
.png)
TABLE OF CONTENTS
Building effective agentic systems requires more than just connecting an LLM to multiple tools. Without the right foundation, tool calls can quickly inflate context windows, drive up costs, and introduce hallucinations. Fine-tuning a model specifically for tool use is the key to unlocking reliable, efficient agentic workflows.
In this comprehensive guide, we are going to target a business use case of a support agent that can assist users with various tasks by using a predefined set of tools. The agent will be able to handle requests made by users, such as checking the status of a fine-tuning job, looking up documentation, creating support tickets, and more.
We'll begin by creating a unique Chain-of-Thought dataset and uploading it to Hyperstack AI Studio. Then, we'll fine-tune a model using this dataset. By the end of this process, you'll learn how to build a specialised model capable of reliably handling agentic workflows, enabling smarter and more efficient AI automation.
Why Hyperstack AI Studio is the Right Choice for Fine-Tuning Agentic Models
Choosing the engine that powers your AI architecture is one of the most critical decisions you'll make. It directly impacts your operational costs, the quality of your user interactions, and your ability to scale in the future. While there are many options available, Hyperstack AI Studio stands out as an ideal choice for this project for several key reasons.
1. Precision Tool Calling for Lower Costs
Every unnecessary token in a tool call adds up. When an unfine-tuned model struggles to choose the correct tool or formats outputs inconsistently, the result is bloated context and higher inference costs. With Hyperstack, you can fine-tune a model on your exact toolset, teaching it to consistently produce minimal, accurate JSON calls. This dramatically cuts context usage, reducing overhead while keeping workflows lean.
2. Structured Outputs That Just Work
Hallucinations in agentic workflows often come from the model "guessing" parameters or returning malformed outputs. Hyperstack fine-tuning transforms this guesswork into reliable behavior. By training on your own tool-calling examples, the model learns the correct schema and parameter usage, producing structured outputs that downstream systems can consume without constant error handling or validation.
3. Robust Evaluation to Eliminate Hallucinations
When multiple tools are in play, reliability is non-negotiable. Hyperstack’s Custom Evaluations let you test exactly what matters: Did the model call the right tool? Did it pass the correct parameters? This fine-grained evaluation ensures your fine-tuned model isn’t just "better" in a vague sense, it’s measurably more accurate and production-ready, even in complex multi-tool workflows.
4. API Compatibility for Drop-In Improvements
Fine-tuned models shouldn’t require rebuilding your stack. Hyperstack’s OpenAI-compatible API means your agentic system can immediately swap in the fine-tuned model without changing core logic. Just update the base_url and api_key, and your workflow gains the benefits of structured, cost-efficient tool calling no rewrites required.
5. Scalability for Real-World Agentic Workflows
Once fine-tuned, your agent must handle real-world traffic patterns: surges in requests, parallel tool calls, and low-latency responses. Hyperstack’s scalable inference infrastructure ensures your agent remains performant under load, whether you’re orchestrating a handful of calls per hour or thousands per second across multiple tools.
Understanding Our Chain-of-Thought (CoT) Agentic Dataset
To finetune an LLM for agentic tasks, we need a dataset that teaches the model not just to respond, but to reason about how to respond. This is where our Chain-of-Thought (CoT) dataset comes into play.
The Required JSONL Format
Many finetuning API providers like Hyperstack or OpenAI focus on a structured jsonl format dataset. The JSONL file must contain one JSON object per line, where each object represents a conversation or interaction. Here's an example of the expected format:
...
{"messages": [{"role": "user", "content": "What's the capital of Australia?"}, {"role": "assistant", "The capital of Australia is Canberra."}]}
{"messages": [{"role": "user", "content": "How do I reset my password?"}, {"role": "assistant", "To reset your password, go to the login page and click on 'Forgot Password'."}]}
...
Each line in the JSONL file must be a valid JSON object containing:
- messages: An array of message objects
- Each message object must have:
role: Either "system", "user", or "assistant"content: The text content of the message
Make sure your JSONL file has one complete JSON object per line, uses proper JSON formatting, contains the required fields for each message, has no trailing commas, and uses UTF-8 encoding.
Reasoning Using <thinking> Block
This is the same structure we need for our agentic dataset, but with an additional focus on the model's reasoning process. Each interaction will include a "thinking" step where the model explains its reasoning before producing the final tool call.
To mimic a real-world scenario, our dataset will include various user requests that require different tools, similar to how a support agent would operate. Each entry will consist of a user message and an assistant message that includes both the reasoning process and the final tool call in JSON format.
For example, consider this one simple interaction:
{
"messages": [
{
"role": "user",
"content": "Hey, can you tell me what's happening with my fine-tuning job ft-a9b8c7d6?"
},
{
"role": "assistant",
"content": "<thinking>The user is asking for the status of a specific fine-tuning job. They have provided the job ID 'ft-a9b8c7d6' directly in the prompt. The correct tool for this is check_finetune_job_status. I will extract the job ID and use it as the parameter for the tool call.</thinking>\n{\"tool_name\": \"check_finetune_job_status\", \"parameters\": {\"job_id\": \"ft-a9b8c7d6\"}}"
}
]
}
You can download this dataset from Kaggle.
Each entry consists of:
- User Message: The user's request which ask for a specific action.
- Assistant Message: The assistant message contains two parts:
- Tool Call: The final JSON object that will be sent to the tool.
- The
<thinking>Block: This is the model's internal thought process. We explicitly show it the reasoning process: identify the user's intent, recognize the key entities (like ajob_id), and select the appropriate tool from a predefined list. Training on this thought process makes the model's behavior more robust and interpretable.
So we are basically applying two layers of structure, one is giving the model a thinking process to follow, and the other is the correct JSON format for the tool call.
Dataset Scenarios and Tools
Our dataset covers several scenarios relevant to a support agent, including:

- Checking Job Status:
check_finetune_job_statuswhen the user asks about a specific fine-tuning job. - Looking up Documentation:
lookup_documentationwhen the user needs help with a specific feature or API. - Creating a Support Ticket:
create_support_ticketwhen the user reports an issue that needs human intervention. - Getting Model Info:
get_model_deployment_infowhen the user wants details about a deployed model. - Handling Out-of-Scope Requests:
no_tool_availablewhen the user's request doesn't match any available tools.
And couple more but in a production dataset, you would want to cover all the tools and scenarios your agent might encounter.
Splitting Data: Training vs. Evaluation Sets
For any kind of finetuning job, we need two datasets:
- Training Set: This is the main dataset the model will learn from. It should contain a diverse set of examples covering all the tools and scenarios you want the agent to handle.
- Evaluation Set: A smaller, separate dataset used to evaluate the model's performance during and after training. This set should also cover all tools and scenarios but should not overlap with the training set.
A good ratio for machine learning training is to split our data into 70% training and 30% evaluation. So if we have 150 examples, we can use 105 for training and 45 for evaluation.
Now that we have our dataset ready, we can now start interacting with Hyperstack AI Studio.
Part 1: Uploading Our Agentic Dataset to Hyperstack AI Studio
With our train.jsonl and eval.jsonl files ready, the first step is to get them into the Hyperstack AI Studio platform. In Hyperstack's terminology, training data is managed as "Logs." This process can be done in two ways: through the visual web interface, which is great for getting started quickly, or programmatically via the API, which is ideal for building automated and reproducible MLOps pipelines.
There are two ways to upload your dataset to Hyperstack AI Studio:
- Using the AI Studio UI: This is the simplest method, perfect for one-off uploads or if you prefer a visual workflow.
- Using the Hyperstack API: This method is more complex but allows for automation and integration into CI/CD pipelines.
Let's look at both methods.
The UI Approach for Quick Uploads
For one-off experiments or if you prefer a visual workflow, the AI Studio UI is the most direct method.
- First, navigate to the data section from the main menu on the left side of the AI Studio dashboard. This is the central hub for all your training data.
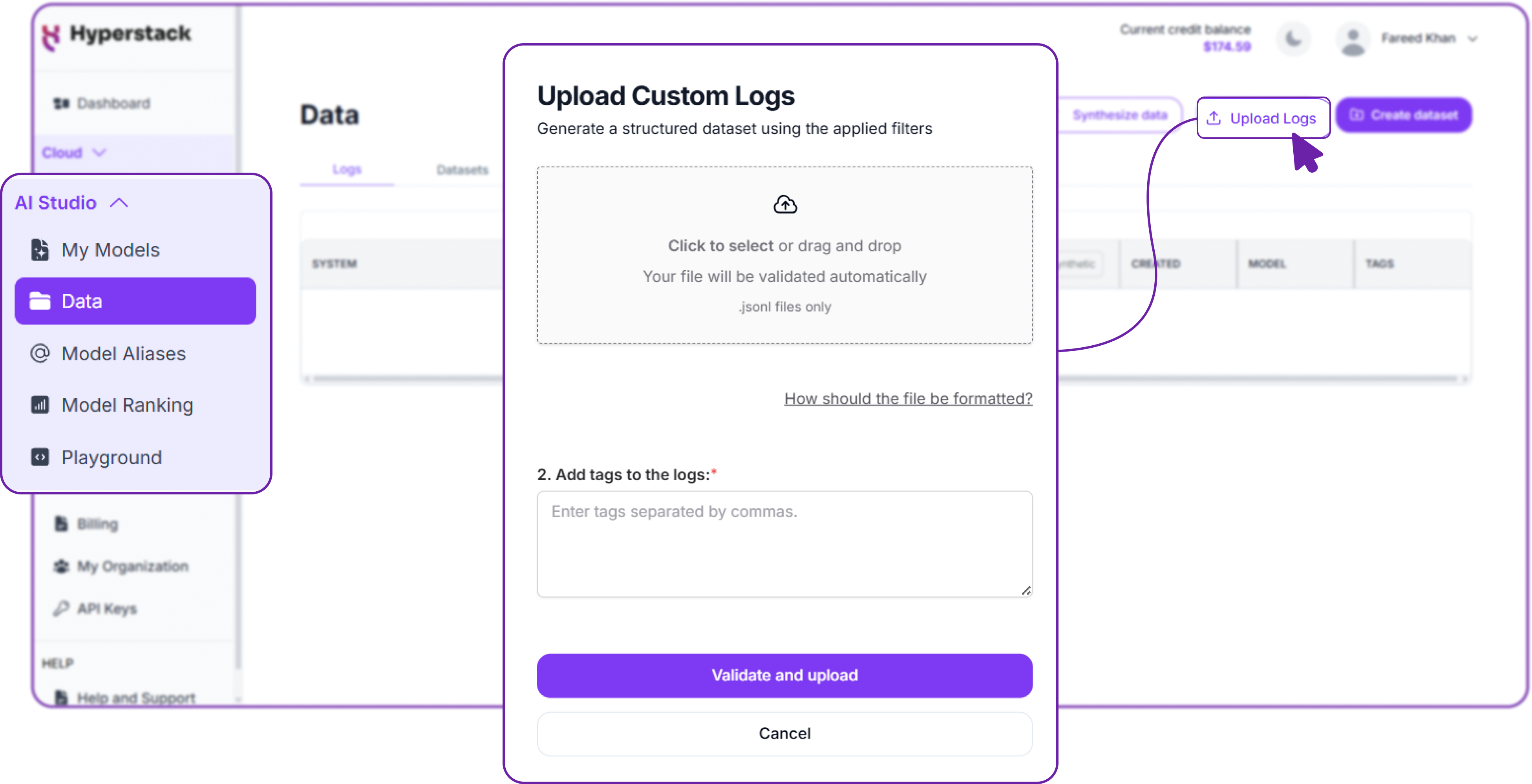
- Click the Upload Logs button located in the top-right corner.
- In the upload dialog:
- Drag and drop your
train.jsonlfile directly into the window, or - Click to browse and select the file from your computer.
- Drag and drop your
Hyperstack backend will automatically validate that your file is in the correct JSONL format. If there are any formatting issues, it will provide immediate feedback so you can correct them before proceeding.
