compared to naive sparse attention.
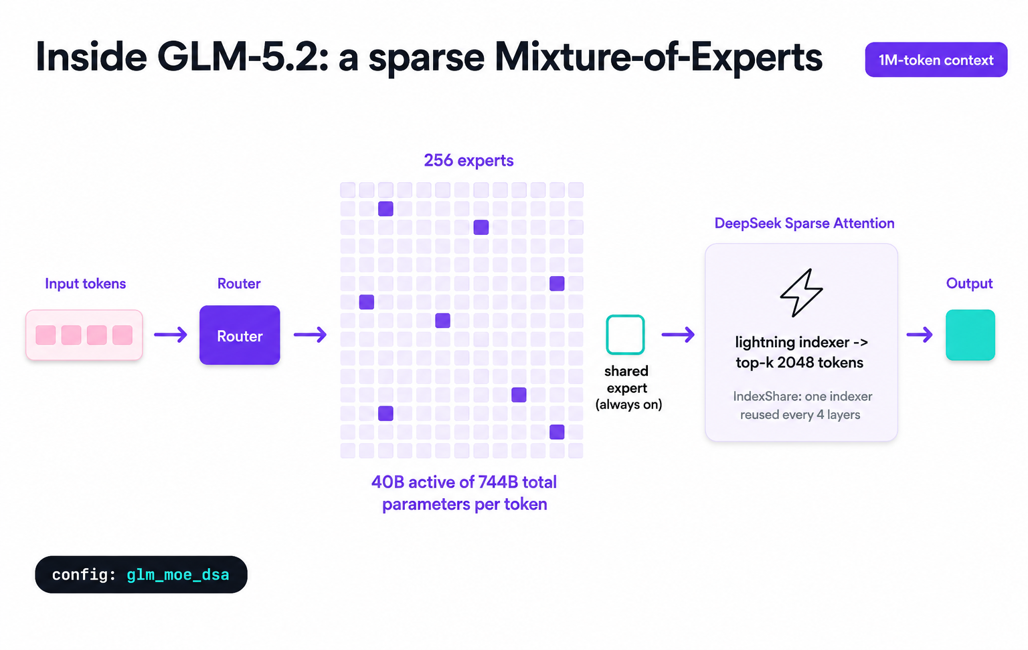
The context window is 1 million tokens, a 5x jump from GLM-5.1. Maximum output is 128K tokens per request. It ships with an MIT licence, weights on Hugging Face and ModelScope, and has an official vLLM deployment recipe for 8x NVIDIA H200.
What it is not: a drop-in API replacement for Fable 5. Self-hosting it is an infrastructure decision, not a tutorial step. More on that below.
What Fable 5 Is And Where It Went
Claude Fable 5 is Anthropic's most capable publicly released model, positioned above the Opus class in what Anthropic calls the Mythos tier. Fable 5 and Mythos 5 are the same underlying model. Fable 5 adds safety classifiers that cause cybersecurity, biology, chemistry, and distillation queries to fall back to Claude Opus 4.8. Anthropic reports that fallback occurs in fewer than 5% of sessions.
Anthropic discloses almost nothing about Fable 5's architecture: no parameter count, no layer structure, no training details. The context window is 1M tokens. Output is capped at 128K tokens per request. Pricing at launch was $10 per million input tokens and $50 per million output tokens.
On 12 June 2026, a US Commerce Department export-control directive required Anthropic to suspend both Fable 5 and Mythos 5 for all customers, including foreign-national Anthropic employees, because nationality cannot be screened in real time. The suspension is global. Both models carry mandatory 30-day data retention as Covered Models, with no zero-retention option. There is no self-hosting path: Fable 5 is API-only, and that API is currently unavailable.
