
 November 24, 2025
November 24, 2025 Updated on 18 Feb 2026
Updated on 18 Feb 2026





Table of contents


We’re back with your weekly dose of Hyperstack updates!
This week comes with some seriously useful upgrades you’ll want to try. Whether you’re spinning up VMs, fine-tuning models or experimenting in AI Studio, these updates are here to make your workflow smoother and your builds faster.
Take a minute to explore what’s new and see how far you can push your next project on Hyperstack.
New on AI Studio
Here’s what’s new on our full-stack Gen AI platform, AI Studio this week:
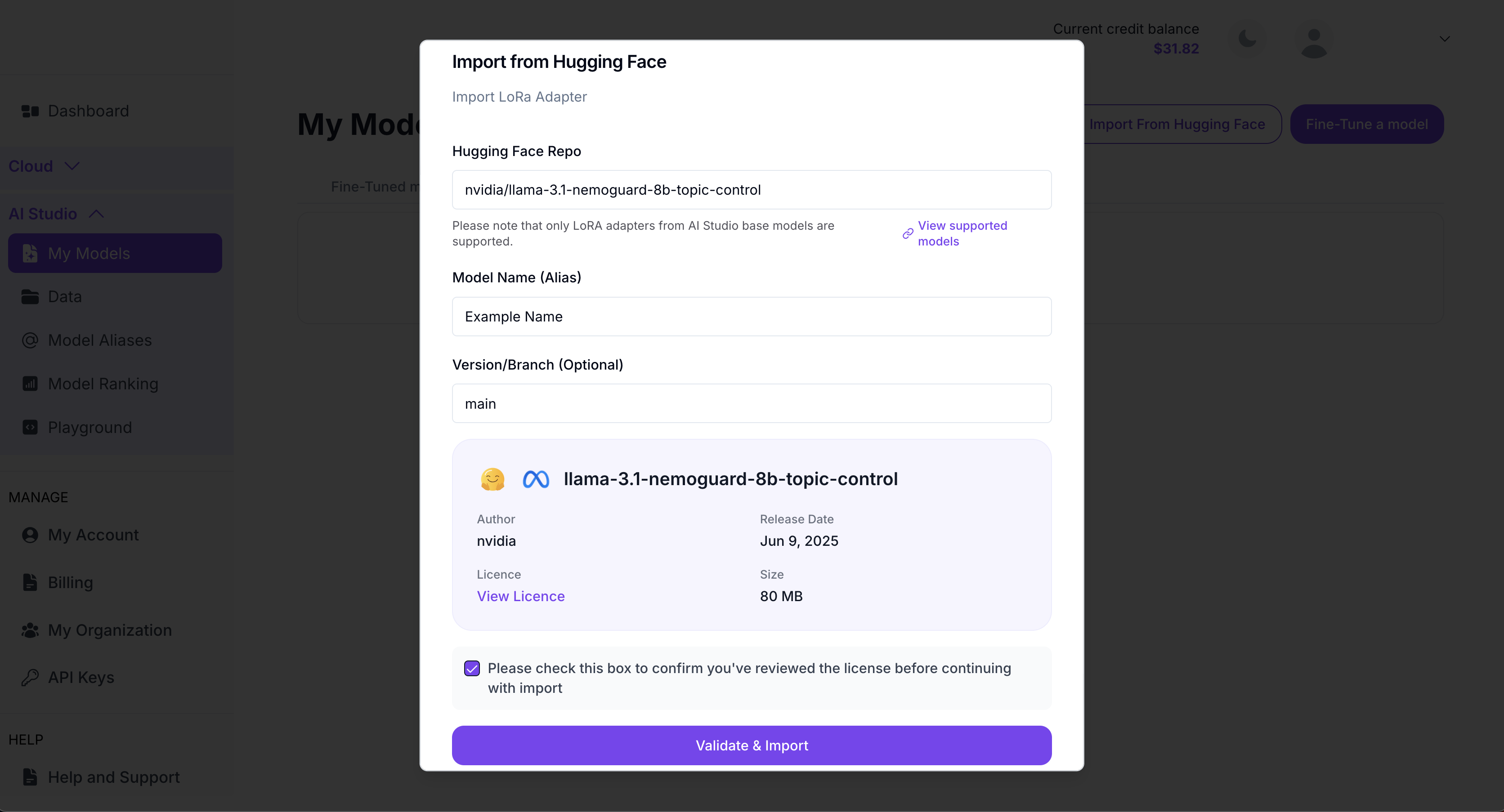
Import LoRA Adapters Directly From Hugging Face
No more manual downloads or messy workflows. You can now import external LoRA adapters from Hugging Face straight into AI Studio and plug them into supported base models. Use them instantly in the AI Studio Playground or deploy them via API for inference. Learn more about importing LoRA adapters here.
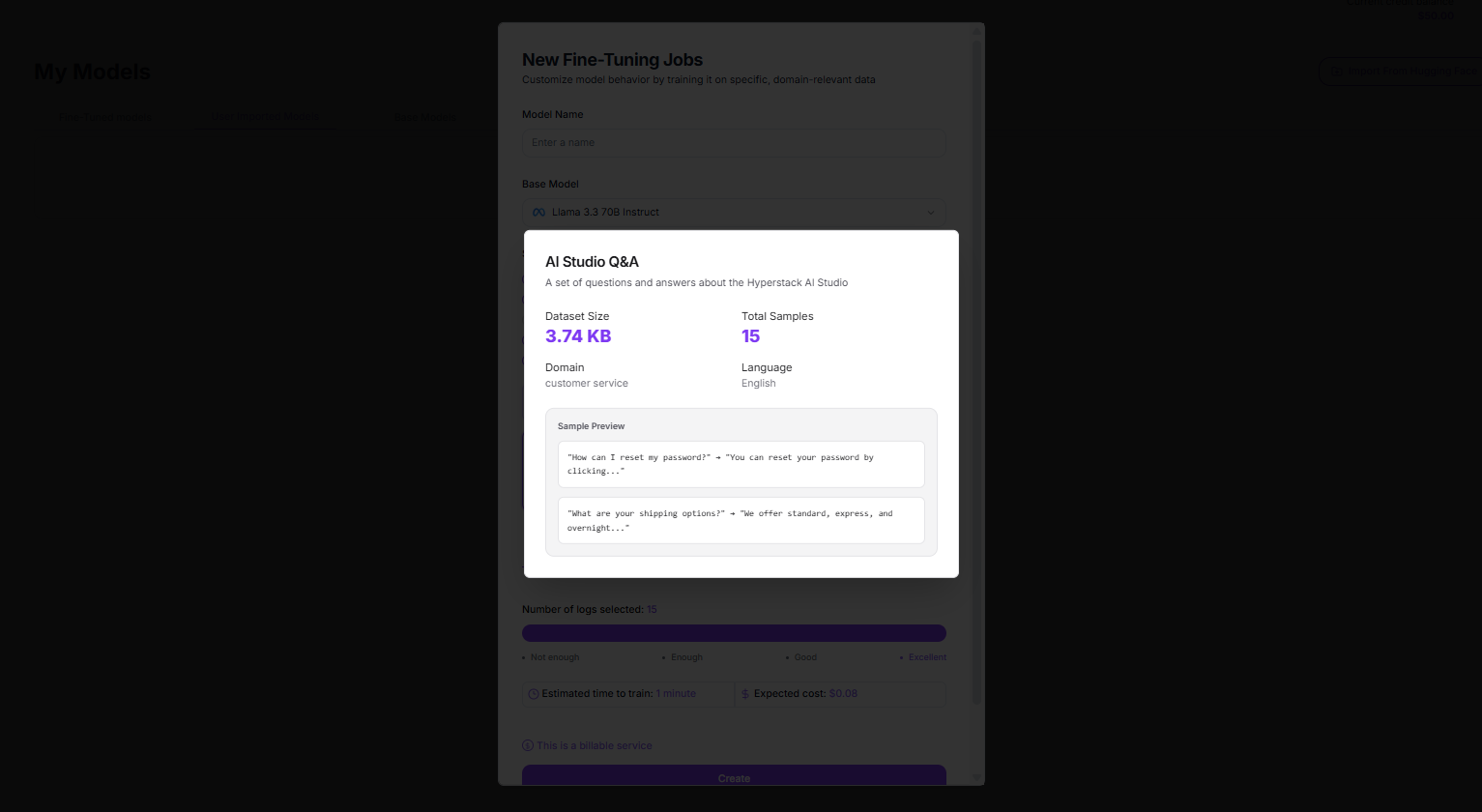
Sample Datasets Now in the UI
No more hunting for starter data. You’ll now find a curated sample dataset directly inside the AI Studio interface, perfect for quick experiments, testing or getting hands-on without setup friction.
Export Your Fine-Tuned Models
You can now export any fine-tuned model you create in AI Studio and use it for external use, giving you more control and flexibility in your ML workflows.
Haven't tried AI Studio yet? Give Hyperstack AI Studio a spin and see how simple and faster AI building can be.
New on Hyperstack
Here’s what’s new on Hyperstack this week:
Public IP Behaviour Change During Hibernation
You now have the option to retain your VM’s public IP address during hibernation. By default, the public IP is now automatically released to help reduce idle resource costs. Learn how to hibernate a Virtual Machine using the UI.
Latest Fixes and Improvements
A new retain_ip parameter has been added to the Hibernate VM API, so you can programmatically decide whether your VM's public IP stays attached during hibernation.
New on our Blog
Check out the latest tutorials on Hyperstack:
Integrate Hyperstack AI Studio with RooCode for Next-Gen Coding Support:
A Step-by-Step Guide
Modern developers are increasingly turning to AI-powered coding environments to accelerate development and improve code quality. One of the most exciting entrants in this space is Roo Code, a powerful AI-driven coding assistant designed to work directly inside Visual Studio Code (VS Code). In this guide, we’ll walk through how to integrate Hyperstack AI Studio with RooCODE to supercharge your development workflow.
Check out the full tutorial below!

