

TABLE OF CONTENTS
NVIDIA H100 SXM On-Demand
Welcome to Hyperstack Weekly Rundown
It's that time again. Weekly Rundown is here and there's a lot to catch up on. A brand-new Image Playground just landed in AI Studio, new tutorials dropped on the blog and a round of platform improvements shipped quietly in the background. Whether you're generating images, optimising inference costs or running regulated research workloads, this week had something for you.
Take a few minutes to catch up on everything.
New on Hyperstack AI Studio
Check out what's new on AI Studio this week:
Image Playground
A new dedicated Image Playground is now available alongside the existing Text Playground. You can now generate and edit images using a catalog of vision models, with customisable parameters and a side-by-side compare feature for evaluating multiple models at once.
.png?width=3322&height=1788&name=image-playground-4-0976c9c22b9ddde7be5ac6810a08359e%20(1).png)
Text-to-Image Generation
Generate images from a text prompt using any supported text-to-image model. Adjust parameters, iterate on outputs and move from prompt to production-ready asset directly inside the console.
Image-to-Image Editing
Upload a reference image alongside a text prompt to generate a modified or transformed result using image generation models. Use it for style transfer, conditional generation or guided edits without writing any code from the console.
API View with cURL Support
The Image Playground includes a UI/API toggle. Switch to API view to see the corresponding cURL command for your current request, adapting dynamically for both text-to-image and image-to-image workflows.
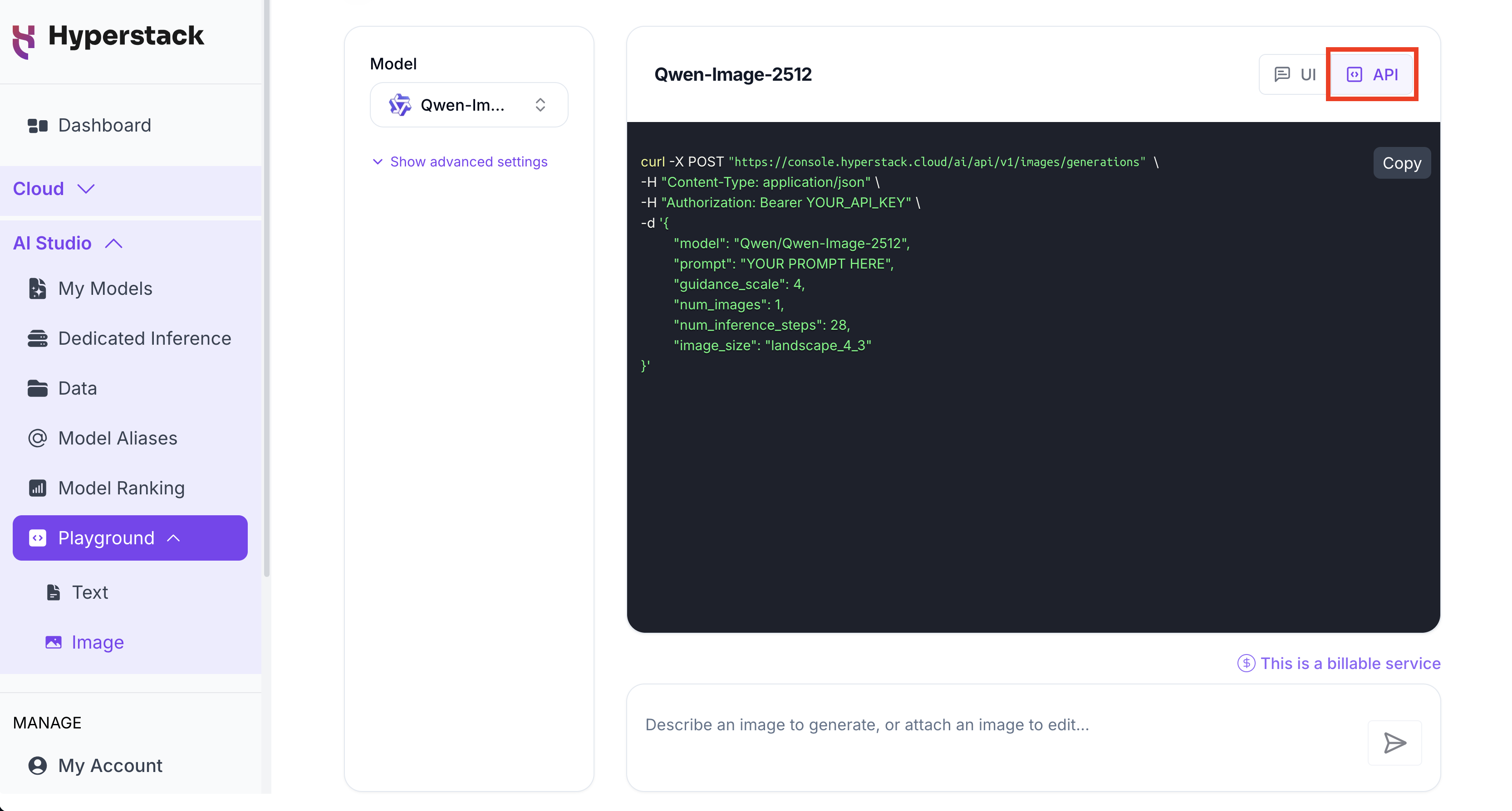
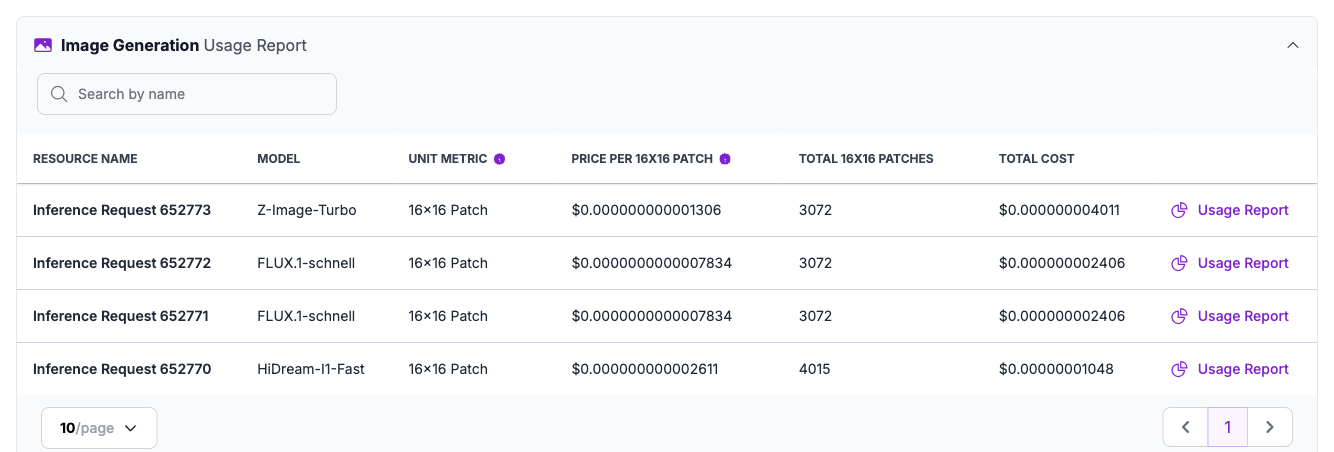
Image Generation Billing
Image generation is billed per 16x16 patch. A dedicated Image Generation Usage Report is available under Billing - Resource Activity to keep image workload costs visible and separate from compute spend.
Vision Models
A new catalog of image generation models is now available in the Model Catalog. Use it to browse and filter by modality across text-to-text, text-to-image, and image-to-image to find the right model for your workflow. You can also access the same modality filter via API using the modalities query parameter on List Base Models.
Vision Models Pricing
A new Vision Models Pricing page is now available. Use it to view pricing for text-to-image and image-to-image models in one place.
Latest Improvements
Here's what shipped this week across Kubernetes and platform reliability:
-
Kubernetes cluster resilience: Transient SSH failures during cluster creation or reconciliation no longer cause operations to fail. The platform now retries automatically, so intermittent connectivity issues no longer interrupt cluster bring-up.
-
Kubernetes cluster registry: Helm charts and container images used during cluster deployment and operations are now sourced from a Hyperstack-managed private registry, reducing external dependency risk and improving consistency across deployments.