You must also add tags to your upload to help organise and identify your datasets later. Tags are especially useful when you have multiple datasets for different projects or versions.
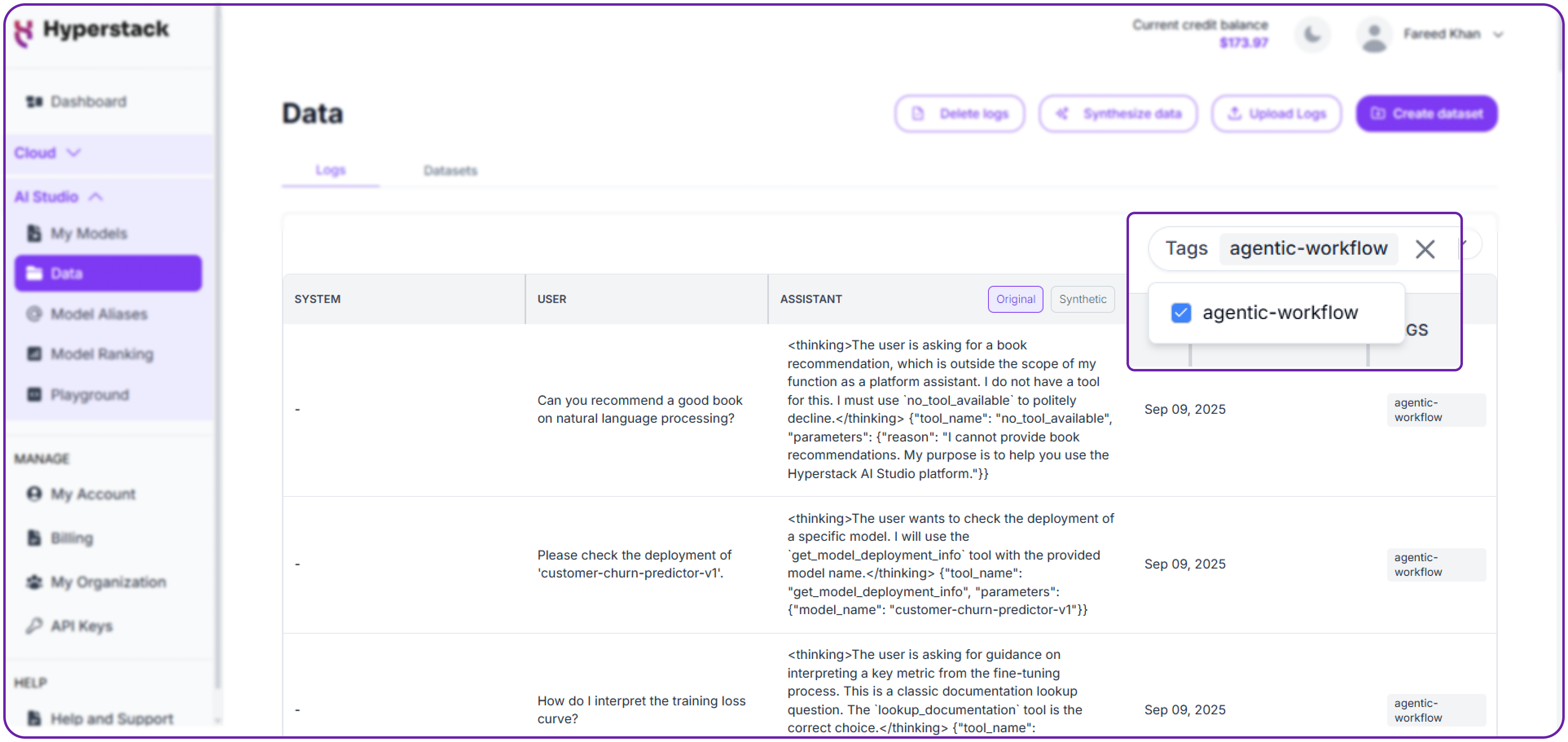
Our logs will start appearing in the table below the upload area. We can now select the tag, we use to upload our dataset, in our case we use the agentic-workflow and then those specific logs will be appearing that are related to that tag, so this way multiple dataset are easily manageable.
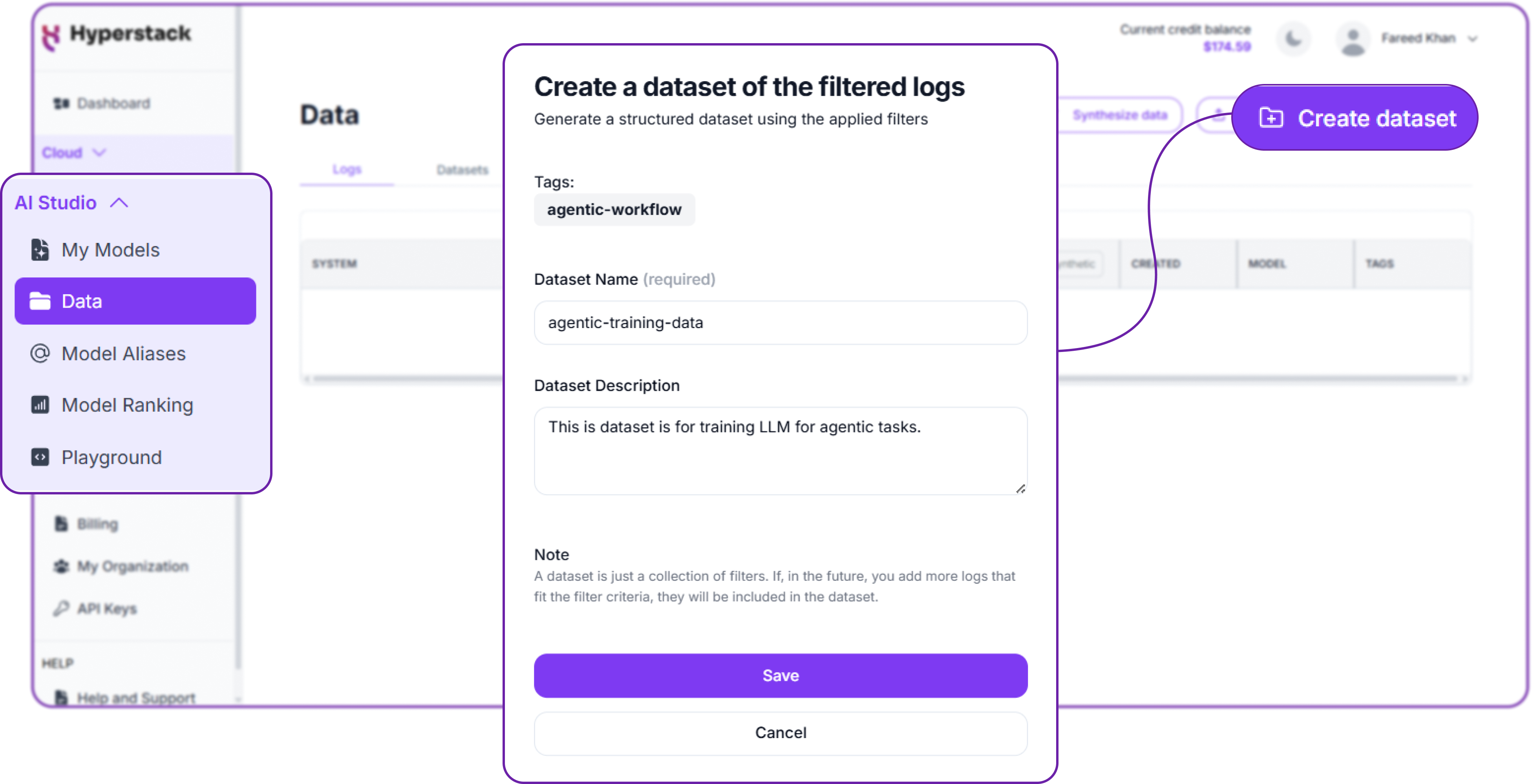
You can simply create dataset using the logs of that specific tag, and fill in the required details like dataset name and its description, and then create the dataset.
You can view your newly created dataset under the Datasets tab in the same Data section. Here, you can see all your datasets, their sizes, and when they were created.
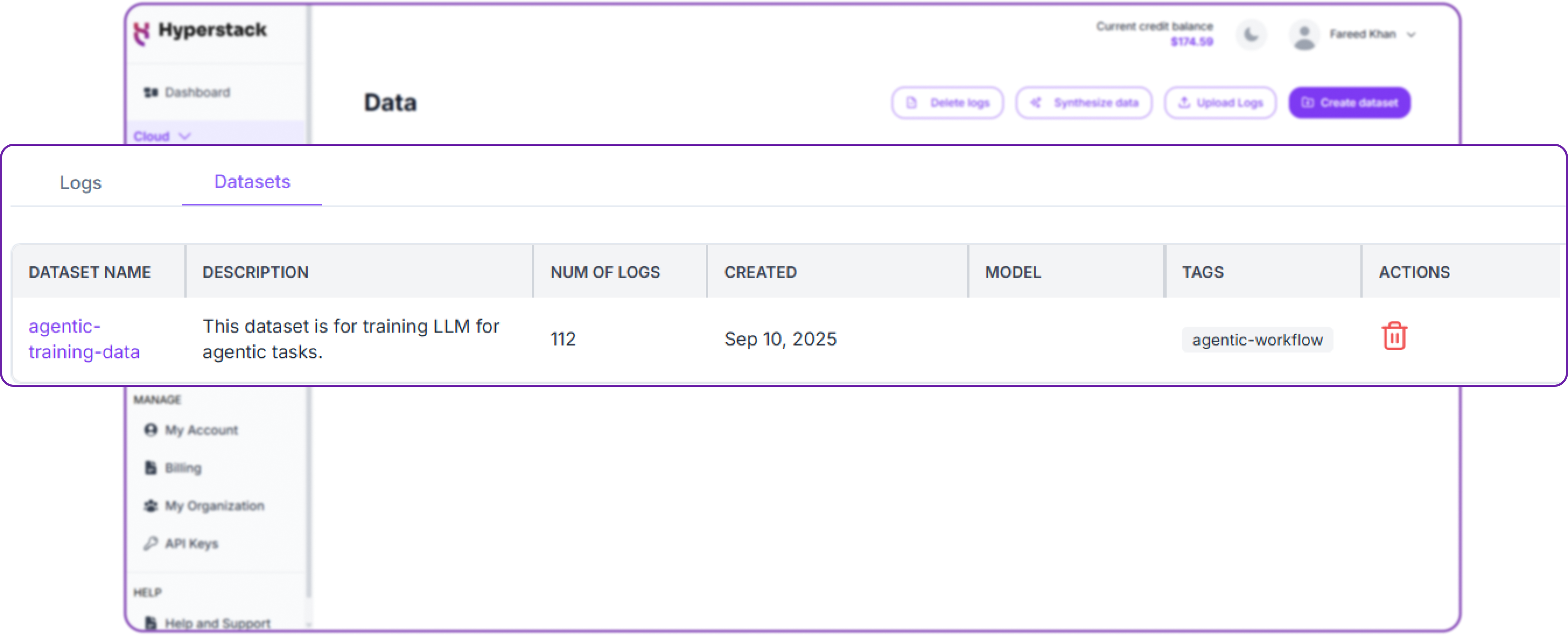
The number of logs represent number of entries in your jsonl file.