Specs And Pricing At a Glance
| Attribute | GLM-5.2 | Claude Fable 5 |
|---|---|---|
| Maker | Z.ai (international brand of Zhipu AI) | Anthropic |
| Released | 13 June 2026 (open weights 16 June). | 9 June 2026 |
| Architecture | Mixture-of-Experts (open weights) | Undisclosed (closed) |
| Total parameters | 744B | Not disclosed |
| Active parameters | 40B per token | Not disclosed |
| Context window | 1M tokens | 1M tokens |
| Licence | MIT | Proprietary |
| Self-hosting | Yes | No (API only) |
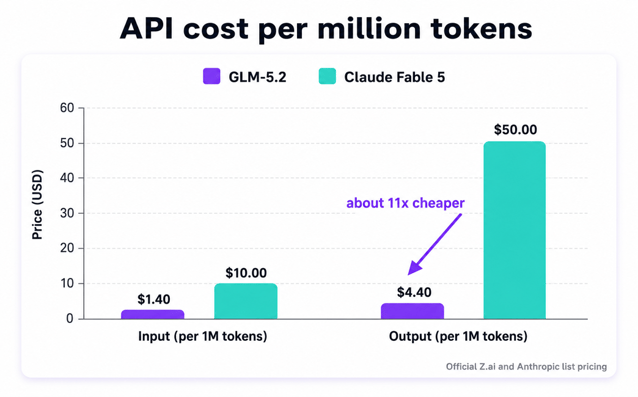
| Input price (per 1M tokens) | $1.40 | $10.00 |
| Output price (per 1M tokens) | $4.40 | $50.00 |
| Current availability | Available | Suspended since 12 June 2026 |
Official Z.ai and Anthropic list pricing. Output token gap is approximately 11x.
Benchmarks
All GLM-5.2 figures are from Z.ai's published scorecard. All Fable 5 figures are from Anthropic's 9 June 2026 benchmark table or Artificial Analysis. Where Fable 5 figures are starred in Anthropic's table, Fable 5 with its safeguards active performs closer to Opus 4.8 because of those fallbacks. Cells marked n/a indicate no comparable public figure was found.
On aggregate intelligence: Artificial Analysis's Intelligence Index (version 4.1, 17 June 2026) placed Fable 5 at 60, Opus 4.8 at 56, GPT-5.5 at 55, and GLM-5.2 at 51. GLM-5.2 is the top-scoring open-weights model on that index. Fable 5 remains the overall leader, though it is currently suspended, which makes Opus 4.8 the most capable accessible Anthropic model. The index is periodically re-versioned, so treat any absolute score as a dated snapshot.
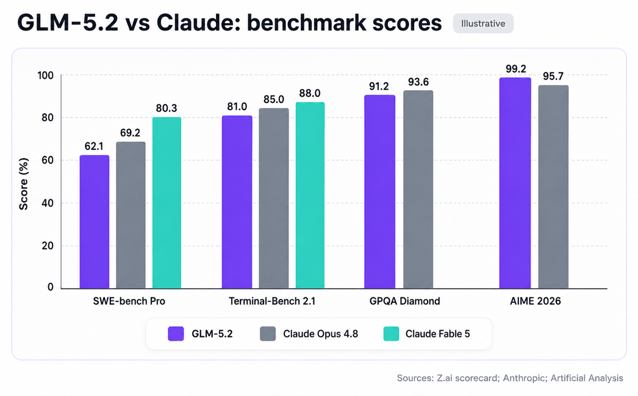
On coding: the picture is mixed. GLM-5.2 sits within one point of Opus 4.8 on FrontierSWE but trails significantly on repository-scale and ultra-long-horizon tasks.
| Coding benchmark | GLM-5.2 | Opus 4.8 | Fable 5 | GPT-5.5 |
|---|---|---|---|---|
| SWE-bench Pro | 62.1 | 69.2 | 80.3 | 58.6 |
| Terminal-Bench 2.1 | 81.0 | 85.0 | 88.0 | 84.0 |
| FrontierSWE (Dominance) | 74.4 | 75.1 | n/a | 72.6 |
| NL2Repo | 48.9 | 69.7 | n/a | 50.7 |
| SWE-Marathon | 13.0 | 26.0 | n/a | 12.0 |
| PostTrainBench | 34.3 | 37.2 | n/a | 28.4 |
*GLM-5.2 Terminal-Bench is 81.0 on the Terminus-2 harness. The 80.3 and 88.0 Fable 5 figures are from Anthropic's Fable 5/Mythos 5 scorecard.
