

TABLE OF CONTENTS
NVIDIA H100 GPUs On-Demand
In our latest tutorial, we explore how to deploy and use Qwen3-Next-80B-A3B on Hyperstack. From setting up your environment to running tasks, we guide you through each step to help you get started with Alibaba's latest model.
What is Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B is one of the latest models in the Qwen3-Next family, designed to combine massive model capacity with efficient inference. Built as a Mixture-of-Experts (MoE) model, it contains 80 billion parameters in total but only activates about 3 billion of them per token. This gives it the power of a very large model while keeping the speed and cost closer to that of a smaller one.

The model comes in two main versions:
-
Instruct which is tuned for following instructions, answering questions and engaging in natural conversations.
-
Thinking which is built for deeper reasoning tasks where multi-step thought processes are valuable.
Another great aspect of this model is its ability to handle ultra-long contexts, supporting input lengths that can reach hundreds of thousands of tokens. This makes it ideal for workloads like processing large documents, maintaining long conversations or analysing extensive datasets.
What are the features of Qwen3-Next-80B-A3B?
The key features of the latest Qwen3-Next-80B-A3B model include:
-
Mixture-of-Experts Efficiency: Instead of running all 80B parameters, only ~3B are used per token. This means faster responses and lower compute costs, making it easier to deploy at scale.
-
Ultra-Long Context Handling: Natively supports up to 262k tokens, with scaling possible to ~1M tokens. You can feed in long reports, entire books, or massive chat histories without the model “forgetting” earlier context.
-
Hybrid Attention with Gated Mechanisms: Combines Gated Attention and DeltaNet for stable performance on long sequences. Maintains accuracy even as inputs grow, so you get more reliable answers from long conversations or documents.
-
Multi-Token Prediction (MTP): Can generate multiple tokens at once during inference. Produces outputs faster, reducing latency and improving throughput for chatbots or real-time applications.
-
Stable Training and Inference: Optimisations like zero-centred RMSNorm and improved router initialisation reduce instability. This leads to smoother, more consistent responses without odd model behaviour.
-
Flexible Modes (Instruct vs Thinking): Instruct gives concise, user-ready outputs, while Thinking enables detailed reasoning chains. This lets you choose the right balance between efficiency and depth, depending on your use case.
-
Cost-Effective Scaling: Strong performance despite reduced active compute compared to traditional dense models. Saves both time and money, whether you’re running experiments or deploying to production.
Steps to Deploy Qwen3-Next-80B-A3B on Hyperstack
Now, let's walk through the step-by-step process of deploying Qwen3-Next-80B-A3B on Hyperstack.
Step 1: Accessing Hyperstack
- Go to the Hyperstack website and log in to your account.
- If you're new to Hyperstack, you'll need to create an account and set up your billing information. Check our documentation to get started with Hyperstack.
- Once logged in, you'll be greeted by the Hyperstack dashboard, which provides an overview of your resources and deployments.
Step 2: Deploying a New Virtual Machine
Initiate Deployment
- Look for the "Deploy New Virtual Machine" button on the dashboard.
- Click it to start the deployment process.
Select Hardware Configuration
- In the hardware options, choose the "4 x NVIDIA H100 PCIe" flavour.
Choose the Operating System
- Select the "Ubuntu Server 22.04 LTS R550 CUDA 12.4 with Docker".