The API Approach for Automated Workflows
For more advanced use cases, like integrating dataset uploads into a CI/CD pipeline, the Hyperstack API provides full programmatic control. Uploading a file via the API is a secure three-step process:
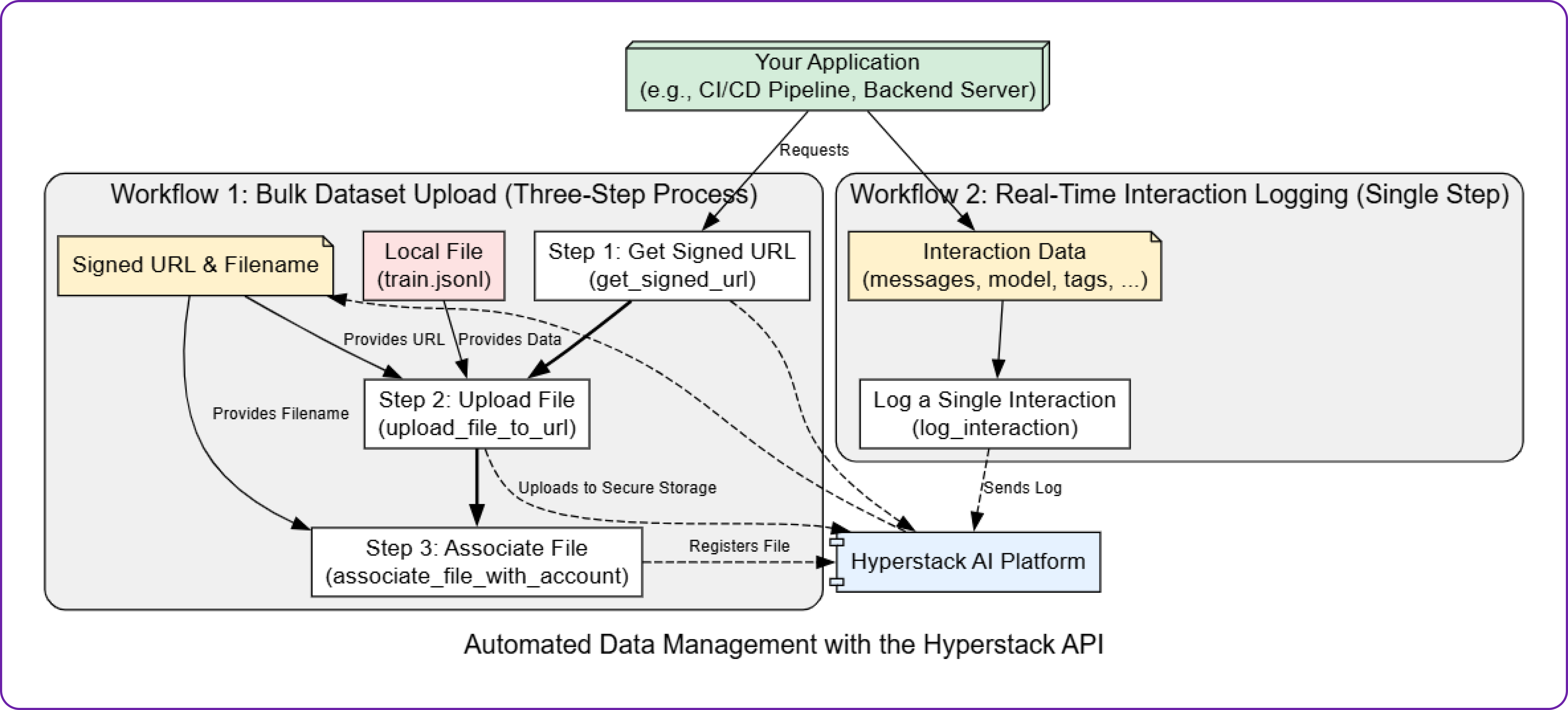
- Get a Signed URL: First, your application requests a temporary, secure upload URL from Hyperstack.
- Upload the File: Your application then uses this specific URL to upload the
.jsonlfile. - Associate the File: Finally, you make a call back to the Hyperstack API to register the uploaded file and apply tags.
Let's build a Python script to perform these steps, breaking it down one function at a time.
First, let's set up our project. Create a requirements.txt file with the necessary library.
# requirements.txt
python-dotenv
requests
Next, create a .env file to store your Hyperstack API key securely. You can get your API key from their Hyperstack AI Studio Console.
# .env
HYPERSTACK_API_KEY="YOUR_HYPERSTACK_API_KEY"
Let's import the required libraries and load our API key from the .env file.
import os
from dotenv import load_dotenv
import requests
from datetime import datetime
load_dotenv() # Load environment variables from .env file
API_KEY = os.getenv("HYPERSTACK_API_KEY")
Step 1: Requesting a Secure Upload URL
Our first task is to ask the Hyperstack API for a secure, temporary location to upload our file. This is a standard security practice that prevents unauthorised uploads. The API will generate a unique, pre-signed URL that is valid for a short period.
Here is the Python function to handle this request:
def get_signed_url(api_key: str) -> dict:
"""
Step 1: Request a secure, pre-signed URL from Hyperstack for file upload.
This URL is temporary and unique to this upload session.
"""
headers = {"api_key": api_key}
url = "https://console.hyperstack.cloud/ai/api/v1/data/signed-url"
print("Requesting a signed URL for upload...")
response = requests.get(url, headers=headers)
response.raise_for_status() # This will raise an error for bad responses
print("Successfully received signed URL.")
return response.json()
This function, get_signed_url, constructs the necessary headers with our API key and makes a GET request to the /data/signed-url endpoint. If successful, it parses the JSON response and returns it.
Let's see it in action and inspect its output:
# Assuming API_KEY is loaded from .env
url_data = get_signed_url(API_KEY)
print(url_data)
The output will be a JSON object that looks like this:
{
"filename": "b24f7b35-ab20-4a62-8f34-4bb6550a9f58",
"signedUrl": "https://ca1-dev.s3.nexgencloud.io/prod-tailor-logs-ca1/b24f7b34-ab20-4a62-8f35-4bb6550a9f58?X-Amz-Algorithm=AWS4-HMAC-SHA256&..."
}
The response gives us two critical pieces of information:
filename: A unique UUID that Hyperstack generated to track our file internally. We will need this in Step 3.signedUrl: The temporary, secure URL where we will upload our file.
Step 2: Uploading the File
Now that we have our signedUrl, we can upload our local .jsonl file. This function will read the file in binary mode and send its contents in an HTTP PUT request to the URL we just received.
def upload_file_to_url(signed_url: str, file_path: str) -> bool:
"""
Step 2: Upload the local file's binary content directly to the provided pre-signed URL.
"""
print(f"Uploading file '{file_path}' to the secure URL...")
try:
with open(file_path, 'rb') as f:
# The content-type must be 'application/octet-stream' for raw file data
response = requests.put(signed_url, data=f, headers={"Content-Type": "application/octet-stream"})
response.raise_for_status()
print("File uploaded successfully to storage.")
return True
except FileNotFoundError:
print(f"Error: File not found at path: {file_path}")
return False
This function, upload_file_to_url, takes the signedUrl from the previous step and the path to our local file. It's crucial that the Content-Type header is set to application/octet-stream, as we are sending raw file data.
A successful upload will not return any JSON body, but rather an HTTP 200 OK status code. Our function will return True to indicate success.
# Using the signedUrl from the previous step's output
signed_url = url_data.get("signedUrl")
success = upload_file_to_url(signed_url, 'train.jsonl')
print(f"Upload successful: {success}")
The output will simply be:
Uploading file 'train.jsonl' to the secure URL...
File uploaded successfully to storage.
Upload successful: True
Step 3: Registering the File and Adding Tags
Our file is now in Hyperstack's storage, but our account doesn't know about it yet. This final step is to make an API call to formally register the file, associate it with our account, and apply the organisational tags we need.
def associate_file_with_account(api_key: str, filename: str, tags: list) -> bool:
"""
Step 3: Register the uploaded file with your Hyperstack account and apply tags
to make it discoverable for fine-tuning jobs.
"""
headers = {"api_key": api_key, "Content-Type": "application/json"}
url = "https://console.hyperstack.cloud/ai/api/v1/logs/custom-upload"
payload = {
"custom_logs_filename": filename,
"save_logs_with_tags": tags
}
print(f"Associating file '{filename}' with tags {tags} in your account...")
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
print("File successfully associated and tagged.")
print(response.json()) # Print the success message from the API
return True
This function, associate_file_with_account, sends a POST request to the /logs/custom-upload endpoint. Its payload contains the custom_logs_filename (the unique UUID from Step 1) and the list of tags we want to apply.
Let's call it with the filename from Step 1 and our desired tags:
# Using the filename from the first step's output
server_filename = url_data.get("filename")
tags = ['agent-tool-calling-v1-train', 'api-upload']
associate_file_with_account(API_KEY, server_filename, tags)
A successful call will produce the following output:
Associating file 'b24f7b35-ab20-4a62-8f34-4bb6550a9f58' with tags ['agent-tool-calling-v1-train', 'api-upload'] in your account...
File successfully associated and tagged.
{'message': 'Successfully uploaded custom logs', 'status': 'success'}
This confirms that our train.jsonl file is now available in our Logs & Datasets page in the UI.
Step 4: Logging Individual Interactions with the Save Data API
Once our dataset is uploaded and registered, you may want to log individual interactions in real time. Hyperstack provides a Save Data API that allows you to send interaction data directly from your application.
This is useful for capturing new conversations, feedback, or experiment results without needing to create a full dataset upload each time.
The endpoint for logging interactions is:
POST https://console.hyperstack.cloud/ai/api/v1/data/logs
Before sending a request, make sure you have the following:
model: The name of the model used (e.g.,llama-3.1-70B-instruct, or your custom model name).messages: An array of message objects, each containing arole(system,user, orassistant) andcontent.creation_time: A UTC timestamp indicating when the interaction occurred. It must be in ISO 8601 format, e.g.,"2025-06-05T15:50:00Z".
You can also include optional fields such as kwargs, tags, and usage to capture additional context.
We can create a Python function on top of it to log a single interaction using requests:
def log_interaction(api_key: str, model: str, messages: list, tags: list = None, usage: dict = None):
"""
Logs a single interaction to Hyperstack's Save Data API.
"""
url = "https://console.hyperstack.cloud/ai/api/v1/data/logs"
payload = {
"messages": messages,
"model": model,
"creation_time": datetime.utcnow().isoformat() + "Z",
"kwargs": {},
"tags": tags or [],
"usage": usage or {}
}
headers = {"api_key": api_key, "Content-Type": "application/json"}
print(f"Logging interaction for model '{model}'...")
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
print("Interaction successfully logged.")
print(response.json())
return True
Now, we can simply call this function with our interaction data:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's the weather today?"}
]
tags = ["example", "weather"]
usage = {"prompt_tokens": 10, "completion_tokens": 20, "total_tokens": 30}
log_interaction(API_KEY, model="llama-3.1-70B-instruct", messages=messages, tags=tags, usage=usage)
If successful, the API will return:
{
"message": "Data successfully saved to database",
"status": "success"
}
This confirms that the interaction is now stored in Hyperstack and can be viewed in the Logs & Datasets page alongside your other datasets.
By using this API, you can continuously collect interaction data programmatically, making your datasets dynamic and always up-to-date.
Part 2: Fine-Tuning Our Agentic Model on Hyperstack AI Studio
Now that we have our dataset uploaded and registered in Hyperstack AI Studio, we can proceed to fine-tune our model. Fine-tuning is the process of taking a pre-trained model and training it further on a specific dataset to specialise it for a particular task as in our case, tool use for an AI agent.
Just like with uploading datasets, Hyperstack provides two ways to create a fine-tuning job, either through the visual web interface or programmatically via the API. We will be looking at both methods in parallel.
Creating a Fine-Tuning Job via the UI
First, go to My models section from the main menu on the left side of the AI Studio dashboard, and then click on the Fine-tuning tab.