On reasoning: GLM-5.2 is genuinely competitive and posts the top AIME 2026 score.
| Reasoning benchmark | GLM-5.2 | Opus 4.8 | Fable 5 | GPT-5.5 |
|---|---|---|---|---|
| GPQA Diamond | 91.2 | 93.6 | n/a | 93.6 |
| AIME 2026 | 99.2 | 95.7 | n/a | 98.3 |
| HMMT Feb 2026 | 92.5 | 96.7 | n/a | 96.7 |
| HLE (no tools) | 40.5 | 49.8* | n/a | 41.4* |
| HLE (with tools) | 54.7 | 57.9* | n/a | 52.2* |
GLM-5.2 figures are scored on HLE's text-only (non-multimodal) question subset for both rows; Opus 4.8 and GPT-5.5 figures marked * are on the full set. Not strictly like-for-like.
On agentic tasks: GLM-5.2 sits close to Opus on per-task scores but trails on harder tool-use benchmarks.
| Agentic benchmark | GLM-5.2 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| MCP-Atlas | 76.8 | 77.8 | 75.3 |
| Tool-Decathlon | 48.2 | 59.9 | 55.6 |
On the GDPval-AA v2 agentic Elo evaluation, GLM-5.2 scores 1524, the highest of any open-weights model and effectively tied with GPT-5.5. Claude Fable 5 ranks first overall.
On human preference, GLM-5.2 ranked first on Design Arena's single-turn HTML web-design evaluation in a June 2026 snapshot, ahead of Fable 5. On Arena.ai's WebDev/Code Arena it placed second overall behind Fable 5.
The pattern is consistent. GLM-5.2 leads on AIME 2026 and on human-preference coding arenas. It sits within one to two points of Opus on several agentic benchmarks. It trails clearly on repository-scale generation, ultra-long-horizon engineering, and aggregate intelligence. Fable 5 is the strongest single model on most individual benchmarks where it was measured, but it cannot currently be accessed.
The Hardware Reality of Self-Hosting GLM-5.2
This is where the conversation changes for infrastructure teams.
For a Mixture-of-Experts model, only 40 billion of GLM-5.2's parameters activate per forward pass. All 744 billion must reside in GPU memory. Expert routing cannot page weights in and out at inference without prohibitive latency. The rule of thumb: weights occupy approximately parameters x 1 byte in FP8, or x 2 bytes in BF16, plus headroom for the KV cache. At 1M context, the KV cache grows large enough to make an FP8 KV cache effectively mandatory.
| Precision | Approx. weights size | Example NVIDIA node |
|---|---|---|
| BF16 | ~1.51 TB | Multi-node (16x H200-class) |
| FP8 | ~756 GB | 8x H200 (141GB each) |
| AWQ INT4 | ~372 GB | 4x H200 |
| 2-bit GGUF (community) | ~238 GB | Smaller multi-GPU |
Weights only. KV-cache headroom required on top. At 1M context, FP8 KV cache is mandatory.

The FP8 checkpoint is approximately 756GB on Hugging Face, which fits on an 8x NVIDIA H200 SXM5 node. Each H200 carries 141GB of HBM3e, giving the node roughly 1.13TB of aggregate memory. An 8x NVIDIA H100-80GB node supplies only 640GB, which falls short of the FP8 weight requirement alone, so an H100 deployment requires closer to 16 cards. The clean single-node path is 8x H200, or NVIDIA Blackwell B200/B300 hardware, which adds higher memory capacity, improved FP8 throughput, and more NVLink bandwidth.