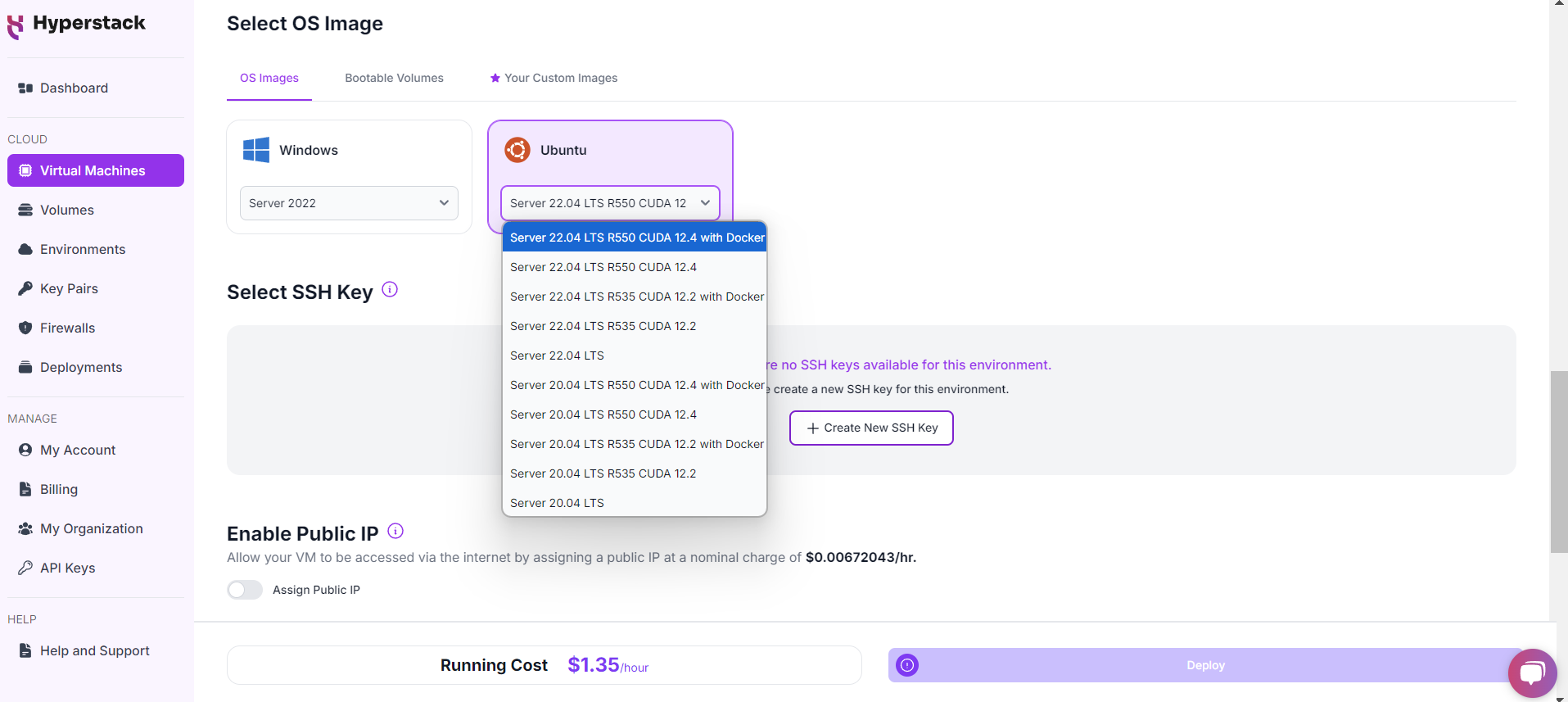
Select a keypair
- Select one of the keypairs in your account. Don't have a keypair yet? See our Getting Started tutorial for creating one.