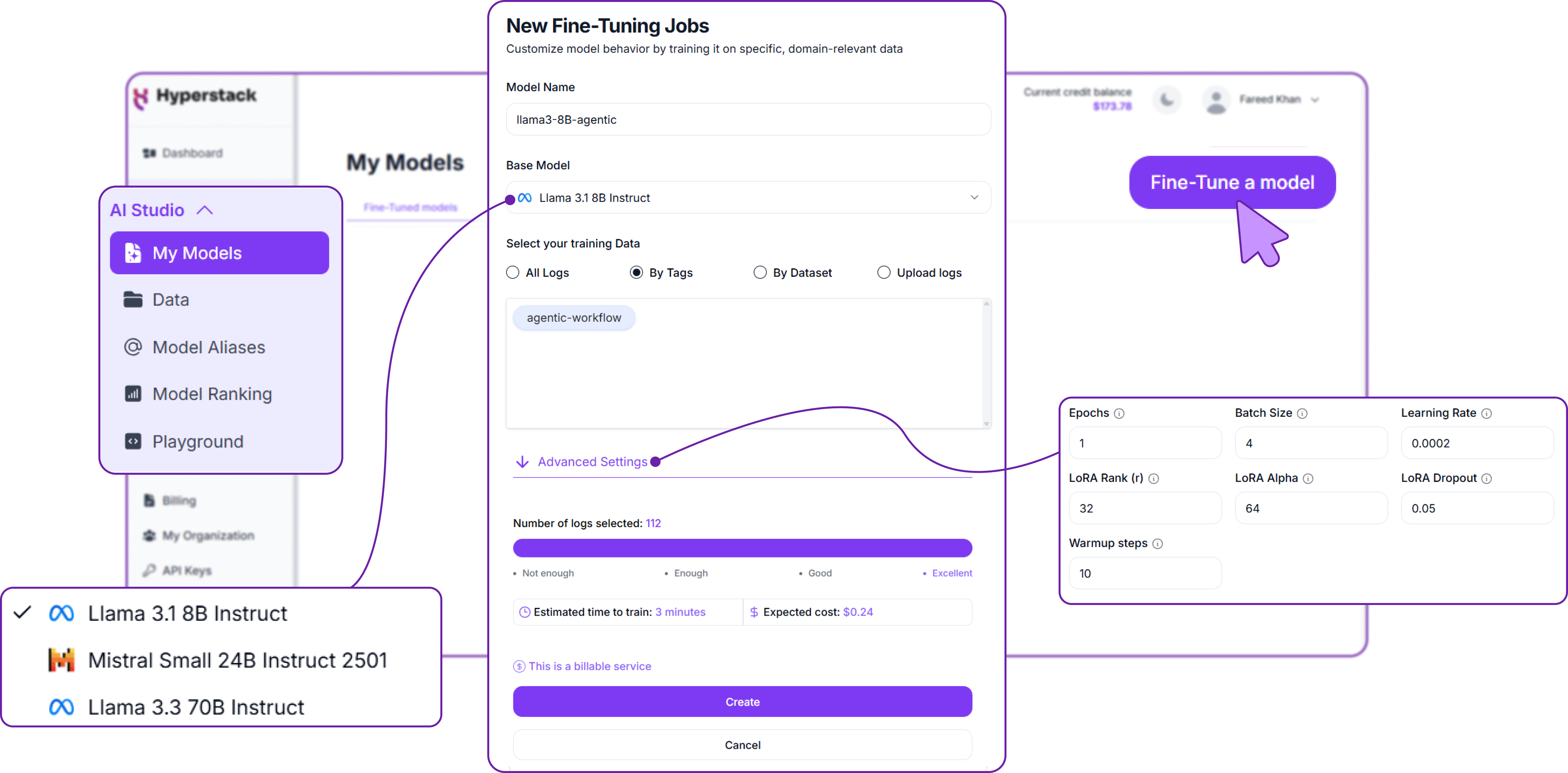
You will be asked several details to create a fine-tuning job.
- Model Name: Give your fine-tuned model a unique name. This is how you'll reference it later when making API calls.
- Base Model: Select the base model you want to fine-tune. For our agentic workflow, we recommend starting with a smaller model like
Llama 3.1 8Bfor cost efficiency. But you can choose any model that fits your needs. - Dataset: Choose the dataset you uploaded earlier. Make sure to select the correct dataset that contains your Chain-of-Thought examples.
- Additional Settings: Configure any additional settings for your fine-tuning job, such as learning rate, batch size, and number of epochs. These settings can significantly impact the performance of your fine-tuned model.
The interface displays the total number of logs in the dataset, helping you determine if the dataset is sufficient for training. It also provides an estimate of the expected cost and time required to complete the fine-tuning job.
This is one of the advantages of using Hyperstack, it gives you a clear estimate of the cost and time before you start the job, so you can plan accordingly.
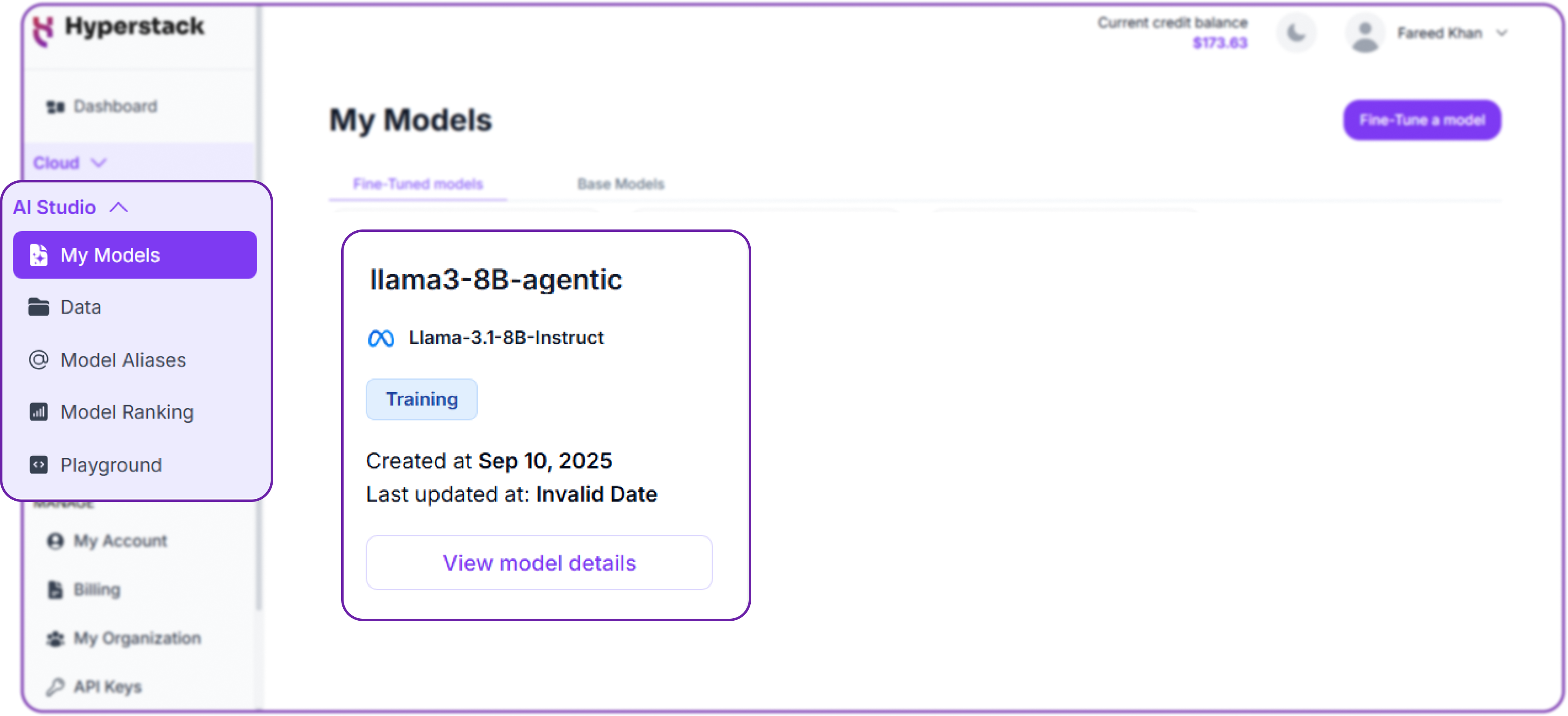
Once you click on create fine-tuning job, Hyperstack will start the training process. You can monitor the progress of your fine-tuning job in real-time from the same Fine-tuning tab.
This approach requires no code at all, making it accessible to non-developers and allowing for quick experimentation. Now let's look at how to do the same thing programmatically using the Hyperstack API.
Creating a Fine-Tuning Job via the API
Hyperstack Fine-Tuning API allows full control over the job creation, training parameters, and dataset selection. Let’s walk through the process step by step.
Before creating a job, we need to define all the parameters. This includes your base model, unique model name, dataset, training hyperparameters, and optional LoRA settings for adapter-based training. These are basically all the same parameters you would set in the UI.
# Fine-tuning job configuration
fine_tune_config = {
"base_model": "llama-3.1-8B-instruct", # Base model to fine-tune
"model_name": "agentic-llama-3.1-8B-v1", # Unique name for your fine-tuned model
"batch_size": 4, # Number of samples per batch
"epoch": 3, # Number of training epochs
"learning_rate": 0.0004, # Learning rate for optimizer
"tags": ["agentic-workflow", "tool-calling-v1"], # Tags to filter training data
"custom_logs_filename": "b24f7b35-ab20-4a62-8f34-4bb6550a9f58", # File uploaded earlier
"save_logs_with_tags": True,
"lora_r": 32,
"lora_alpha": 16,
"lora_dropout": 0.05
}
If you already created a dataset in Hyperstack, you can also use the custom_dataset parameter instead of custom_logs_filename.
We can now make a POST request to the Hyperstack Fine-Tuning API to start training.
def create_fine_tuning_job(api_key: str, config: dict) -> dict:
"""
Creates a fine-tuning job for a specified base model on Hyperstack.
"""
url = "https://console.hyperstack.cloud/ai/api/v1/finetuning/jobs"
headers = {"api_key": api_key, "Content-Type": "application/json"}
print(f"Creating fine-tuning job for model '{config['model_name']}'...")
response = requests.post(url, headers=headers, json=config)
response.raise_for_status() # Raise error if request fails
print("Fine-tuning job successfully created.")
return response.json()
Let's call this function with our configuration to start the fine-tuning job:
job_response = create_fine_tuning_job(API_KEY, fine_tune_config)
print(job_response)
A successful response will look like this:
{
"message": "Reservation starting",
"status": "success"
}
This confirms that your fine-tuning job is now queued and will start training according to the parameters you set.