Integrate Hyperstack AI Studio with Zed Code Editor for Powerful Coding Agents:
A Step-by-Step Guide
AI coding tools have evolved into intelligent environments that support code understanding, refactoring, and reasoning about complex systems. For developers who value performance and advanced AI-driven workflows, pairing Zed Editor with Hyperstack AI Studio delivers a powerful solution. This guide covers what sets Zed Editor apart, how Hyperstack AI Studio elevates its AI integration, and provides a step-by-step walkthrough for seamless setup.
Check out the full tutorial below!

Integrate Hyperstack AI Studio as a Provider in LiteLLM:
A Step-by-Step Guide
With the rapid evolution of AI-driven development tools, integrating large language models (LLMs) into software systems has become increasingly accessible and modular. Developers are no longer restricted to a single provider now, they can build hybrid AI systems by combining inference backends, model management tools, and application layer SDKs. Two such powerful tools that make this process seamless are Hyperstack AI Studio and LiteLLM. In this guide, we provide detailed steps to integrate Hyperstack AI Studio as a Provider in LiteLLM.
Check out the full tutorial below!

We’ve got more tutorials coming next week, so stay tuned.
Have an idea you'd like to see in Hyperstack? Let’s bring it to life.
At Hyperstack, we’re committed to continuous improvement and your ideas are a key driver of our innovation.
→ Is there a feature you’ve been waiting for?
→ Something that could speed up your workday?
→ Or a tweak that would make things feel effortless?
Tell us what would make your Hyperstack experience even better. Your feedback sets the direction for what we build next.
That's it for this week's Hyperstack Rundown! Stay tuned for more updates next week and subscribe to our newsletter below for exclusive AI and GPU insights delivered to your inbox!
Missed the Previous Editions?
Catch up on everything you need to know from Hyperstack Weekly below:
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

.png?width=648&height=389&name=Blog%20thumbnail%20-%201000x600%20-%201000x600%20(3).png)
.png?width=648&height=389&name=Blog%20thumbnail%20-%201000x600%20-%201000x600%20(4).png)
.png?width=648&height=389&name=Blog%20thumbnail%20-%201000x600%20-%201000x600%20(6).png)
 3 Jul 2026
3 Jul 2026
.png?width=3322&height=1788&name=image-playground-4-0976c9c22b9ddde7be5ac6810a08359e%20(1).png)

.png?width=648&height=389&name=Blog%20thumbnail%20-%201000x600%20-%201000x600%20(2).png)
.png?width=648&height=389&name=Blog%20thumbnail%20-%201000x600%20-%201000x600%20(1).png)