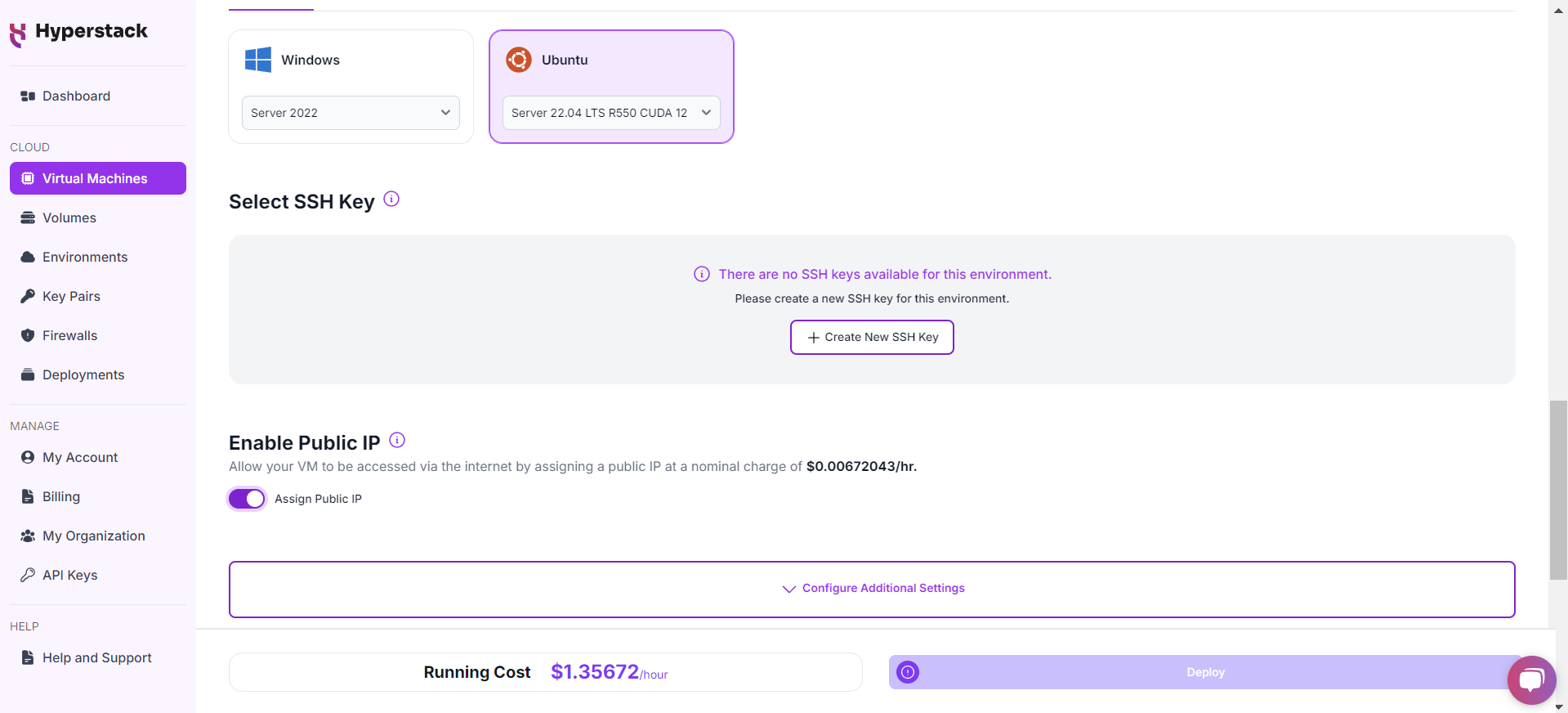
Network Configuration
- Ensure you assign a Public IP to your Virtual machine.
- This allows you to access your VM from the internet, which is crucial for remote management and API access.