Monitoring Training Progress and Metrics
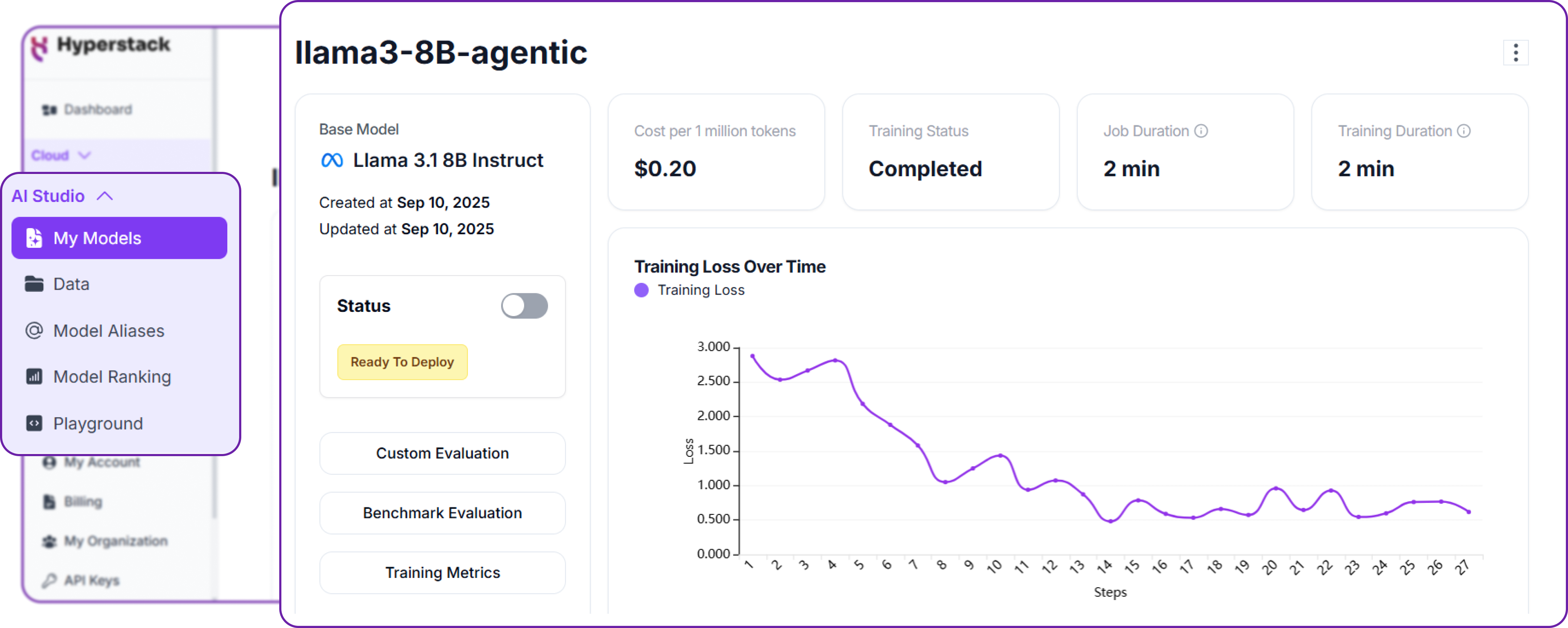
Once the training is completed, you can monitor the basic status info of your fine-tuning job through their UI. For a detailed view of the training metrics like loss and accuracy, you can click on the Training Metrics button.
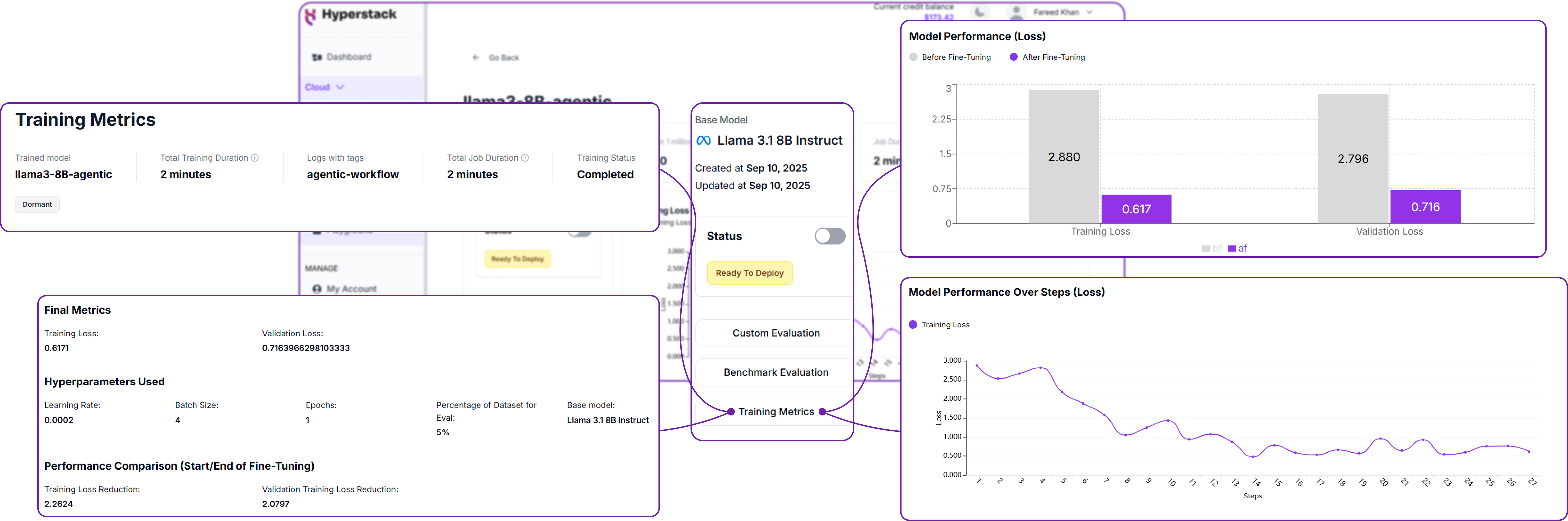
Hyperstack provides real-time graphs of training loss and evaluation accuracy, allowing you to see how well your model is learning over time. This is crucial for diagnosing issues like overfitting or underfitting.
Let's understand what each of these metrics means.

First component shows some basic info about the fine-tuning job, like how much time it took, the status, and the your trained model name.

Second component provides a high-level overview of the training parameters we used for training the model, like the base model, batch size, learning rate, and number of epochs.
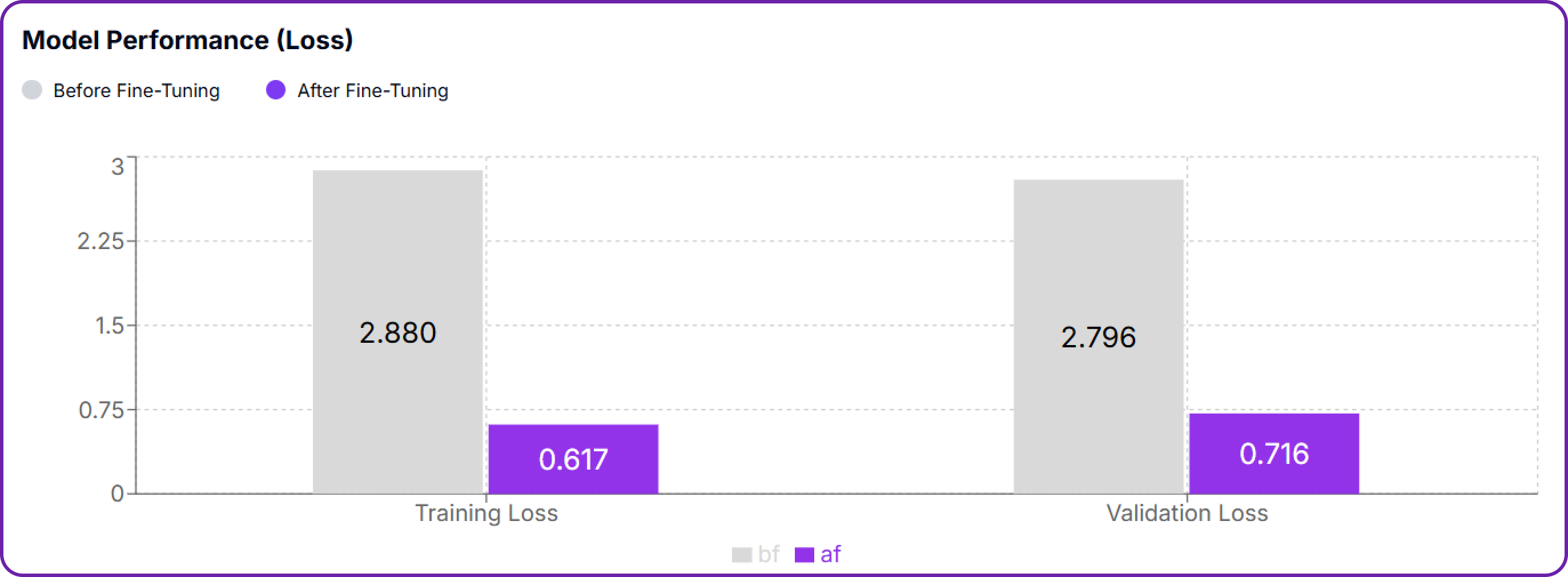
The last two metrics are the most important ones to monitor during training and one of them is the loss compare graph, which shows the training loss and evaluation loss before and after fine-tuning. The goal is to see a steady decrease in both losses, indicating that the model is learning effectively from the dataset.
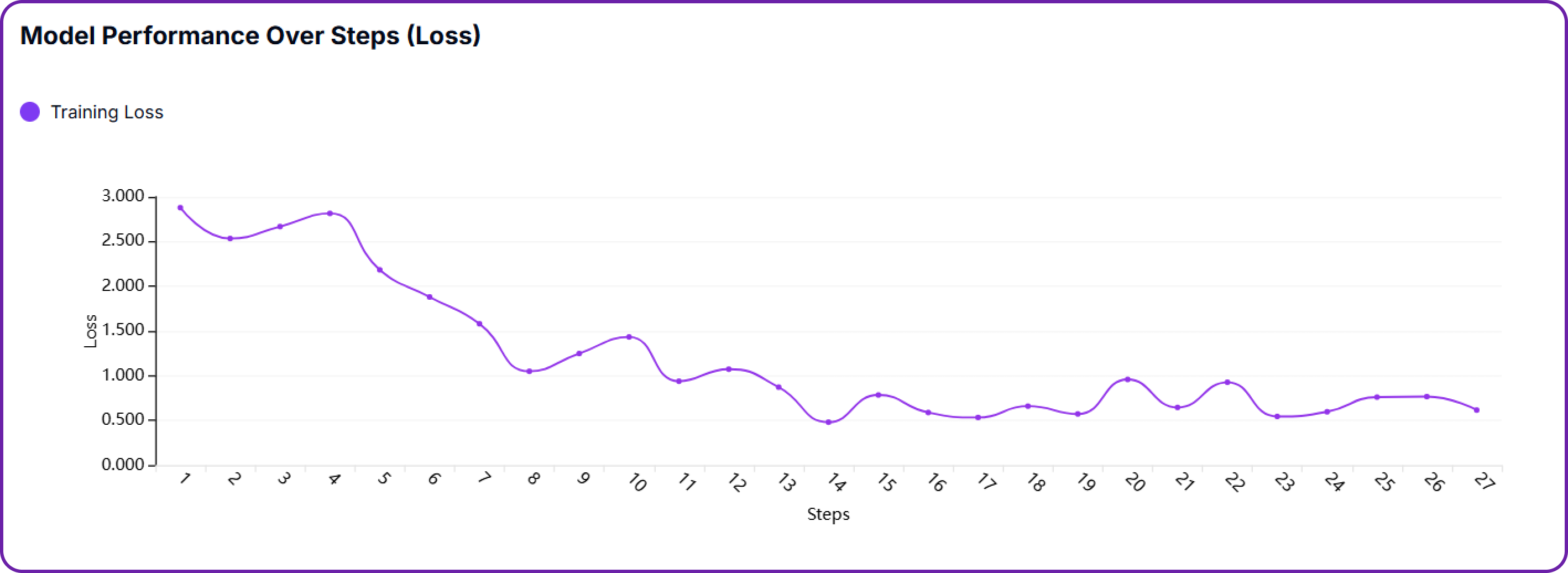
Similarly, the loss plot graph shows the training loss over time. A steady downward trend is a good sign that the model is converging.
Line chart visualising how training loss changed over time:
- A downward-sloping curve signals successful learning progression.
- Spikes or instability can suggest noisy data or poor learning rates.
- A flat or plateauing curve might indicate early convergence or underfitting.
Retrieving Training Metrics Programmatically
Just like we uploaded our dataset and kicked off a fine-tuning job via API, we can also retrieve training metrics programmatically. This is especially powerful if you’re integrating monitoring into an MLOps pipeline, or want to automatically analyse performance after each run without manually opening the dashboard.
Hyperstack provides a simple endpoint for fetching all the training details of a fine-tuned model:
GET https://console.hyperstack.cloud/ai/api/v1/named-training-info-log/{MODEL_NAME}
This endpoint returns key training metrics such as training loss, evaluation loss, training status, and performance history. It’s the same data you’d see in the UI graphs, but now available directly in your workflow.