-
Organisation member removal validation: The Remove Organisation Member API now validates that the specified member is not an organisation owner before processing the request, preventing accidental removal of owner-level accounts.
-
Snapshot-aware VM deletion: Attempting to delete a virtual machine while a snapshot is in progress is now rejected.
New on our Blog
Check out the latest tutorials and blogs on Hyperstack:
How to Optimse KV Cache:
Guide to Faster and Cheaper LLM Inference
If you run LLMs at scale, optimising the KV cache is one of the most impactful ways to reduce cost per token, extend context length, and increase batch size. Our latest guide explains what the KV cache is, why it becomes a bottleneck and practical optimisation techniques, from a one-line quantisation flag you can use today to the architectural changes behind frontier models with reproducible numbers and runnable code.

Running a Multi-Program AI Research Environment:
On Secure Private Cloud
Our case study follows a regulated AI research institute running five concurrent genomics, molecular design and bioinformatics workloads. After public cloud and on-premises setups failed to meet performance and compliance needs, the team moved to a dedicated Secure Private Cloud on Hyperstack. The blog examines the migration decision and the impact on reproducibility, compliance, and research output.
.png?width=648&height=389&name=Blog%20thumbnail%20-%201000x600%20-%201000x600%20(2).png)
Deploy Gemma Diffusion on Hyperstack:
A Step-by-Step Guide
DiffusionGemma is an open-weights, diffusion-based language model from Google DeepMind built on the 26B-A4B Gemma 4 Mixture-of-Experts architecture. Our latest tutorial shows how to deploy Google DeepMind's DiffusionGemma on Hyperstack using vLLM and a single NVIDIA H100-80G-PCIe, exposing an OpenAI-compatible API with the Entropy-Bounded diffusion sampler. Built on the Gemma 4 MoE architecture, DiffusionGemma generates text by denoising 256-token blocks in parallel, delivering over 1,000 tokens per second on a single NVIDIA H100 while supporting text, image, and video inputs.
.png?width=648&height=389&name=Blog%20thumbnail%20-%201000x600%20-%201000x600%20(1).png)
Help Shape the Future of Hyperstack
Great products are built with the people who use them. If there’s something you would like to see on Hyperstack, whether it is a new feature, workflow improvement or integration that would make your work easier, we would love to hear about it.
Your feedback helps us prioritise what matters most and build a platform that works better for the community.
That's it for this week's Hyperstack Rundown! Stay tuned for more updates next week and subscribe to our newsletter below for exclusive AI and GPU insights delivered to your inbox!
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