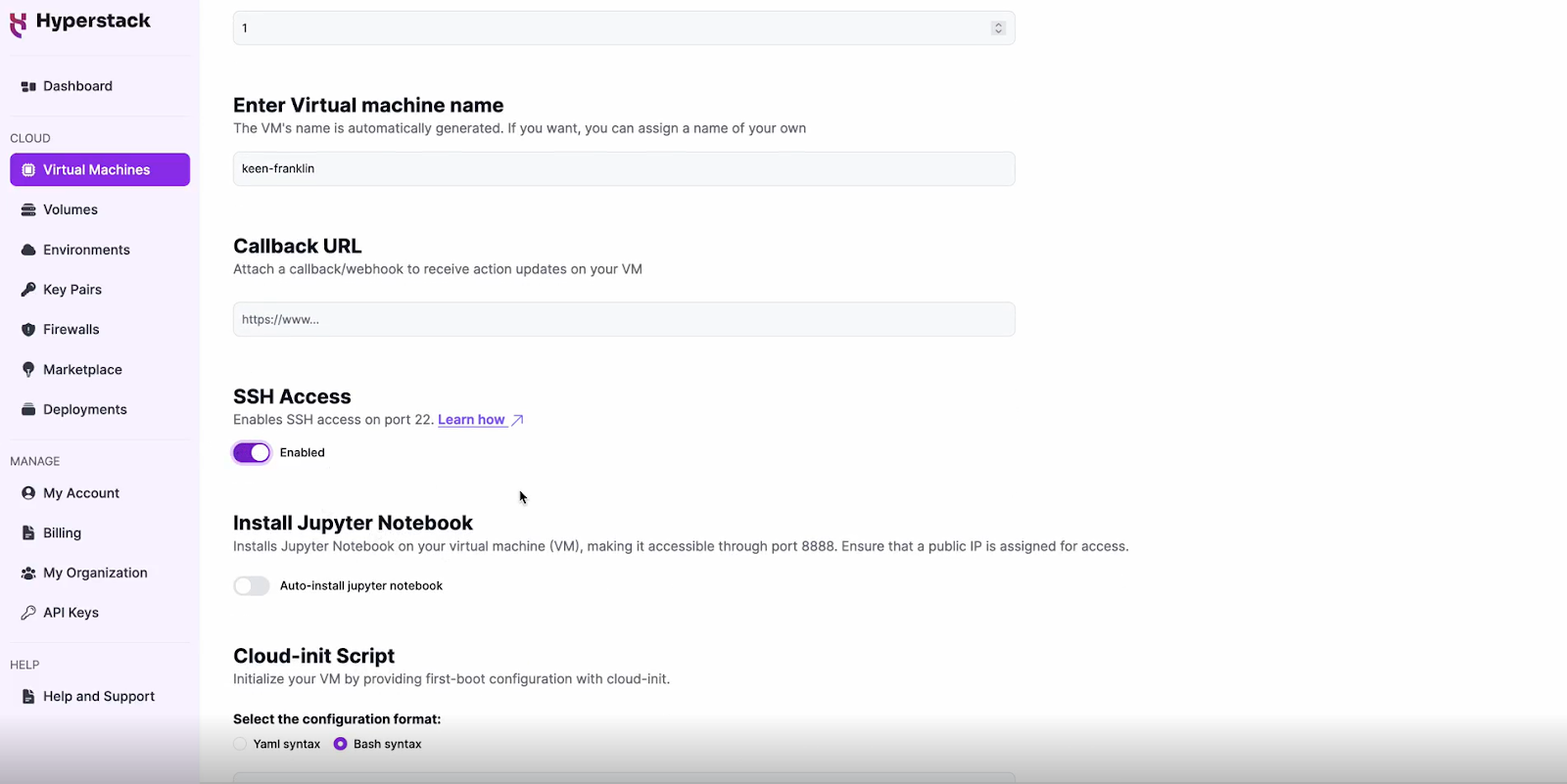
Enable SSH Access
- Make sure to enable an SSH connection.
- You'll need this to connect and manage your VM securely.
Review and Deploy
- Double-check all your settings.
- Click the "Deploy" button to launch your virtual machine.
Step 3: Accessing Your VM
Once the deployment is complete, you can access your VM:
Locate SSH Details
- In the Hyperstack dashboard, find your VM's details.
- Look for the public IP address, which you will need to connect to your VM with SSH.
Connect via SSH
- Open a terminal on your local machine.