Let's code this out in Python:
def fetch_training_metrics(api_key: str, model_name: str) -> dict:
"""
Fetches training metrics for a fine-tuned model from Hyperstack.
Includes training loss, evaluation loss, and job status.
"""
url = f"https://console.hyperstack.cloud/ai/api/v1/named-training-info-log/{model_name}"
headers = {"api_key": api_key, "Content-Type": "application/json"}
print(f"Fetching training metrics for model '{model_name}'...")
response = requests.get(url, headers=headers)
response.raise_for_status()
data = response.json()
print("Metrics successfully retrieved.")
return data
We can call this function with our fine-tuned model name:
metrics = fetch_training_metrics(API_KEY, "agentic-llama-3.1-8B-v1")
print(metrics)
A sample response looks like this:
{
"metrics": {
"end_train_message": [
"Training job ended"
],
"end_train_status": [
"dormant"
],
"eval_loss": [
3.7874512672424316,
2.4864907264709473
],
"eval_perplexity": [],
"loss": [
4.3348,
4.3847,
4.6717,
3.1481,
2.3838
],
"perplexity": []
},
"status": "success"
}
When you fetch metrics through the API, you’ll notice a few key fields in the response:
- end_train_message / end_train_status: Tells you how the job ended. For example,
"Training job ended"with status"dormant"means everything completed normally, while"failed"would indicate something went wrong. - eval_loss: Shows validation loss before and after fine-tuning. The second value is the most important — lower values mean the model generalized better.
- loss: A sequence of training loss values over time. This is your main signal to see if the model is actually learning. The last value is the final training loss.
- eval_perplexity / perplexity (optional): Perplexity is another way of measuring model confidence. Lower is better, but not all runs compute it, so these fields may be empty.
Part 3: Evaluating Our Fine-Tuned Agentic Model
Once our fine-tuning job is complete, the next critical step is to evaluate how well our model performs on unseen data. Evaluation helps us understand if the model has truly learned to use tools effectively and can generalise beyond the training examples.
Step 1: Uploading the Evaluation Dataset
First, we have to upload our evaluation dataset, just like we did with the training dataset. This dataset should contain examples that the model has never seen before, allowing us to test its ability to reason and call tools correctly.
We can upload the evaluation dataset using either the UI or the API, following the same steps outlined in Part 1. Just make sure to use a different tag, such as agentic-workflow-eval, to distinguish it from the training data.
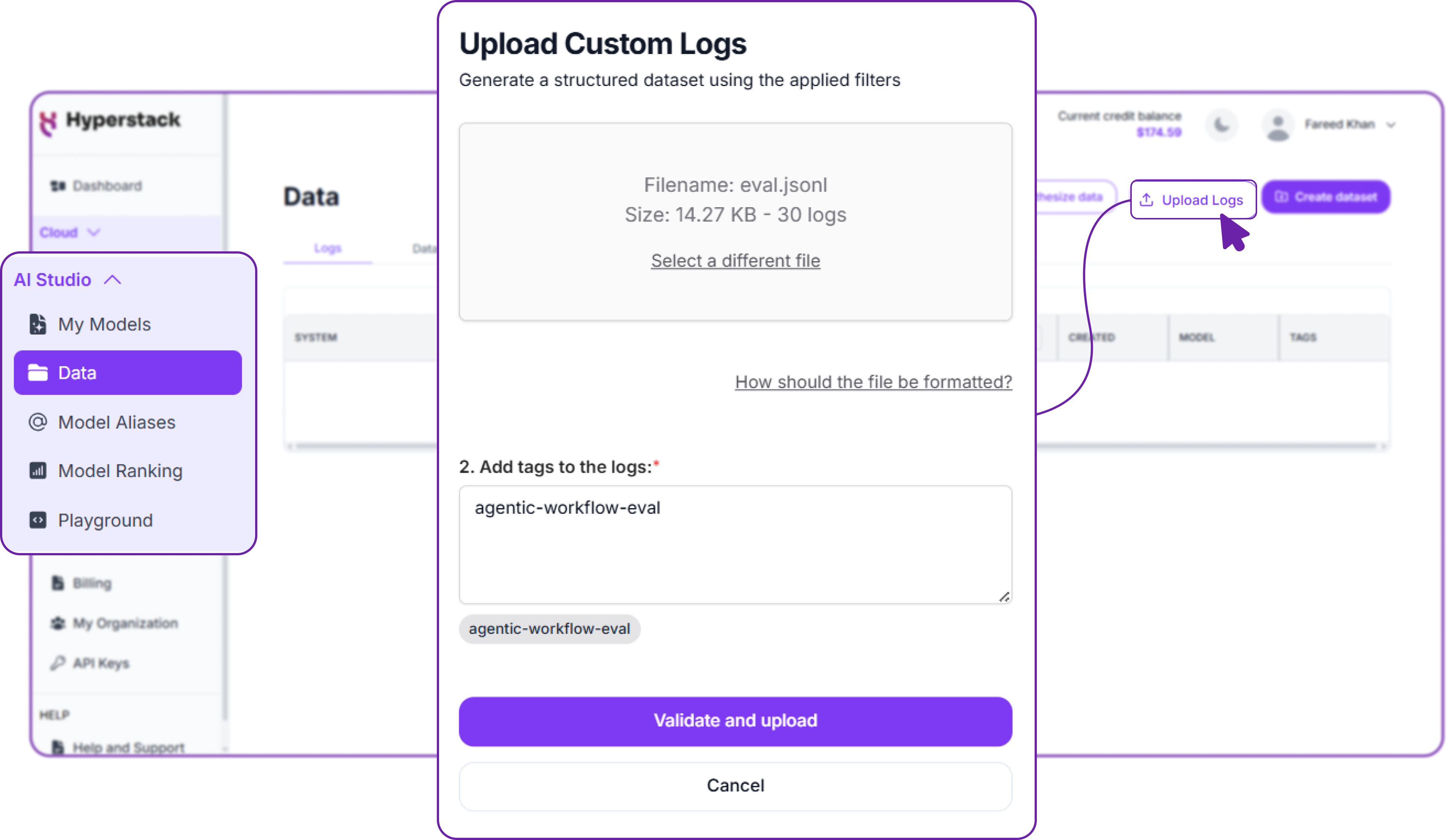
Once the evaluation dataset is uploaded, we can create a new dataset in Hyperstack AI Studio specifically for evaluation. This is done in the same way as creating a training dataset, but we select the evaluation tag instead.
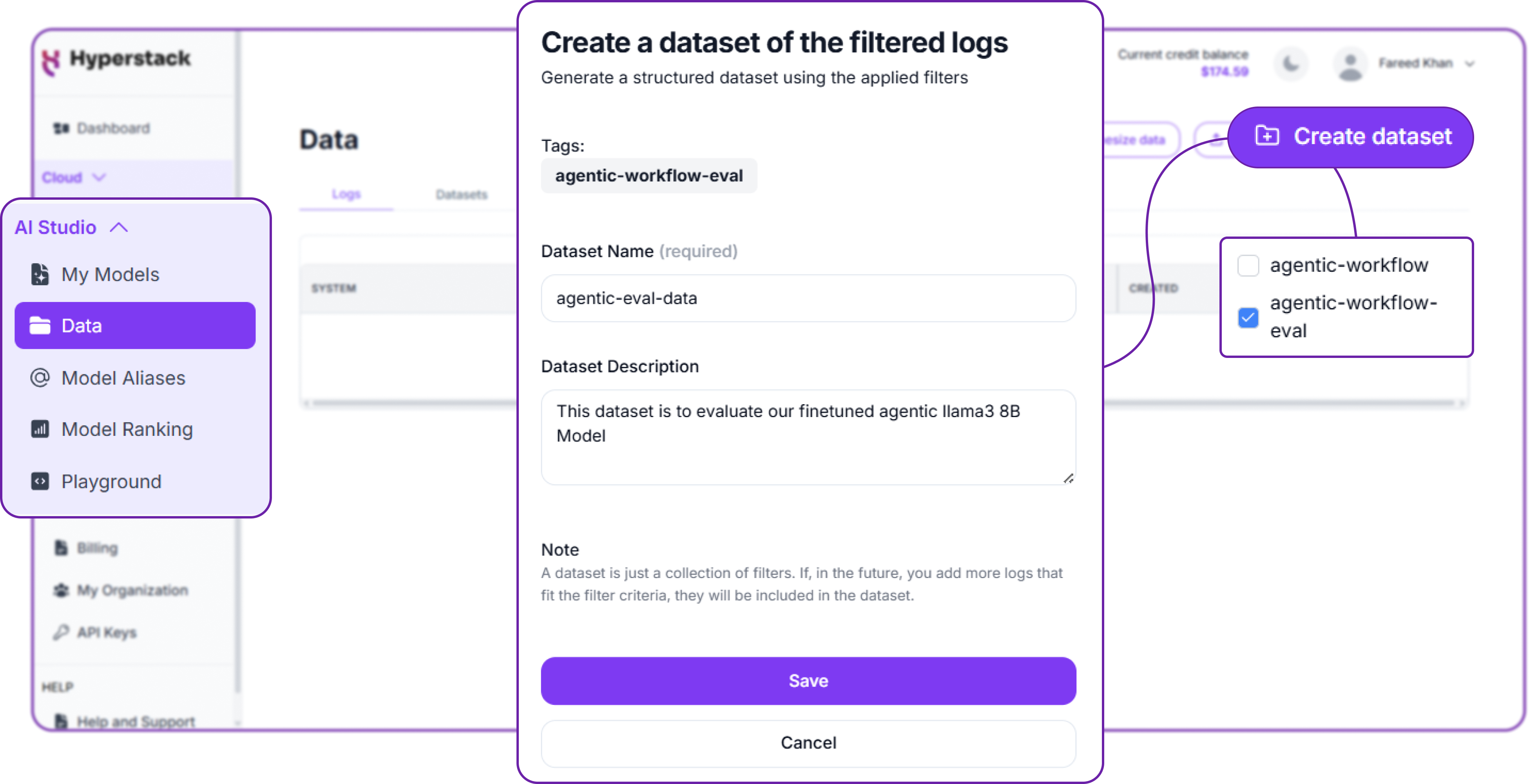
Step 2: Creating and Running the Evaluation Job
First and the most common way is to use Benchmark Evaluation. This allows you to compare the performance of your fine-tuned model against a set of predefined benchmarks. Hyperstack provides a variety of benchmark tasks that you can use for this purpose.