API pricing at Z.ai is $1.40 per million input tokens and $4.40 per million output tokens. On output tokens, GLM-5.2 is roughly 11x cheaper than Fable 5's list price. Self-hosting becomes economically interesting somewhere around 2 to 4.5 billion output tokens per month on an 8x H200 node. Below that volume, the API wins on unit economics. Above it, a dedicated cluster can be cheaper. Most teams self-host for data control, tail latency, or fine-tuning, not raw cost.
One further consideration: using Z.ai's hosted API may raise data-sovereignty and government-access concerns for sensitive workloads. China's National Intelligence Law is frequently cited in this context. The data-sovereignty advantage of open weights only fully materialises with self-hosting, in an environment where data does not leave your own infrastructure.
Where Hyperstack Secure Private Cloud Fits
For teams that need to self-host GLM-5.2 without sending data through a third-party API, the infrastructure problem is concrete: a dedicated cluster, single-tenant, with storage designed to handle the model's weight loading and KV-cache requirements at scale.
Our Secure Private Cloud is built for exactly this architecture. It is a dedicated, single-tenant deployment on segregated infrastructure, not a shared-tenancy environment. Data does not move through a public cloud hypervisor shared with other tenants. Access controls and governance are defined as part of the build, not toggled on in a settings panel.
For teams operating in Europe or under GDPR-aligned requirements, our deployments are designed to support GDPR-aligned operations by default. Sovereign build options are available for teams that need in-country or jurisdiction-specific infrastructure, with reduced exposure to the US CLOUD Act where applicable. That matters for non-US AI builders who have just watched one US-controlled API go dark overnight.
On networking, Secure Private Cloud supports RoCE (Ethernet) or InfiniBand fabrics depending on workload scale and performance requirements, with NVIDIA ConnectX-8 SuperNICs where GPU-to-GPU communication bandwidth is the constraint. On storage, we offer local NVMe scratch for high-throughput staging and checkpoint writes, Shared Storage Volumes for persistent datasets across restarts, and Secure Object Storage for durable model artefacts and backups. For distributed inference across multiple nodes, a parallel filesystem is available where shared high-throughput file access is required.
A single 8x NVIDIA H200 node runs one instance of GLM-5.2. Production serving is a different problem: redundancy, throughput across many concurrent requests, and headroom to host more than one model all turn that single node into a fleet. That is the scale Secure Private Cloud is built for. Minimum deployment size is 512 GPUs across 64 systems (eight GPUs per node), on a 12-month contract. This is not a VM you spin up for a test. It is infrastructure sized for teams running production-grade AI workloads at scale, with 24/7 operational coverage, severity-based incident response, and a named Technical Customer Success Manager who knows the stack.
The Dedicated Cloud deployment model goes further: Hyperstack manages the full platform stack, including scheduling and GPU optimisation, and your team consumes compute through our portal and APIs. For teams that want the performance characteristics of a dedicated cluster without running infrastructure operations internally, that is the relevant option.
Ready to Have That Conversation?
If you are building AI workflows and want to understand what sovereign infrastructure actually means for your environment, we are happy to have a straight conversation about it. A quick, genuine discussion about your stack, your compliance posture and what a move would involve.

FAQs
What is GLM-5.2?
GLM-5.2 is an open-weight Mixture of Experts language model from Z.ai featuring one million token context.
What happened to Claude Fable 5?
Claude Fable 5 was globally suspended following a US export control directive, making the API unavailable worldwide.
Is GLM-5.2 better than Claude Fable 5?
Claude Fable 5 outperforms GLM-5.2 overall, but GLM-5.2 remains highly competitive and currently accessible.
Can GLM-5.2 be self-hosted?
Yes, GLM-5.2 supports self-hosting, although running it requires significant GPU resources and specialised infrastructure.
Why are open-weight AI models important?
Open-weight models provide greater control, availability, sovereignty, and flexibility than proprietary API-only alternatives.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