- Use the command ssh -i [path_to_ssh_key] [os_username]@[vm_ip_address] (e.g: ssh -i /users/username/downloads/keypair_hyperstack ubuntu@0.0.0.0.0)
- Replace username and ip_address with the details provided by Hyperstack.
Interacting with Qwen3-Next-80B-A3B
To access and experiment with Qwen3-Next-80B-A3B, SSH into your machine after completing the setup. If you are having trouble connecting with SSH, watch our recent platform tour video (at 4:08) for a demo. Once connected, use this API call on your machine to start using the Qwen3-Next-80B-A3B:
# 1) Create a docker network
docker network create docker-net
# 2) Ensure Hugging Face cache directory exists (shared with the container)
sudo mkdir -p /ephemeral/hug && sudo chmod 0777 /ephemeral/hug
# 3) Start vLLM
sudo docker run -d --gpus=all --network docker-net --ipc=host -p 8000:8000 -v /ephemeral/hug:/hug:rw --name vllm --restart always -e HF_HOME=/hug vllm/vllm-openai:v0.10.2 --model Qwen/Qwen3-Next-80B-A3B-Instruct --host 0.0.0.0 --port 8000 --async-scheduling --tensor-parallel-size=4
# 4) Start Open WebUI (points to vLLM's API)
sudo docker run -d --network docker-net -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always -e OPENAI_API_BASE_URL=http://vllm:8000/v1 ghcr.io/open-webui/open-webui:main
The entire process, from running the commands to full usability, typically completes within 7–10 minutes.
Troubleshooting Qwen3-Next-80B-A3B
If you are having any issues, please follow the instructions:
-
SSH into your VM.
-
Check the cloud-init logs with the following command: cat /var/log/cloud-init-output.log
- Use the logs to debug any issues.
Step 5: Hibernating Your VM
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
- In the Hyperstack dashboard, locate your Virtual machine.
- Look for a "Hibernate" option.
- Click to hibernate the VM, which will stop billing for compute resources while preserving your setup.
Why Deploy Qwen3-Next-80B-A3B on Hyperstack?
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying Qwen3-Next-80B-A3B:
- Availability: Hyperstack provides access to the latest and most powerful GPUs such as the NVIDIA H100 on-demand, specifically designed to handle large language models.
- Ease of Deployment: With pre-configured environments and one-click deployments, setting up complex AI models becomes significantly simpler on our platform.
- Scalability: You can easily scale your resources up or down based on your computational needs.
- Cost-Effectiveness: You pay only for the resources you use with our cost-effective cloud GPU pricing.
- Integration Capabilities: Hyperstack provides easy integration with popular AI frameworks and tools.
Explore More Tutorials
New to Hyperstack? Log in to Get Started with Our Ultimate Cloud GPU Platform Today!

FAQs
What is Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B is a Mixture-of-Experts language model designed for efficiency, scalability, and ultra-long context natural language tasks.
How does Qwen3-Next-80B-A3B differ from other models?
Qwen3-Next-80B-A3B activates only ~3B parameters per token, offering faster inference, lower costs, and high performance compared to dense models.
What context length does Qwen3-Next-80B-A3B support?
Qwen3-Next-80B-A3B supports up to 262,144 tokens natively and scales to approximately one million tokens for extended inputs.
What modes does Qwen3-Next-80B-A3B provide?
Qwen3-Next-80B-A3B provides Instruct mode for concise tasks and Thinking mode for reasoning, letting users choose flexibility for their needs.
Why is Qwen3-Next-80B-A3B considered cost-effective?
Qwen3-Next-80B-A3B reduces compute usage by leveraging sparse experts, making AI deployments cheaper while maintaining strong results and efficiency.
Who benefits most from Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B benefits researchers, enterprises, and developers needing scalable AI solutions for long documents, reasoning-intensive workloads, and efficient deployments.
Where can I access the Qwen3-Next-80B-A3B model?
You can easily access the latest Qwen/Qwen3-Next-80B-A3B on Hugging Face.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