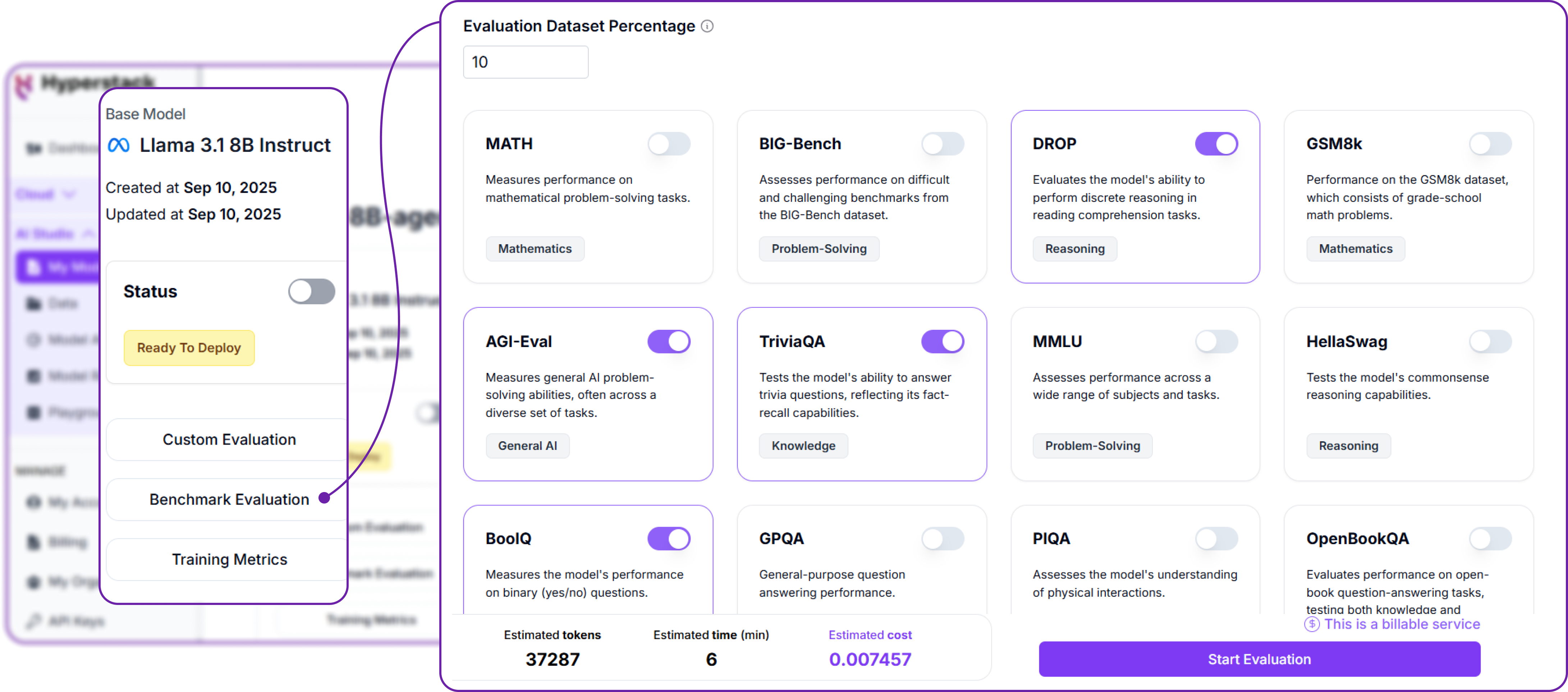
Hyperstack provides a variety of benchmark tasks that are most commonly used to evaluate language models and also provides the total number of cost and time required to complete the evaluation job.
The second way is to use Custom Evaluation and this is what we will be focusing on. Custom evaluation allows you to create specific tests that check if the model is using tools correctly. For example, you can create a test that verifies if the model calls the create_support_ticket tool when the user reports an issue.

We can simply create a custom evaluation job by selecting the evaluation dataset we created earlier, and then defining the specific custom evaluation criteria we want to test.

Before we start the evaluation job, we need to deploy our fine-tuned model as the evaluation is performed via API calls. Once that done let's start the evaluation job.
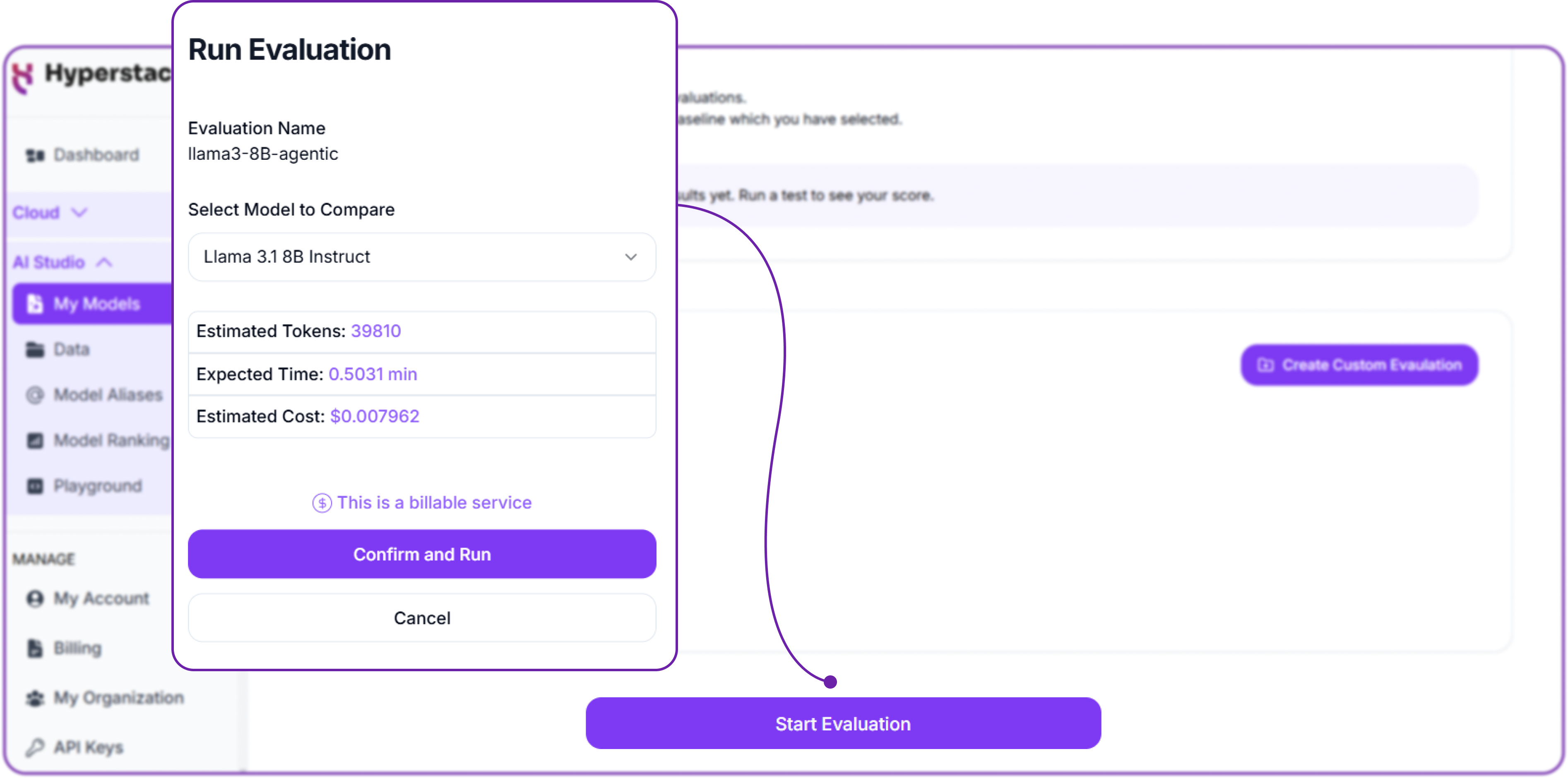
We need to provide the same base model used for fine-tuning. Based on the evaluation data, we can see the estimated tokens, time, and cost required to complete the evaluation job.

Once the evaluation job is completed, we can view the results in the Hyperstack AI Studio. This will give us insights into how well our model is performing on the evaluation dataset and whether it is effectively using the tools we have provided.
Step 3: Understanding Evaluation Metrics
When evaluating your fine-tuned model, the following metrics provide insights into its performance:
-
Improvement %: Represents the net percentage of tests where your fine-tuned model outperformed the base model. It is calculated as
(Wins - Losses) / Total Tests * 100. A higher value indicates stronger overall performance. -
Win / Draw / Loss:
- Win: The number of prompts where the fine-tuned model was judged to perform better than the baseline model.
- Draw: The number of cases where both the fine-tuned model and the baseline model produced equivalent outputs.
- Loss: The number of prompts where the baseline model outperformed the fine-tuned model.
We have a success rate of ~53% with 20 examples out of 30 being correctly identified, which is a good starting point, but there is definitely room for improvement.
Part 4: Inference with Our Fine-Tuned Agentic Model
Once we have fine-tuned and evaluated our model, the final step is to inference with it. This means using the model to generate responses to new user inputs, ideally calling the appropriate tools as needed.
Testing in the Hyperstack Playground
Hyperstack provides a simple UI under playground section for testing your fine-tuned model directly in the browser. We can either inference with the model or compare it with the base or other fine-tuned models. Let's perform a comparison between our fine-tuned model and the base model.
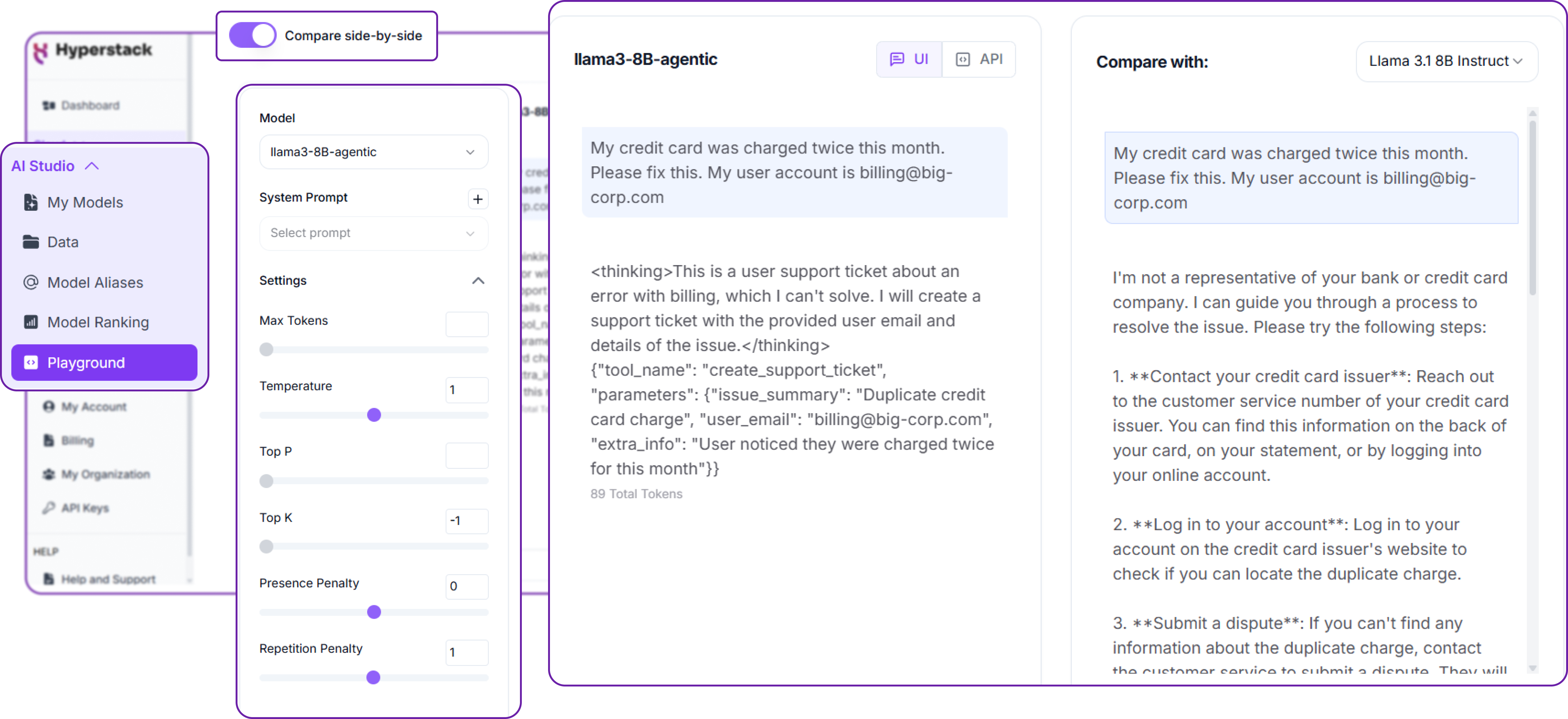
By passing an unseen prompt to both models, we can see how each responds. The base model might give a generic answer, while our fine-tuned model reasons through the problem and calls the appropriate tool.
Programmatic Inference: Building a Full Workflow
Great, now that we have our fine-tuned agentic model ready, let's see how we can use it programmatically via the Hyperstack Inference API. This is especially useful for integrating the model into applications or services.
You can simply get the code to inference with your fine-tuned model directly from the UI by clicking on the API endpoint button.
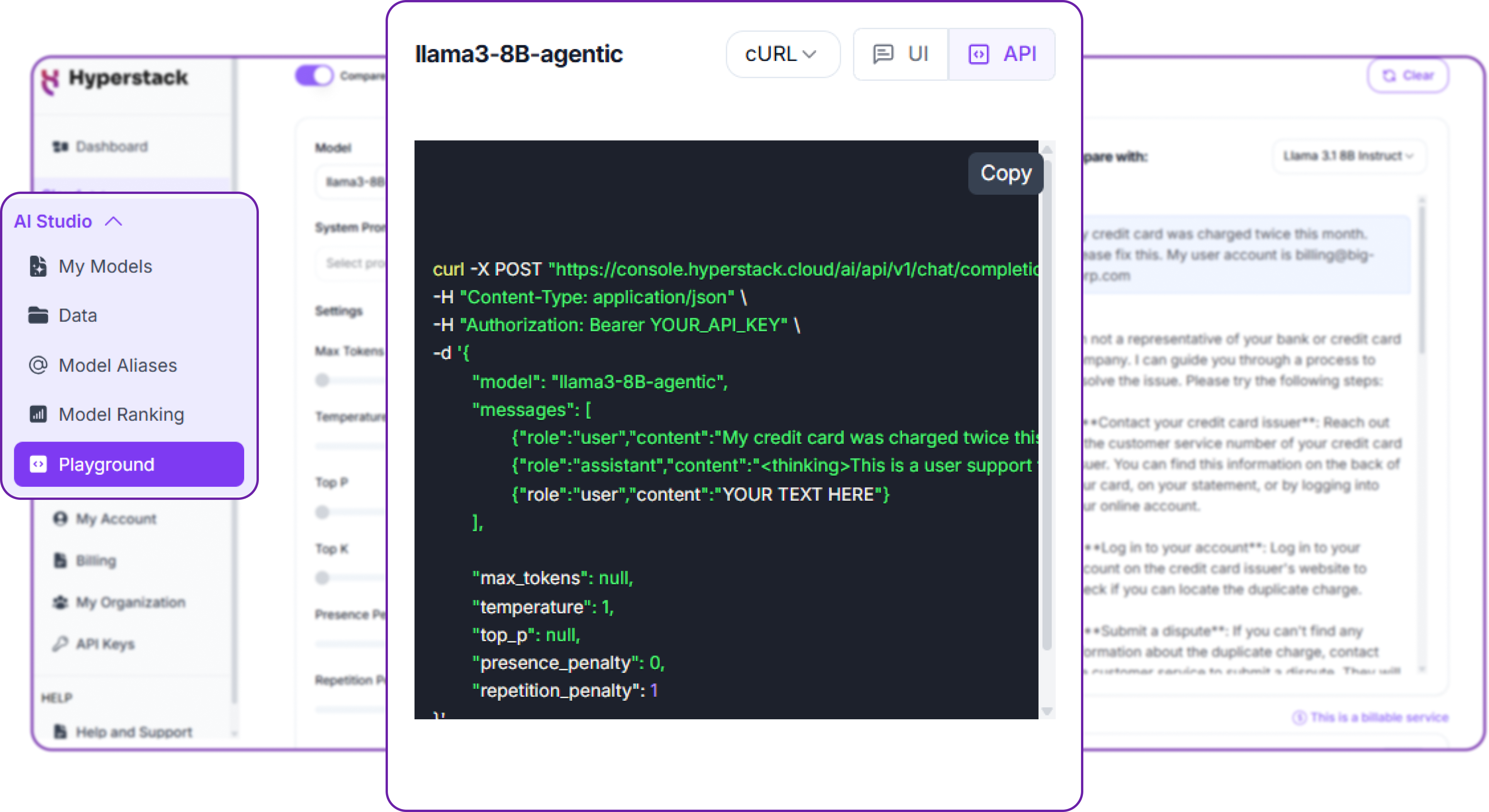
To make an inference request, you send a POST request to the following endpoint:
POST https://console.hyperstack.cloud/ai/api/v1/chat/completions
Let's build a complete workflow that takes a user's prompt, gets a tool call from our agent, and then executes the corresponding function in our code.
Step 1: Defining the Tools in Python
Before our agent can call a tool, that tool must exist as a function in our application. For this guide, we'll create a few simple Python functions that simulate the actions our support agent can take. In a real application, these would contain logic to interact with databases, ticketing systems, or other APIs.
def create_support_ticket(issue_summary: str, user_email: str, extra_info: str = ""):
"""Simulates creating a support ticket in a ticketing system."""
print("\n--- EXECUTING TOOL: create_support_ticket ---")
print(f"Ticket created for: {user_email}")
print(f"Summary: {issue_summary}")
if extra_info:
print(f"Details: {extra_info}")
print("------------------------------------------")
return {"status": "success", "ticket_id": f"TICKET_{hash(user_email)}"}
def check_finetune_job_status(job_id: str):
"""Simulates checking the status of a fine-tuning job."""
print("\n--- EXECUTING TOOL: check_finetune_job_status ---")
print(f"Checking status for job_id: {job_id}...")
# In a real app, you'd query your database or an API here.
print("---------------------------------------------")
return {"status": "running", "progress": "75%"}
def no_tool_available(reason: str):
"""Handles cases where no specific tool matches the user's request."""
print("\n--- NO TOOL AVAILABLE ---")
print(f"Reason: {reason}")
print("-------------------------")
return {"status": "no_action_taken"}
These functions are our "acting" layer. The agent's job is simply to tell us which one to call and what to pass to it.
Step 2: Calling the Agent via the API
Next, we'll create a function to communicate with our fine-tuned model via the Hyperstack API. This function will take a user's prompt and return the model's raw output string, which includes both the <thinking> block and the JSON tool call.
Now let's implement the function to call our fine-tuned agent model via the Hyperstack Inference API.
def get_agent_tool_call(user_prompt: str, model_name: str) -> str:
"""
Sends a prompt to our fine-tuned agent and returns its raw text response.
"""
url = "https://console.hyperstack.cloud/ai/api/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"api_key": API_KEY
}
payload = {
"model": model_name,
"messages": [{"role": "user", "content": user_prompt}],
"max_tokens": 256,
"temperature": 0.1, # Low temperature for reliable, deterministic tool calls
}
print(f"Querying agent '{model_name}' with prompt: '{user_prompt}'")
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
# Extract the raw content string from the assistant's message
assistant_content = response.json()['choices'][0]['message']['content']
return assistant_content
This function handles the network communication. Now for the final, and most exciting, part.
Step 3: Parsing the Response and Executing the Tool
# main.py
from agent import get_agent_tool_call
from tools import create_support_ticket, check_finetune_job_status, no_tool_available
import json
def execute_tool_from_agent_response(response_text: str):
"""
Parses the agent's response, extracts the JSON tool call, and executes the
corresponding Python function.
"""
print("\n--- Received Raw Agent Response ---")
print(response_text)
print("-----------------------------------")
try:
# The JSON part is usually the last part of the response after the thinking block.
# A robust way to find it is to look for the first '{'
json_str_start = response_text.find('{')
if json_str_start == -1:
raise ValueError("No JSON object found in the agent's response.")
json_str = response_text[json_str_start:]
tool_call_data = json.loads(json_str)
tool_name = tool_call_data.get("tool_name")
parameters = tool_call_data.get("parameters", {})
# Create a "tool registry" to map tool names to our actual Python functions
tool_registry = {
"create_support_ticket": create_support_ticket,
"check_finetune_job_status": check_finetune_job_status,
"no_tool_available": no_tool_available
}
if tool_name in tool_registry:
# Select the correct function from the registry
tool_function = tool_registry[tool_name]
# Dynamically call the function with its parameters
# The **parameters syntax unpacks the dictionary into keyword arguments
result = tool_function(**parameters)
print("\nTool execution result:", result)
else:
print(f"Error: Tool '{tool_name}' not found in registry.")
except (json.JSONDecodeError, ValueError, KeyError) as e:
print(f"Error parsing or executing tool call: {e}")
Now let's define our user prompt and the fine-tuned model name we created earlier.
fine_tuned_model = "llama3-8B-agentic" # Use your fine-tuned model's name
prompt = "My credit card was charged twice this month. Please fix this. My user account is billing@big-corp.com"
First, we get the tool call from our fine-tuned agent:
# Get the tool call from our fine-tuned agent
agent_response = get_agent_tool_call(prompt, fine_tuned_model)
It gives us a response like this:
Querying agent 'agentic-llama-3.1-8B-v1' with prompt: 'My credit card was charged twice this month. Please fix this. My user account is billing@big-corp.com'
--- Received Raw Agent Response ---
<thinking>The user is reporting a billing issue. They state they were charged twice and provide their user email. This is not something I can resolve directly. The correct action is to create a support ticket so a human agent can investigate. I will use the `create_support_ticket` tool. I need to extract the issue summary and the user's email from the prompt.</thinking>
{"tool_name": "create_support_ticket", "parameters": {"issue_summary": "Duplicate credit card charge this month", "user_email": "billing@big-corp.com"}}
Notice how the model first generates the <thinking> block, exactly as we trained it to, before producing the final JSON. This makes the agent's behavior transparent and debuggable.
Then, we parse that response and execute the correct tool:
# Parse the response and execute the correct tool
if agent_response:
execute_tool_from_agent_response(agent_response)
--- EXECUTING TOOL: create_support_ticket ---
Ticket created for: billing@big-corp.com
Summary: Duplicate credit card charge this month
------------------------------------------
Tool execution result: {'status': 'success', 'ticket_id': 'TICKET_-1234567890123456789'}
With this minimal code, we have a complete end-to-end workflow:
- A user provides a prompt describing their issue.
- Our fine-tuned agent model processes the prompt and decides which tool to call.
- We parse the agent's response, extract the tool call, and execute the corresponding function in our application.
- The tool function performs its action (e.g., creating a support ticket) and returns a result.
- We print out the result of the tool execution.
Conclusion and Next Steps
In this guide, we have walked through the entire process of building an agentic AI model using Hyperstack AI Studio. We started by preparing a dataset of Chain-of-Thought examples, then uploaded it to Hyperstack via their API. Next, we created a fine-tuning job to specialise a base model for tool use, monitored its training progress, and evaluated its performance on unseen data. Finally, we demonstrated how to integrate the fine-tuned model into an application workflow, allowing it to reason about user requests and call appropriate tools programmatically.
We can further improve our agentic model by:
- Expanding our training dataset with more diverse examples.
- Incorporating user feedback to refine the model's responses.
- Exploring advanced techniques like few-shot learning to enhance performance with limited data.
By following this guide, you now have a solid foundation for building intelligent agents that can assist users effectively.
Fine-Tune LLMs Using AI Studio Today!
Deploy market-ready AI products faster with Hyperstack's full-stack Gen AI platform.

FAQs
What is AI Studio?
AI Studio is a full-stack Gen AI platform built on Hyperstack’s high-performance infrastructure. It is a unified platform that helps you go from dataset to deployed model in one place, faster.
Which models can I fine-tune on AI Studio?
You can fine-tune the following popular open-source models on the AI Studio:- Llama 3.3 70B
- Llama 3.1 8B Instruct
- Mistral Small 3
How does AI Studio measure improvements in fine-tuned models?
Through Custom Evaluations, tracking tool accuracy and parameter correctness, the Hyperstack AI Studio delivers quantifiable improvements in reliability, precision and workflow readiness.
Will I need to change my existing stack to use Hyperstack?
No. Hyperstack’s OpenAI-compatible API allows drop-in replacement with just base_url and api_key updates, avoiding costly rewrites.
Can Hyperstack handle large-scale agentic workflows under heavy demand?
Yes. Hyperstack’s scalable inference infrastructure supports surges, parallel tool calls, and low-latency responses for production-grade agent workloads.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

